Strings vs &str
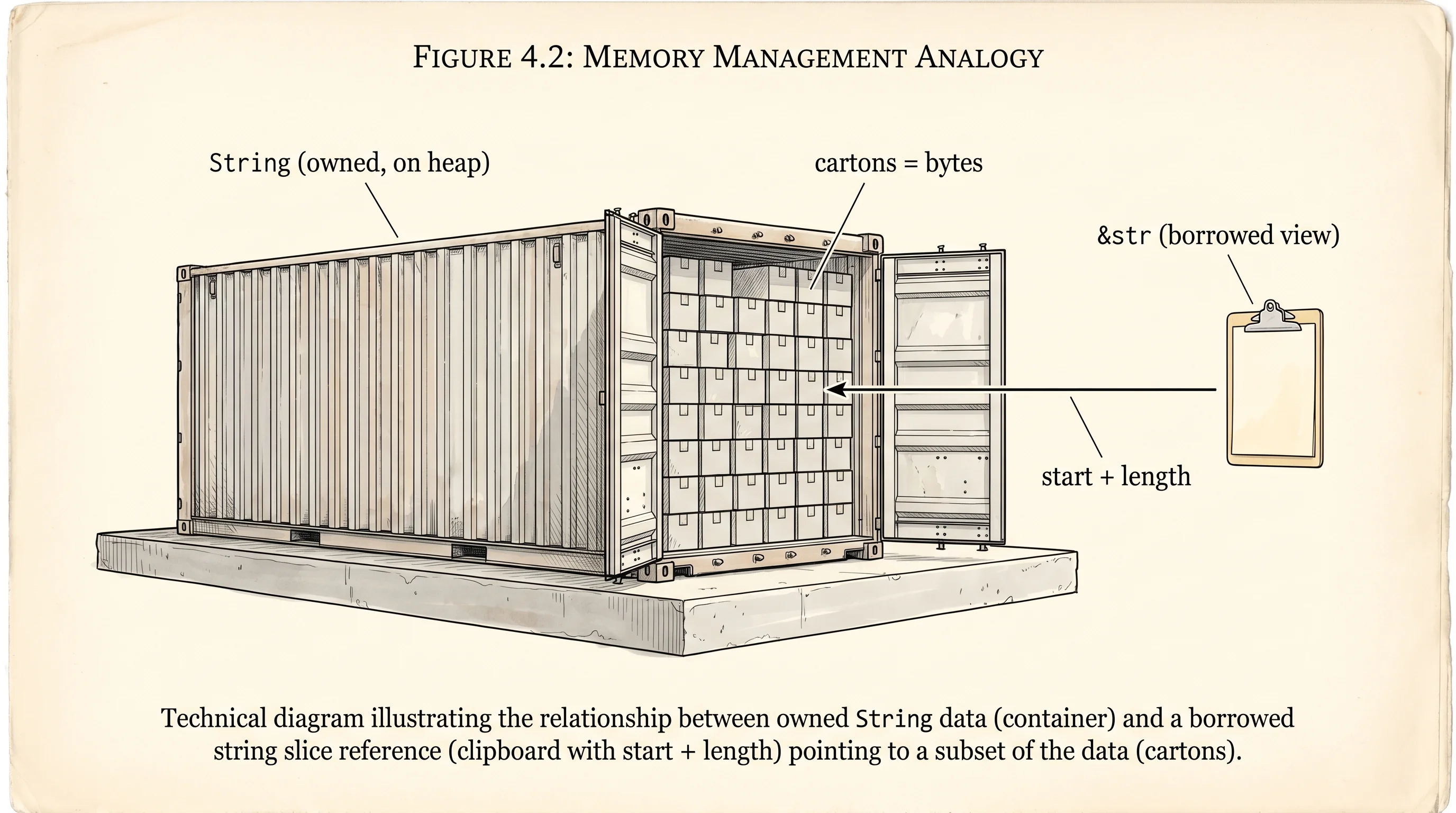
A Rust string is a shipping container at the Port of Long Beach. You own the container — you can stack new cartons inside, you can crack the doors open and read what is in there, you can lock it and ship it out. That is String. A &str is a clipboard the dockworker walks around with that says "look at boxes 47 through 102 in container A-9." The clipboard does not own the cargo. The container still belongs to whoever rented the slot. Two words for two jobs — one for the thing that holds bytes, one for the borrowed window you read them through. Once you see why Rust split the job in two, every weird string error in the language stops being weird.
The split happened on purpose, and it happened because of how computers used to lie about text. In 1992 a German engineer at Xerox named Joe Becker and a Swiss engineer named Mark Davis were trying to fix a real disaster — every language on Earth had its own character encoding, so a Japanese filename emailed to a French office turned into garbage. They proposed Unicode, a single table that assigned every letter, character, and symbol in every script a unique number called a code point. By 1993 the IETF was arguing about how to actually pack those numbers into bytes. Two Bell Labs engineers, Ken Thompson and Rob Pike, sat down at a New Jersey diner one September night and sketched UTF-8 on a placemat — a clever rule where the most common characters (ASCII) take 1 byte, and rarer characters take 2, 3, or 4 bytes that all start with a recognizable header. By the time Graydon Hoare started Rust at Mozilla in 2006, the lesson was clear — a modern language must be UTF-8 native, but UTF-8 means a string is no longer just a row of equal-sized boxes. So Rust made the container and the clipboard two different types.
Here is the smallest version of the split. One String you build at runtime on the heap, one &str borrowed from it, one &'static str baked into the binary at compile time.
let owned: String = String::from("cafe");
let borrowed: &str = &owned;
let literal: &'static str = "yard";
println!("owned -> {owned} (len {} bytes, on the heap)", owned.len());
println!("borrowed -> {borrowed} (a window into owned, no copy)");
println!("literal -> {literal} (baked into the binary, lives forever)");Run it and you see what each word actually holds.
owned -> cafe (len 4 bytes, on the heap)
borrowed -> cafe (a window into owned, no copy)
literal -> yard (baked into the binary, lives forever)
grew the container: café JP
sample : café
bytes : 63 61 66 65 cc 81
chars : [c] [a] [f] [e] [́]
graphs : [c] [a] [f] [é]
phrase : shipping yard
head 0..8 -> shipping
tail 9.. -> yard
string : ñ JP
bytes : 6
chars : 5
graphs : 4The owned container can grow. The borrowed clipboard cannot — it only describes what is already there. Add a push and a push_str to the container and the bytes go in.
let mut yard = String::from("cafe");
yard.push('\u{0301}'); // combining acute glues onto the previous 'e'
yard.push_str(" JP");
println!();
println!("grew the container: {yard}");Notice the '\u{0301}' — that is a combining acute accent. It does not stand on its own. It glues onto the previous letter. The container accepts those bytes without complaint, because to the container they are just bytes. The interesting question is what counts as a "letter" once those bytes are in there. Which brings us to the part that breaks every other language's string library.
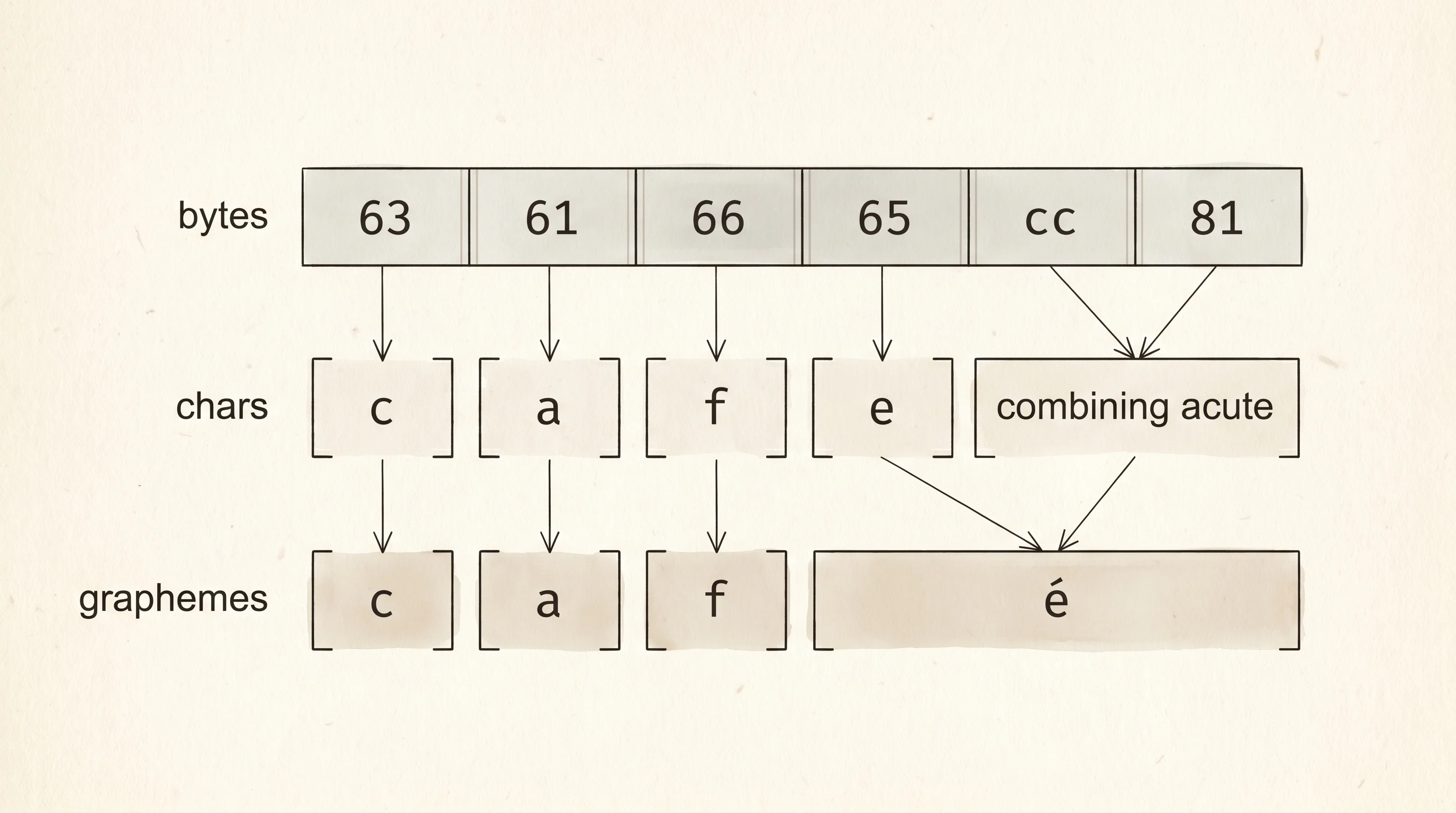
Look at the word café written with that combining accent. It is six bytes long but you only see four shapes on the screen. Rust gives you three different ways to walk through it, and they each see something different.
let sample = "cafe\u{0301}";
println!();
println!("sample : {sample}");
print!("bytes :");
for b in sample.bytes() {
print!(" {b:02x}");
}
println!();
print!("chars :");
for c in sample.chars() {
print!(" [{c}]");
}
println!();
print!("graphs :");
for g in sample.graphemes(true) {
print!(" [{g}]");
}
println!();The byte view sees the raw cargo — 63 61 66 65 cc 81. The first four bytes are ASCII for c, a, f, e. The last two bytes (cc 81) are the UTF-8 encoding of the combining acute. The char view groups those bytes into code points — five of them, because the accent counts as its own code point even though it lands visually on the e. The grapheme view groups code points into what a human reads as one letter — four, because the e and the accent together render as é. Same six bytes, three honest answers, depending on which question you asked.
owned -> cafe (len 4 bytes, on the heap)
borrowed -> cafe (a window into owned, no copy)
literal -> yard (baked into the binary, lives forever)
grew the container: café JP
sample : café
bytes : 63 61 66 65 cc 81
chars : [c] [a] [f] [e] [́]
graphs : [c] [a] [f] [é]
phrase : shipping yard
head 0..8 -> shipping
tail 9.. -> yard
string : ñ JP
bytes : 6
chars : 5
graphs : 4The clipboard idea is what makes slicing cheap. You can carve a window out of a String and Rust hands you a &str that points at the same bytes — no copy, no new allocation, just a start and a length. Standard library functions take &str everywhere for exactly this reason. You pass the clipboard, never the container, so the same String can be inspected by ten functions and the bytes never move.
let phrase = String::from("shipping yard");
let head: &str = &phrase[..8];
let tail: &str = &phrase[9..];
println!();
println!("phrase : {phrase}");
println!("head 0..8 -> {head}");
println!("tail 9.. -> {tail}");One thing the slicing rule will not let you do — cut in the middle of a multi-byte character. The compiler does not check this, but Rust panics at runtime if you try. &"café"[0..5] would split the é in half and leave a half-character behind, so Rust refuses. The clipboard has to land on a character boundary, every time. That rule is what saved Rust from the bug-class that haunts Python and JavaScript, where s[5] happily returns broken UTF-8 and you find out three log lines later.
So how many "characters" is in a string? The honest answer is "which definition?" Run the last block and watch the three numbers disagree.
let mixed = "n\u{0303} JP";
println!();
println!("string : {mixed}");
println!("bytes : {}", mixed.len());
println!("chars : {}", mixed.chars().count());
println!("graphs : {}", mixed.graphemes(true).count());owned -> cafe (len 4 bytes, on the heap)
borrowed -> cafe (a window into owned, no copy)
literal -> yard (baked into the binary, lives forever)
grew the container: café JP
sample : café
bytes : 63 61 66 65 cc 81
chars : [c] [a] [f] [e] [́]
graphs : [c] [a] [f] [é]
phrase : shipping yard
head 0..8 -> shipping
tail 9.. -> yard
string : ñ JP
bytes : 6
chars : 5
graphs : 4Six bytes, five chars, four graphemes — same string, three answers. When you ship a function that takes a &str and the docs say "max length 10," you have to say which one of the three. Most input boxes in the world should mean graphemes, because that is what the user counts as they type. Most network protocols mean bytes, because that is what fits in the packet. The compiler will not pick for you, which is the point — Rust forces you to know which one you mean instead of letting the bug compile.
Next lesson — what happens when you start passing these containers around between functions, who is allowed to write to them, and why the compiler will yell at you for moves you did not even know you were making.