CISC vs RISC
Picture two restaurants on the same block. The first is an old diner with a 200-item menu — pancakes, omelets, a turkey club, a surf-and-turf with three sides and a sauce of your choice. Some orders are one word. Some take a paragraph. The kitchen has to know every dish, and the line cook reads each ticket carefully because the next one might be a coffee or it might be a beef wellington. The second restaurant down the block is a bowl chain. Every order is a bowl. Pick a base, pick a protein, pick three toppings. Every ticket has the same shape. The line moves twice as fast. That is the whole CISC vs RISC argument in one block of pavement. The diner is x86. The bowl chain is ARM.
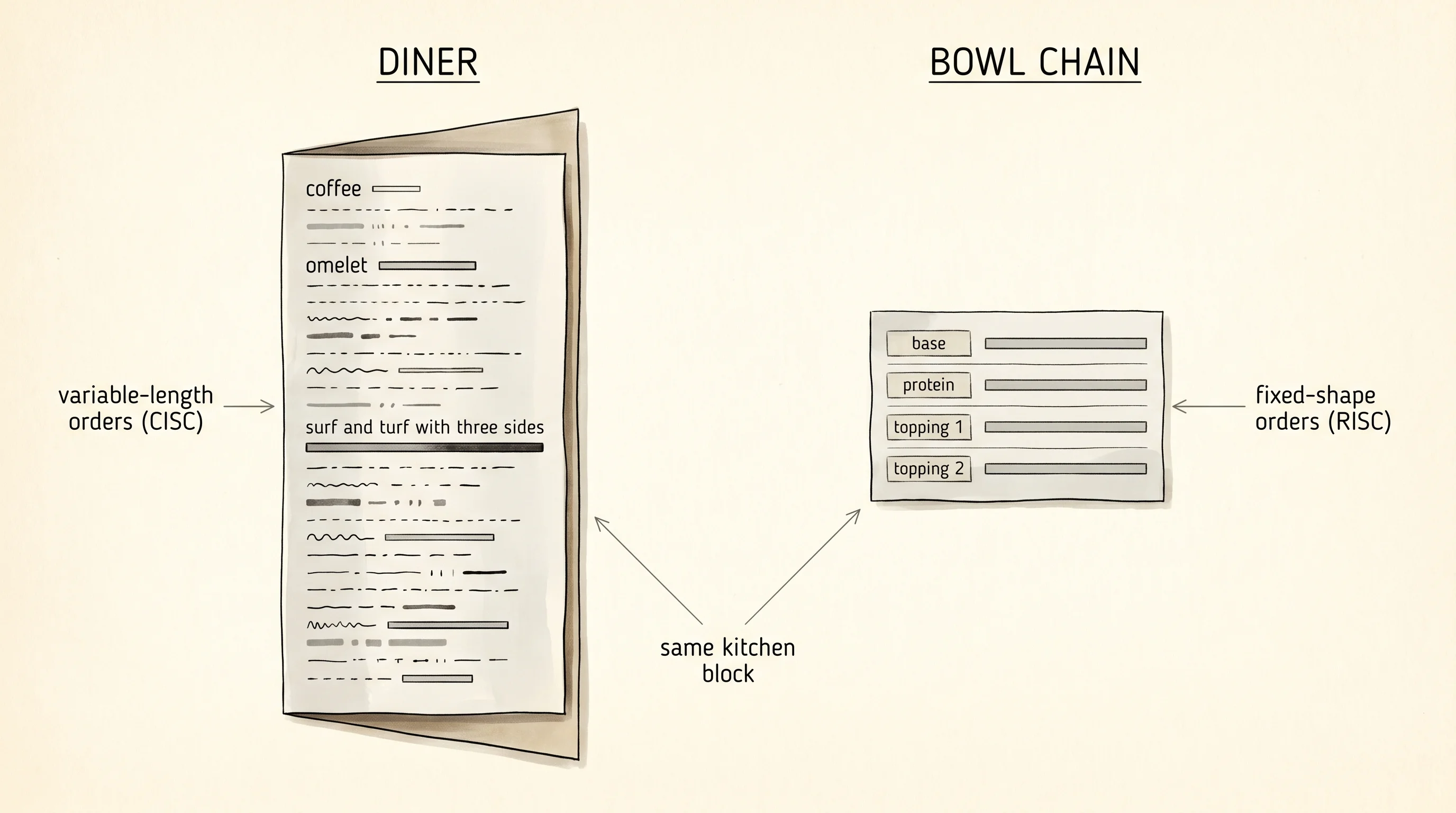
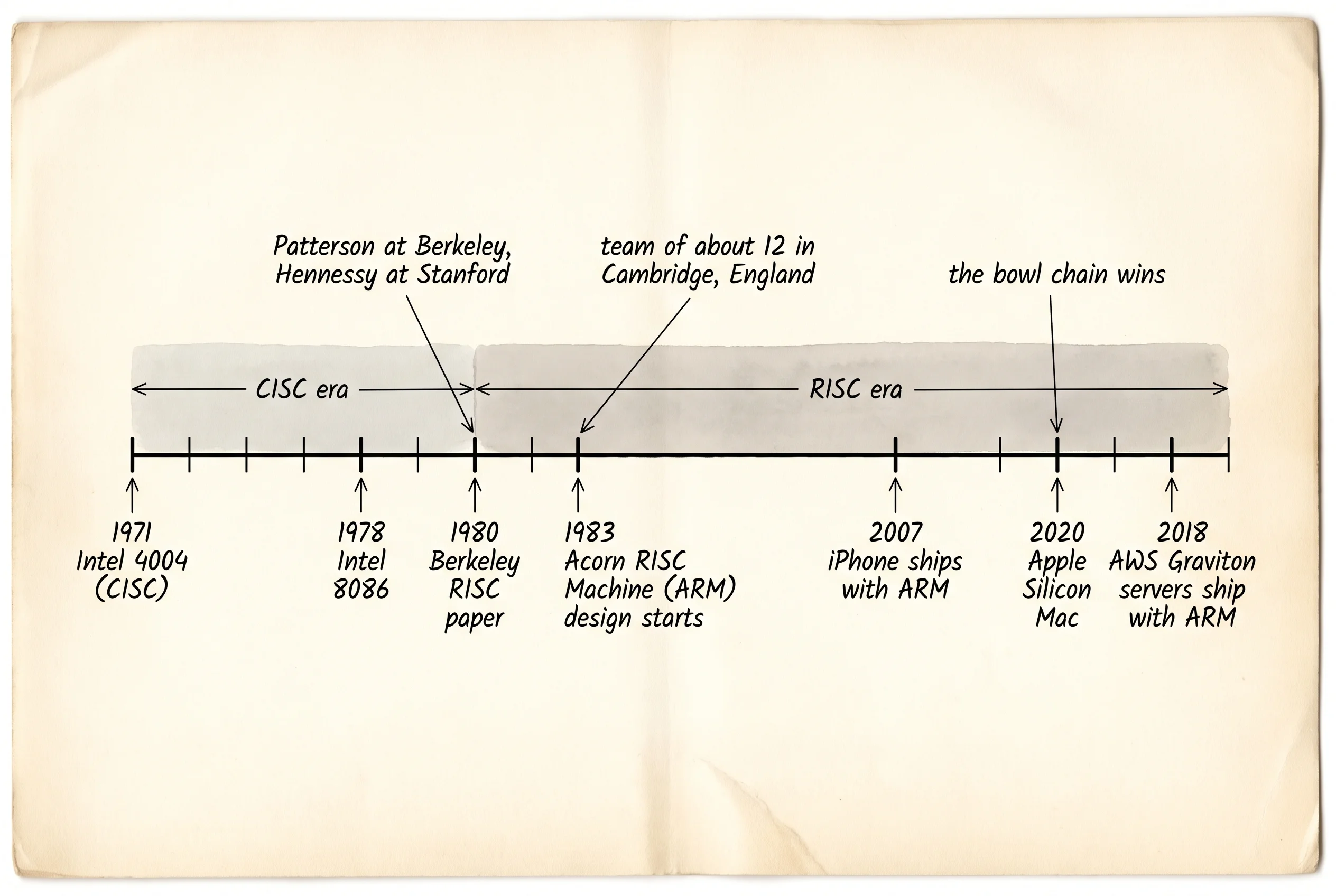
CISC stands for Complex Instruction Set Computer. The name was invented after the fact, when people needed something to push against. In the 1970s every CPU was a CISC chip because memory was expensive and slow. If the compiler could pack a whole loop into one fat instruction, the program shrank and ran faster from cassette tape or floppy disk. Intel's 8086 in 1978 had instructions that could add a number to a memory location and update a pointer at the same time. Sounded great. By 1980 it stopped sounding great. Memory got cheaper. Caches arrived. The fat instructions started looking like a kitchen full of one-off recipes that nobody ordered.
Two professors noticed this at the same time on opposite coasts. David Patterson at Berkeley counted the instructions a real C program used and found that most of them came from a small core — about 20 percent of the menu served 80 percent of the orders. The other 80 percent burned chip area on a microcode ROM that decoded the rare cases. John Hennessy at Stanford was building a different chip with the same hunch. They called the answer Reduced Instruction Set Computer. Fewer instructions. Every instruction the same size. Every instruction does one thing the hardware can finish in one clock tick. Let the compiler chain three simple steps together instead of asking the silicon for one giant one.
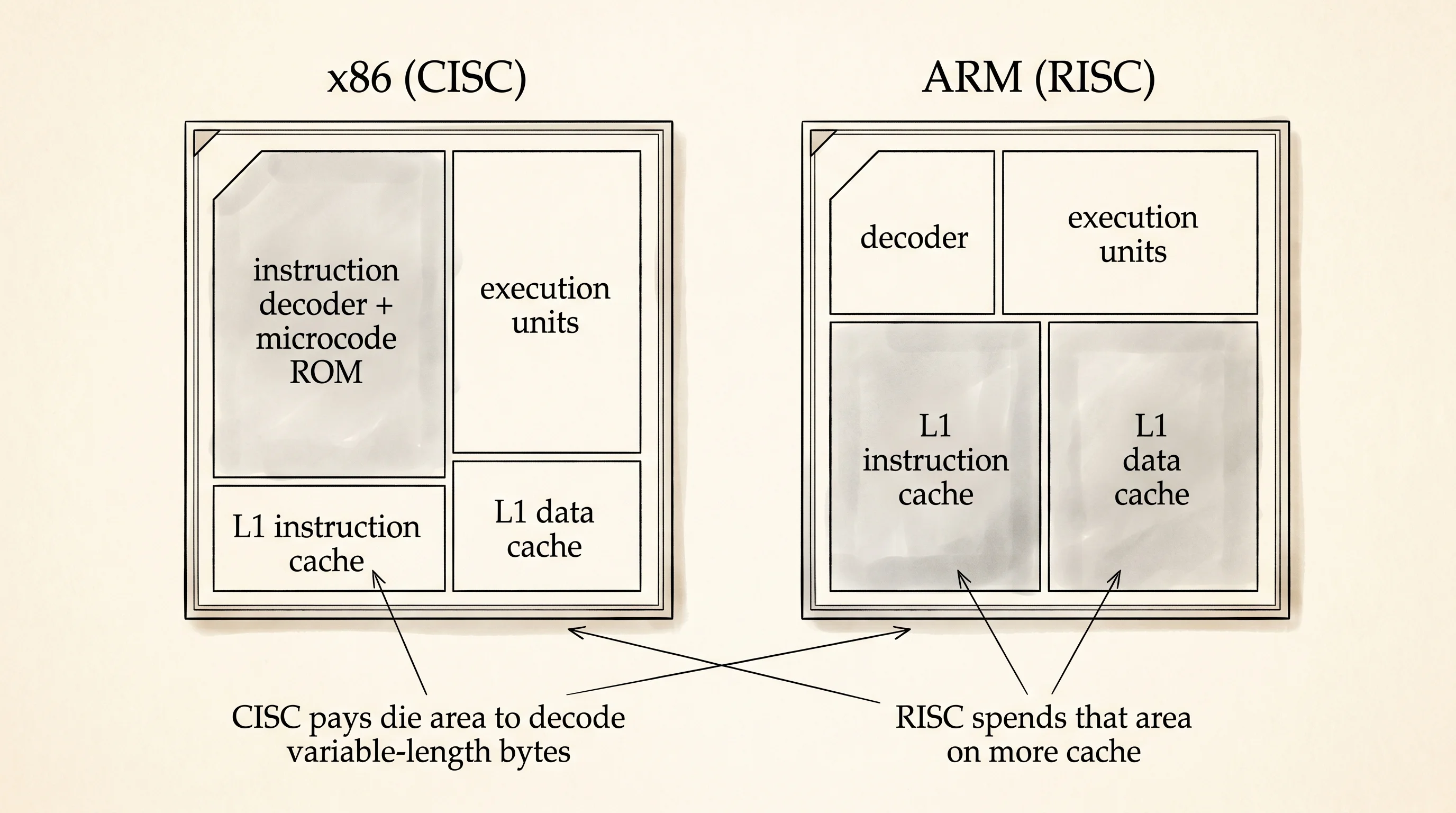
The bowl chain wins on the kitchen, not on the menu. When every instruction is exactly 4 bytes, the decoder always knows where the next instruction starts. It can fetch four at once and start decoding all four in parallel before the first one finishes. The diner cannot do that. The diner has to read the first ticket to know whether the second ticket starts after one byte or after fifteen. Modern x86 chips solve this by paying a tax — a chunk of die area called the decoder that does enormous work just to find the boundaries. The ARM chip in your phone spends that area on more cache instead.
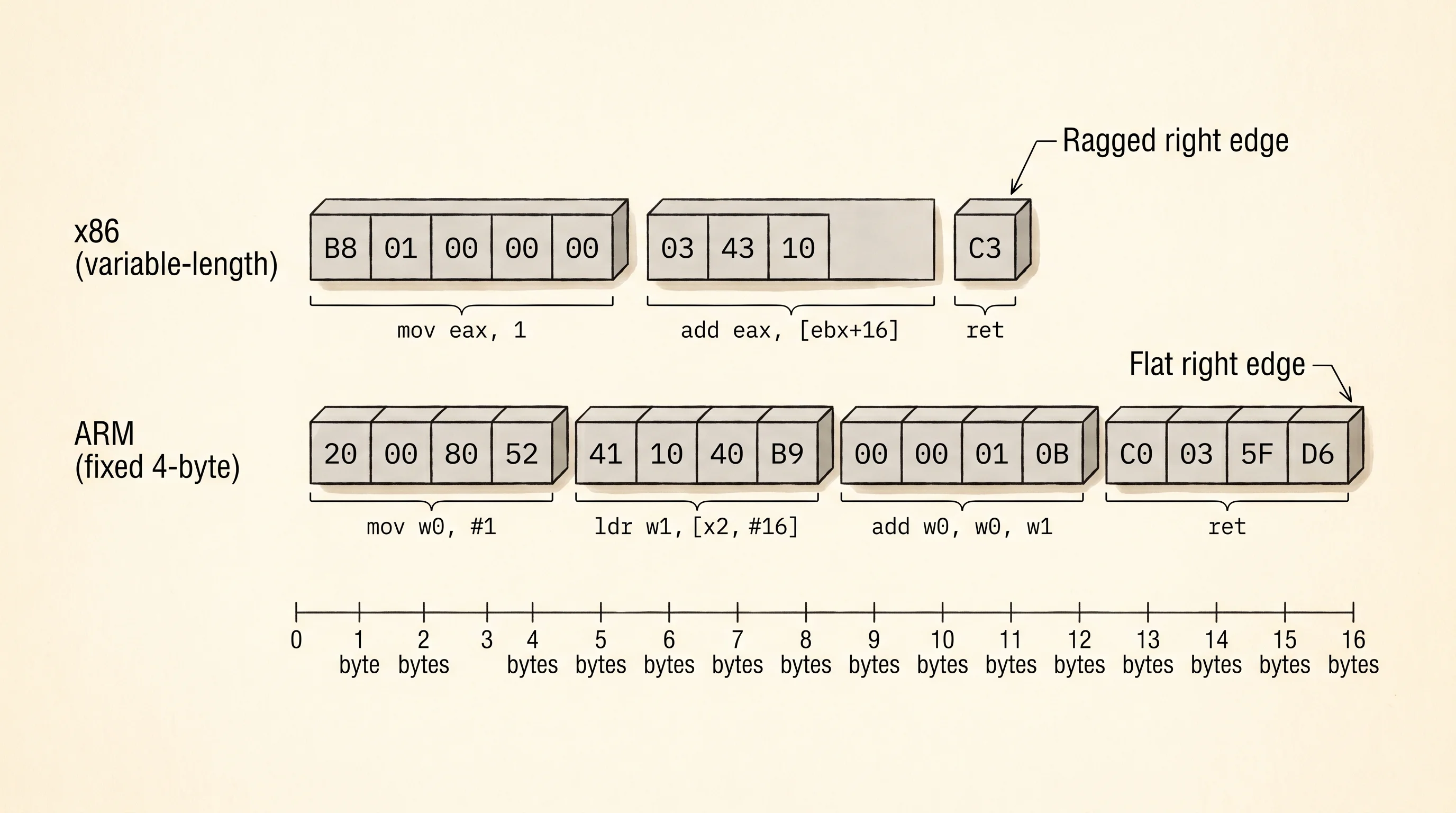
Here is the same tiny program written for both kitchens. Read an integer from memory, add 1 to it, return. Both versions do the same work. The bytes tell a different story.
struct Encoded {
mnemonic: &'static str,
bytes: &'static [u8],
}
const X86_PROGRAM: &[Encoded] = &[
Encoded { mnemonic: "mov eax, 1", bytes: &[0xB8, 0x01, 0x00, 0x00, 0x00] },
Encoded { mnemonic: "add eax, [ebx+16]", bytes: &[0x03, 0x43, 0x10] },
Encoded { mnemonic: "ret", bytes: &[0xC3] },
];
const ARM_PROGRAM: &[Encoded] = &[
Encoded { mnemonic: "mov w0, #1", bytes: &[0x20, 0x00, 0x80, 0x52] },
Encoded { mnemonic: "ldr w1, [x2, #16]", bytes: &[0x41, 0x10, 0x40, 0xB9] },
Encoded { mnemonic: "add w0, w0, w1", bytes: &[0x00, 0x00, 0x01, 0x0B] },
Encoded { mnemonic: "ret", bytes: &[0xC0, 0x03, 0x5F, 0xD6] },
];The data sits in a plain Rust array — a mnemonic for the human and a bytes slice for the silicon. The print_side function below walks the array and lays out the encoding so you can see the widths.
fn hex(bytes: &[u8]) -> String {
let mut s = String::new();
for (i, b) in bytes.iter().enumerate() {
if i > 0 {
s.push(' ');
}
s.push_str(&format!("{:02X}", b));
}
s
}
fn print_side(title: &str, program: &[Encoded]) {
println!("{}", title);
println!(" mnemonic bytes width");
println!(" -------------------- --------------------- -----");
let mut total = 0usize;
for ins in program {
println!(
" {:<20} {:<21} {} B",
ins.mnemonic,
hex(ins.bytes),
ins.bytes.len()
);
total += ins.bytes.len();
}
println!(" total bytes: {}", total);
}
fn main() {
print_side("x86 (CISC): variable-length, 1 to 15 bytes per instruction", X86_PROGRAM);
println!();
print_side("ARM (RISC): every instruction is exactly 4 bytes", ARM_PROGRAM);
println!();
println!("same idea, two contracts:");
println!(" x86 squeezes the common case into 1 byte and the rare case into 15.");
println!(" ARM pays 4 bytes for everything so the decoder never has to guess.");
}Run it and the difference shows up in one glance.
x86 (CISC): variable-length, 1 to 15 bytes per instruction
mnemonic bytes width
-------------------- --------------------- -----
mov eax, 1 B8 01 00 00 00 5 B
add eax, [ebx+16] 03 43 10 3 B
ret C3 1 B
total bytes: 9
ARM (RISC): every instruction is exactly 4 bytes
mnemonic bytes width
-------------------- --------------------- -----
mov w0, #1 20 00 80 52 4 B
ldr w1, [x2, #16] 41 10 40 B9 4 B
add w0, w0, w1 00 00 01 0B 4 B
ret C0 03 5F D6 4 B
total bytes: 16
same idea, two contracts:
x86 squeezes the common case into 1 byte and the rare case into 15.
ARM pays 4 bytes for everything so the decoder never has to guess.Count the bytes column on each side. The x86 column is 5, 3, 1 — a ragged little staircase. The ARM column is 4, 4, 4, 4 — a flat line. The x86 version uses fewer total bytes for this toy program, which is exactly the trade the 1970s designers made. They spent decoder complexity to win on code size. ARM gave up the code-size win to make the decoder simple enough to ship in a phone with a battery.
The argument went public in 1980 when Patterson wrote a paper called "The Case for the Reduced Instruction Set Computer." Intel's people pushed back. They had millions of chips in the field running DOS, and every one of them had to keep working forever. A company called Acorn Computer in Cambridge, England, read the Berkeley paper, decided the argument was right, and started designing a tiny RISC chip in 1983 with a team of about a dozen engineers. They called it the Acorn RISC Machine. Three letters: ARM. Forty years later that chip's descendants run every iPhone, every Apple laptop since 2020, and an enormous slice of AWS's server fleet. The bowl chain ate the diner's lunch.
The win was not free. RISC code is bigger because each step is its own instruction, and a 4-byte instruction that does a little thing wastes bytes when a 1-byte instruction would do. RISC programs lean harder on the instruction cache, which is why ARM chips put so much die area into cache. RISC compilers also have to work harder, because they have to pick the right sequence of small instructions for every operation instead of asking the chip for one big one. That last cost is paid once, by the compiler team. The decoder savings are paid back every clock cycle of every chip ever shipped.
What the encoding diagram cannot show is what comes next — the moment the compiler has to actually emit different bytes from the same Rust source depending on whether you target ARM or x86, which is what the cross-compile lesson does.