Hash Maps from Scratch
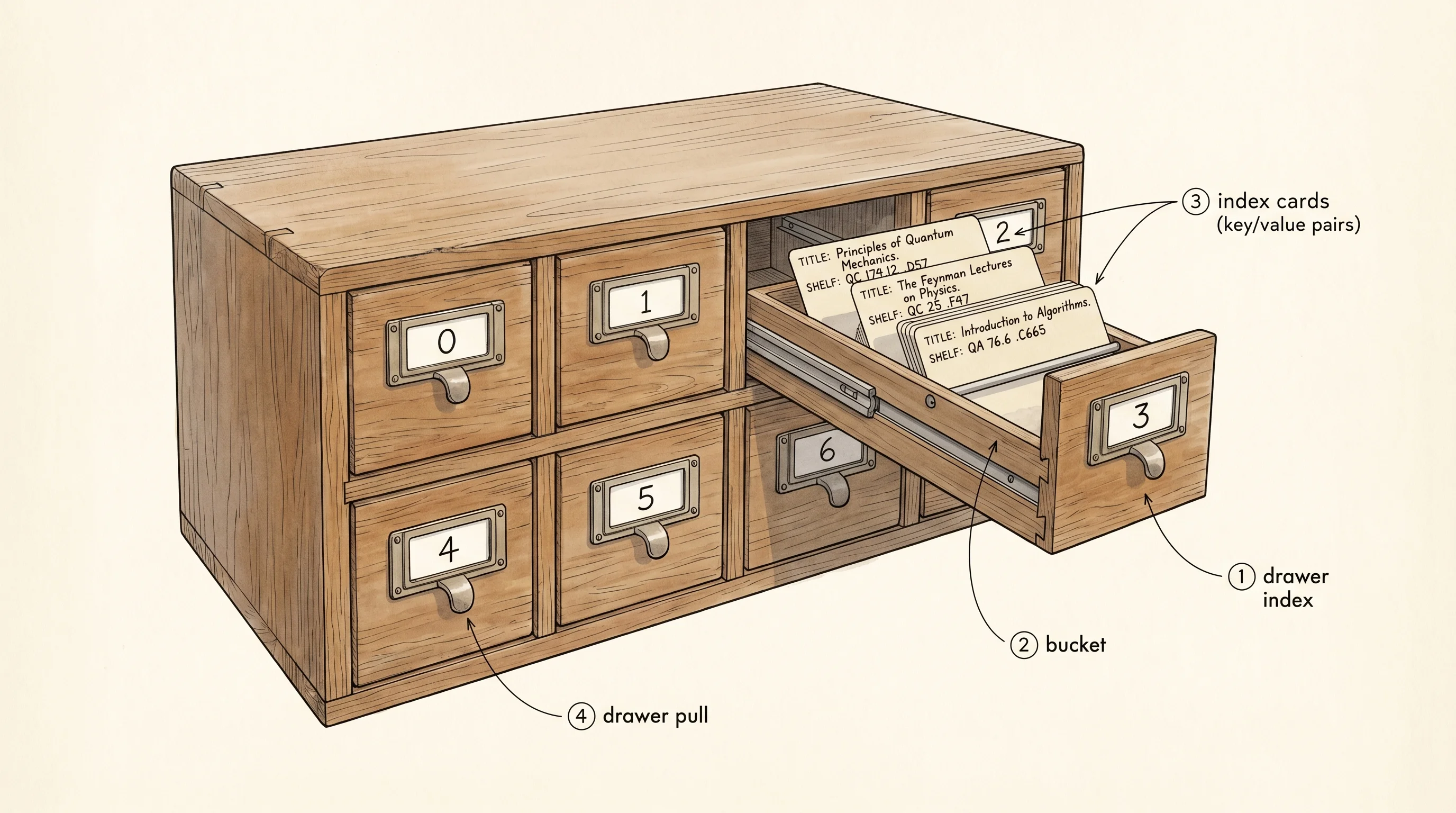
A hash map is the card catalog at a library. The catalog is a tall wooden cabinet full of small drawers. Each drawer holds a stack of index cards. Every card has a book title on the front and a shelf number on the back. To find a book, you do not flip through every drawer — you follow a rule that turns the title into a drawer number, walk straight to that drawer, and read down the small stack of cards inside. Most drawers hold one or two cards. A few hold three or four. The whole point is that the trip from "title" to "shelf number" takes the same tiny amount of work no matter how many books the library owns.
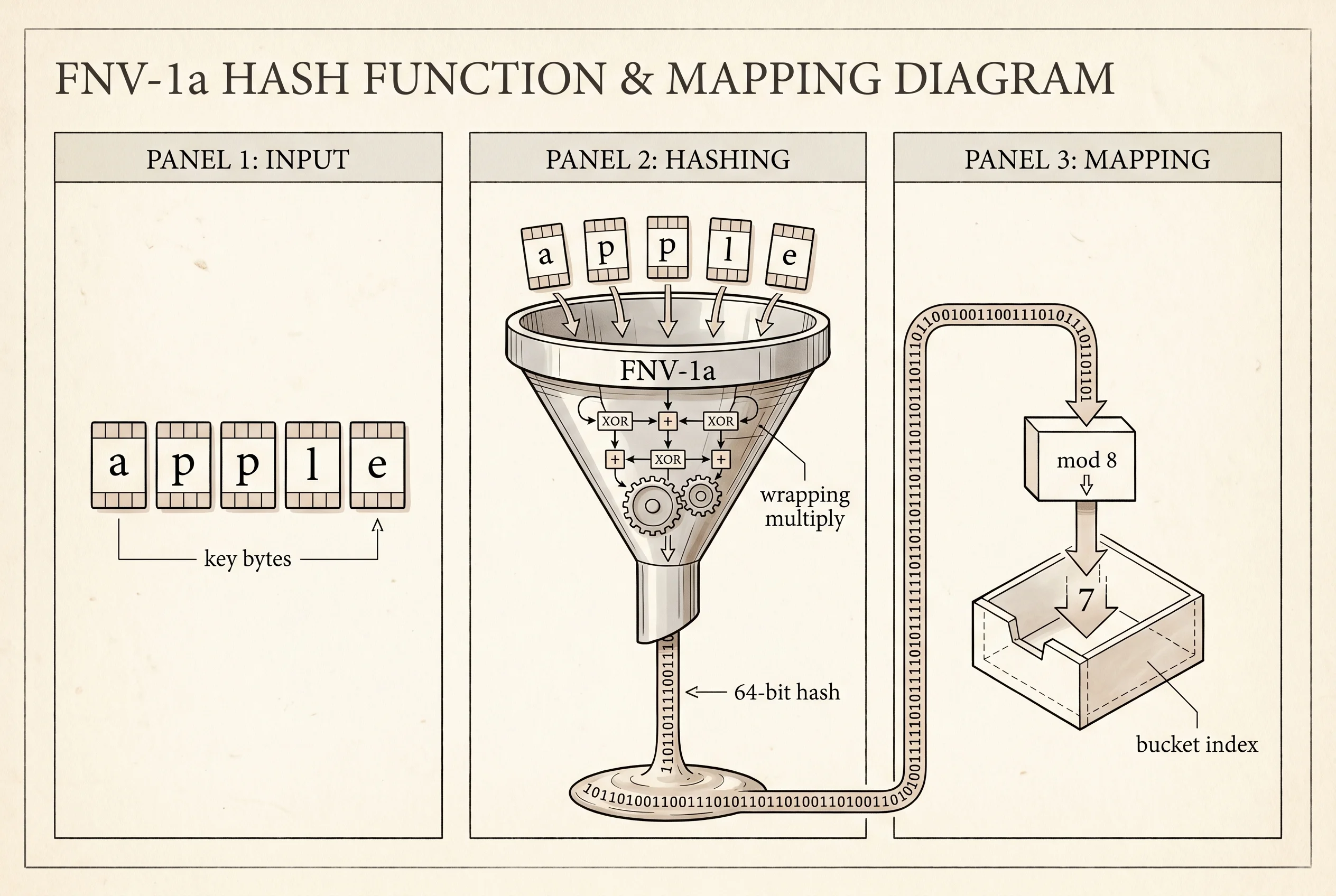
The rule that turns a title into a drawer number is called a hash function. It is the heart of the whole structure, and it has a strange history. Hans Peter Luhn was a textile engineer turned IBM researcher who wrote an internal memo in 1953 describing what we now call hashing. The bottleneck he was trying to fix was painful: punch-card systems at the time looked up records by walking through long sorted lists, and the walk got slower as the file grew. Luhn's idea was to spend a few microseconds chopping the key into a small fixed-size number — the drawer number — and use that number as a direct address. The lookup became one step instead of thousands. A few years later, Arnold Dumey wrote the idea up for the open literature, and the term "hash" — meaning "chop into a mess" — stuck because that is exactly what a good hash function does to the bytes of the key.
A good hash function has two jobs. It has to be fast, and it has to scatter keys evenly across the drawers so no one drawer gets stuffed. The one we will use is called FNV-1a, designed in 1991 by Glenn Fowler, Landon Curt Noll, and Phong Vo. They picked two magic numbers — a 64-bit starting value called the offset basis, and a 64-bit prime called the FNV prime — and the entire algorithm is "walk the bytes of the key, XOR each byte into the running hash, multiply by the prime." That is it. The whole hash function fits in eight lines of Rust.
const FNV_OFFSET: u64 = 0xcbf2_9ce4_8422_2325;
const FNV_PRIME: u64 = 0x0000_0100_0000_01b3;
fn fnv1a(key: &str) -> u64 {
let mut hash = FNV_OFFSET;
for byte in key.as_bytes() {
hash ^= u64::from(*byte);
hash = hash.wrapping_mul(FNV_PRIME);
}
hash
}The wrapping_mul is doing real work. Multiplying a 64-bit number by a prime almost always overflows. In C the overflow is silent. In Rust, integer overflow panics in debug mode by default — the language is trying to protect you from a bug. Here we want the overflow because the wraparound is what spreads the bits around. Calling wrapping_mul tells the compiler "I know it overflows, that is the point, please give me the low 64 bits and move on." Run the function on the string apple and you get a 64-bit number that looks like noise. Run it on apply and the result has no visible relationship to the first one. That is the scatter we want.
The cabinet itself is a Vec<Vec<(String, V)>>. Read that type slowly. The outer Vec is the row of drawers. Each drawer is its own little Vec holding pairs of a key and a value. When two keys hash to the same drawer — which will happen, because we have many possible keys and only a few drawers — both pairs sit in the same little vector, one after the other. This trick is called separate chaining, and it dates back to the very first hash tables built at IBM in the 1950s. The other option, called open addressing, walks to the next empty drawer when there is a clash. Separate chaining is the version that is easiest to picture and easiest to reason about, which is why almost every textbook starts here.
struct MyHashMap<V> {
buckets: Vec<Vec<(String, V)>>,
}
impl<V: Copy> MyHashMap<V> {
fn with_buckets(n: usize) -> Self {
let mut buckets = Vec::with_capacity(n);
for _ in 0..n {
buckets.push(Vec::new());
}
Self { buckets }
}
fn index_for(&self, key: &str) -> usize {
(fnv1a(key) as usize) % self.buckets.len()
}
fn insert(&mut self, key: &str, value: V) {
let idx = self.index_for(key);
let bucket = &mut self.buckets[idx];
for slot in bucket.iter_mut() {
if slot.0 == key {
slot.1 = value;
return;
}
}
bucket.push((key.to_string(), value));
}
fn get(&self, key: &str) -> Option<V> {
let idx = self.index_for(key);
for slot in &self.buckets[idx] {
if slot.0 == key {
return Some(slot.1);
}
}
None
}
}insert does the obvious thing. It hashes the key, takes the result modulo the number of buckets to fold the 64-bit number down to a real drawer index, then walks the little vector to see if the key is already there. If it is, the value gets overwritten. If not, the new pair is pushed onto the end. get is the mirror image — same hash, same modulo, same walk, but it returns the value instead of writing one. The bound V: Copy is there to keep this lesson short — it lets get return Some(v) without worrying about ownership. A real hash map would return Option<&V> or Option<&mut V> so it could hold strings, vectors, anything. The shape is the same.
There is one rule for the lesson that matters more than it looks. We never iterate std::collections::HashMap directly when we want to print something. The standard library uses a hash called SipHash, and it picks a fresh secret key per program run on purpose, so two runs of the same program visit the buckets in a different order. That is a deliberate defense against an attack that Dan Bernstein wrote up in 2003 — if a server's hash function is predictable, a malicious user can craft keys that all collide into one bucket and turn every lookup into a slow walk. Randomizing the hash kills the attack but makes the output of any iteration look different every time you run it. Our MyHashMap uses FNV-1a, which is deterministic, so the same five keys land in the same five drawers on every machine. That is what makes the snapshot at the bottom of this page real.
The demo inserts five fruit names into a cabinet with eight drawers, prints which drawer each one ended up in, then dumps the whole cabinet drawer by drawer, then asks for four keys — three that exist and one that does not.
fn print_layout<V: std::fmt::Display>(map: &MyHashMap<V>) {
for (i, bucket) in map.buckets.iter().enumerate() {
print!("bucket {i}:");
if bucket.is_empty() {
println!(" (empty)");
} else {
for (k, v) in bucket {
print!(" [{k}={v}]");
}
println!();
}
}
}
fn main() {
let pairs = [
("apple", 1),
("grape", 2),
("mango", 3),
("peach", 4),
("lemon", 5),
];
let mut map: MyHashMap<i32> = MyHashMap::with_buckets(8);
for (k, v) in pairs {
map.insert(k, v);
println!("insert {k}={v} -> bucket {}", map.index_for(k));
}
println!();
print_layout(&map);
println!();
for k in ["apple", "mango", "lemon", "kiwi"] {
match map.get(k) {
Some(v) => println!("get {k} -> {v}"),
None => println!("get {k} -> miss"),
}
}
}Run it.
insert apple=1 -> bucket 7
insert grape=2 -> bucket 0
insert mango=3 -> bucket 5
insert peach=4 -> bucket 6
insert lemon=5 -> bucket 0
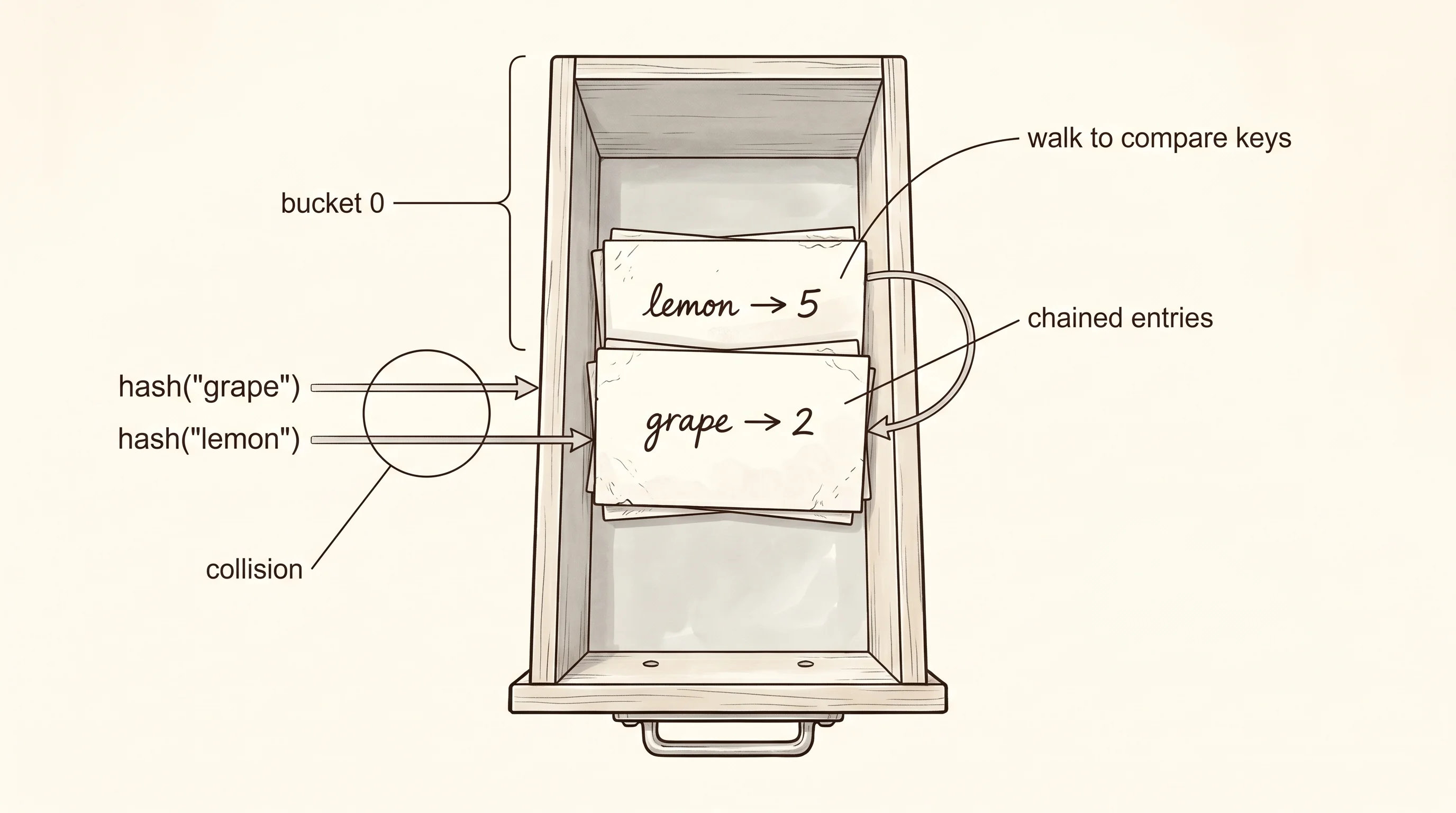
bucket 0: [grape=2] [lemon=5]
bucket 1: (empty)
bucket 2: (empty)
bucket 3: (empty)
bucket 4: (empty)
bucket 5: [mango=3]
bucket 6: [peach=4]
bucket 7: [apple=1]
get apple -> 1
get mango -> 3
get lemon -> 5
get kiwi -> missLook at bucket 0. Both grape and lemon ended up in the same drawer. That is a collision, and it is exactly what separate chaining handles — the drawer holds a tiny stack of two cards. When get asks for lemon, it hashes the key, finds drawer 0, walks the two cards, compares the keys with ==, and returns the second one. The walk is two steps long instead of one. With five keys and eight drawers, one collision is normal. With fifty keys and eight drawers, every drawer would hold six or seven cards and lookups would crawl. Real hash maps watch the average drawer depth — called the load factor — and when it gets above about 0.75, they allocate a bigger cabinet and rehash every key into the new drawers. We did not build that here, but you can picture how it would work.
Why did kiwi come back as a miss? The hash sent it to some drawer, the drawer was walked, and no card with the key kiwi was found. The lookup is still constant time on average — it does the same work whether the answer is hit or miss, and it cannot lie about a key being there when it is not.
A real card catalog has one weakness, and so does our hash map. The cabinet has a fixed number of drawers, picked when we built it. Cram too many cards in and every drawer becomes a long stack, and the trip from title to shelf number turns into a walk again. The next lesson moves to trees, where the cabinet grows and rebalances itself as you add to it, paying a logarithmic price per lookup in exchange for never letting any one drawer get out of hand.