What Is a Database
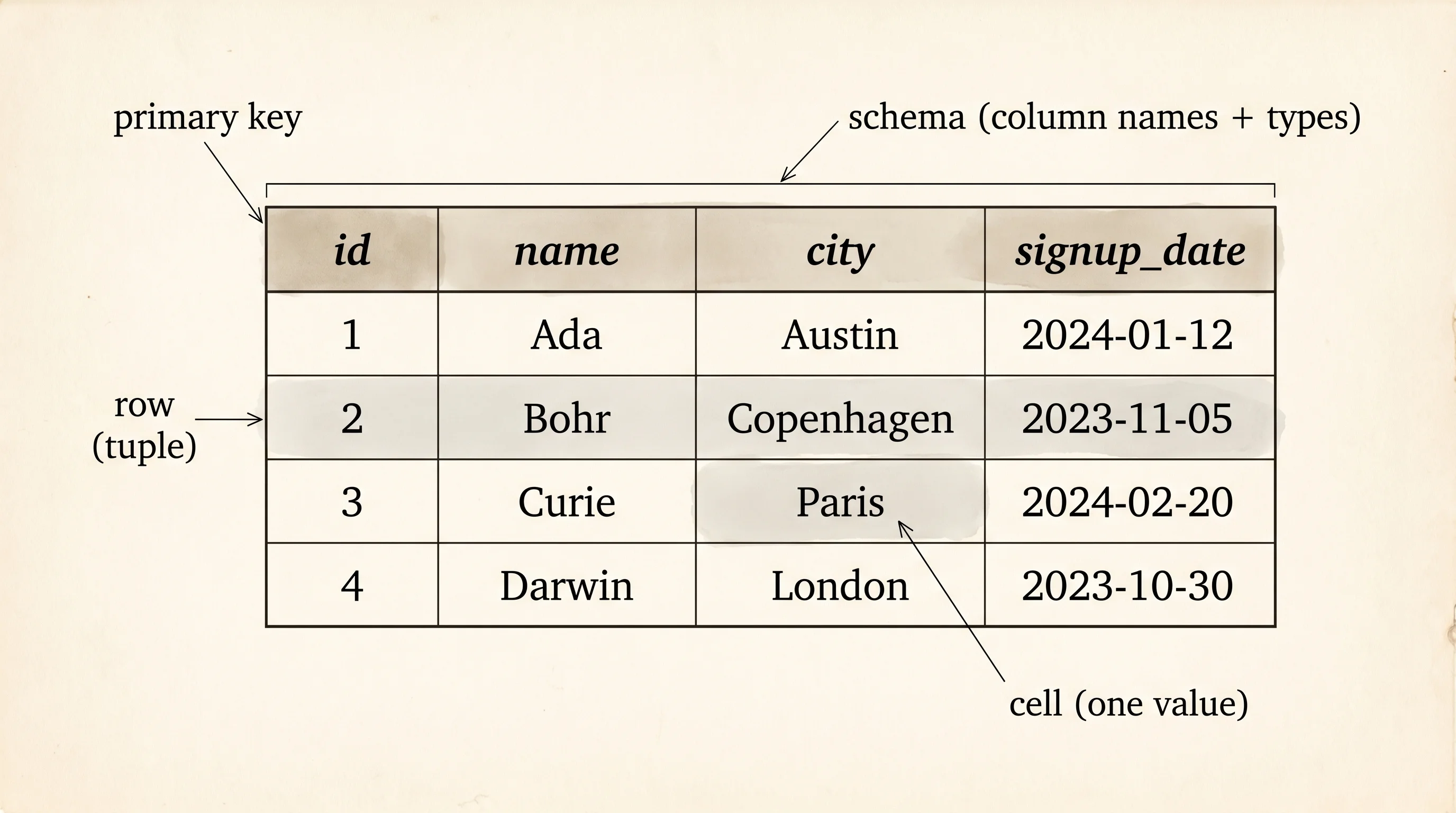
A database is a filing cabinet that never forgets, never loses a folder, and lets twenty people pull from it at the same time without bumping into each other. The cabinet has drawers, the drawers hold folders, the folders hold sheets of paper, and every sheet has the same columns printed across the top. Pull a folder, the sheet is shaped the way the cabinet promised it would be. Slide a new sheet in, the cabinet checks it against the form and refuses the ones that don't fit. The drawers are tables, the folders are rows, the printed columns are the schema, and the part that refuses bad sheets is what separates a database from a pile of text files.
The cabinet has a history. Edgar F. Codd, a British mathematician at IBM, wrote a paper in 1970 called "A Relational Model of Data for Large Shared Data Banks." Before Codd, the databases of the day stored records in a tree or a navigation graph, and to find anything you had to know the path the original programmer used to put it there. Change the path and every program that read the data broke. Codd's argument was that data is just rows in tables, and asking a question of the data should be a mathematical operation on the tables — not a walk through somebody else's pointers. IBM took eight years to ship a product on the idea, a small Oakland startup named Relational Software shipped one first in 1979 and later renamed itself Oracle, and the relational model has run the world's record-keeping ever since.
The drawer label is the table name. The printed header is the schema. Declare them before the cabinet will accept a single sheet.
type TableName = String;
type Row = Vec<String>;
struct Table {
columns: Vec<String>,
rows: Vec<Row>,
// index from a primary-key string to the row's position in `rows`
pk_index: HashMap<String, usize>,
}
struct Database {
tables: HashMap<TableName, Table>,
}
impl Database {
fn new() -> Self {
Self {
tables: HashMap::new(),
}
}
fn create_table(&mut self, name: &str, columns: &[&str]) {
let table = Table {
columns: columns.iter().map(|c| c.to_string()).collect(),
rows: Vec::new(),
pk_index: HashMap::new(),
};
self.tables.insert(name.to_string(), table);
}
}A Table here is a list of column names and a list of rows. A row is a list of strings, one per column, in the same order as the header. The Database is a map from a table name to its table. Real databases store typed values — integers, dates, booleans — and the schema pins the type per column. Pinning types matters because a column that is sometimes a number and sometimes the string "n/a" is the bug that ate the afternoon. The cabinet should refuse the mixed sheet at the door, not three weeks later when the report run blows up.
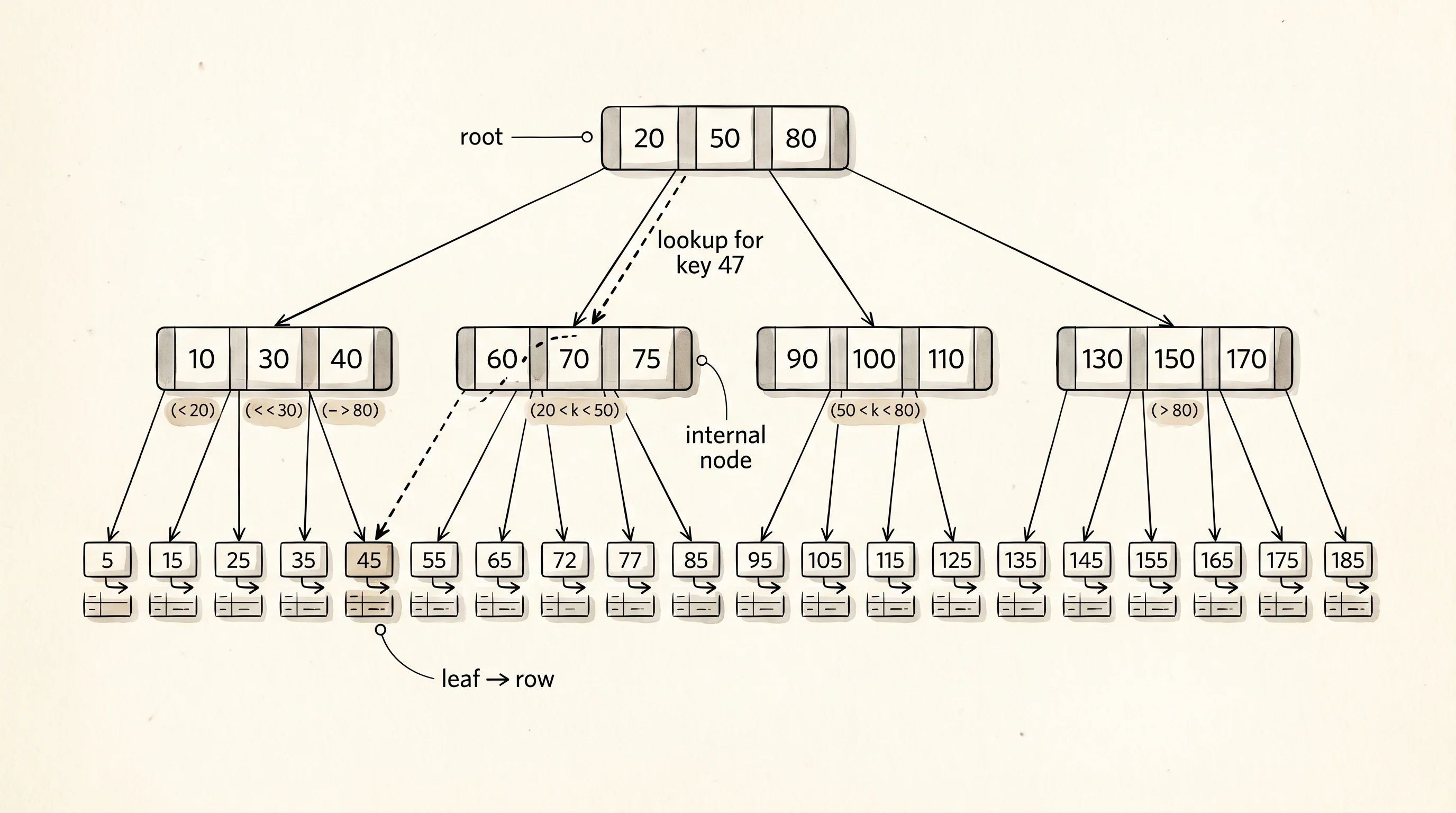
The pk_index field next to the rows is the index — a small extra map from a primary-key string to the position of the row in the list. The index is the card catalog at the front of the cabinet. Without it, finding the row with id 5 means flipping through every sheet in the drawer. With it, the cabinet reads the card, jumps straight to the right folder, and hands it over. Same data, two ways to find it, and the index is the difference between a query that returns instantly and one that scans a million rows.
Inserting a row is the cabinet checking the sheet against the printed header before accepting it.
impl Database {
fn insert(&mut self, name: &str, values: &[&str]) -> Result<(), &'static str> {
let table = self.tables.get_mut(name).ok_or("no such table")?;
if values.len() != table.columns.len() {
return Err("wrong column count");
}
let row: Row = values.iter().map(|v| v.to_string()).collect();
let pk = row[0].clone();
if table.pk_index.contains_key(&pk) {
return Err("duplicate primary key");
}
let row_idx = table.rows.len();
table.rows.push(row);
table.pk_index.insert(pk, row_idx);
Ok(())
}
}Three checks happen before a single byte is written. The table has to exist. The number of values has to match the number of columns. The primary key has to not already be in the index. Skip any of these and the cabinet starts swallowing bad data, which is the moment a database stops being useful. The third check — duplicate primary key — is the cabinet's promise that every row is uniquely addressable. If two rows can share an id, the index has to point at one of them and the other is invisible to half the queries that touch the table.
Selecting rows is the cabinet flipping through folders looking for the ones that match. The simplest version is a full scan with a filter.
impl Database {
fn select_where(&self, name: &str, column: &str, equals: &str) -> Vec<Row> {
let table = match self.tables.get(name) {
Some(t) => t,
None => return Vec::new(),
};
let col_idx = match table.columns.iter().position(|c| c == column) {
Some(i) => i,
None => return Vec::new(),
};
let mut hits = Vec::new();
for row in &table.rows {
if row[col_idx] == equals {
hits.push(row.clone());
}
}
hits
}
fn find_by_pk(&self, name: &str, pk: &str) -> Option<Row> {
let table = self.tables.get(name)?;
let idx = table.pk_index.get(pk)?;
Some(table.rows[*idx].clone())
}
}select_where walks every row and keeps the ones whose value in a named column equals the query. A full scan is fine for a small drawer. For a drawer of a million sheets it is the difference between coffee in hand and coffee gone cold. The index lookup at the bottom — find_by_pk — skips the scan entirely. It asks the card catalog where row 3 lives, the catalog hands back position 2, and the function returns the row in a single jump. This is the entire reason indexes exist. Real databases build their indexes as B-trees rather than hash maps so they can answer range questions too — every row with an id between 100 and 200 — but the principle is the same shape. A small extra structure on the side trades a bit of storage for an enormous speedup on the queries that use it.
A transaction is the cabinet treating a batch of changes as one move. Either all the sheets go in or none of them do. The cleanest way to picture it is a snapshot of the drawer taken before the batch starts and restored if anything goes wrong.
struct Snapshot {
rows: Vec<Row>,
pk_index: HashMap<String, usize>,
}
impl Database {
fn snapshot(&self, name: &str) -> Option<Snapshot> {
let table = self.tables.get(name)?;
Some(Snapshot {
rows: table.rows.clone(),
pk_index: table.pk_index.clone(),
})
}
fn restore(&mut self, name: &str, snap: Snapshot) {
if let Some(table) = self.tables.get_mut(name) {
table.rows = snap.rows;
table.pk_index = snap.pk_index;
}
}
}snapshot copies the rows and the index. restore puts them back. Between the two, the program can insert new rows, change existing ones, delete some — and if a failure shows up halfway through, restoring the snapshot rolls everything back to the moment before the batch began. The cabinet ends up exactly where it started, as if the bad batch never happened. Real databases do this without copying the whole table. They write a log of every change, and on rollback they read the log backwards and undo each entry. The shape is the same. Either commit the whole batch or pretend none of it happened.
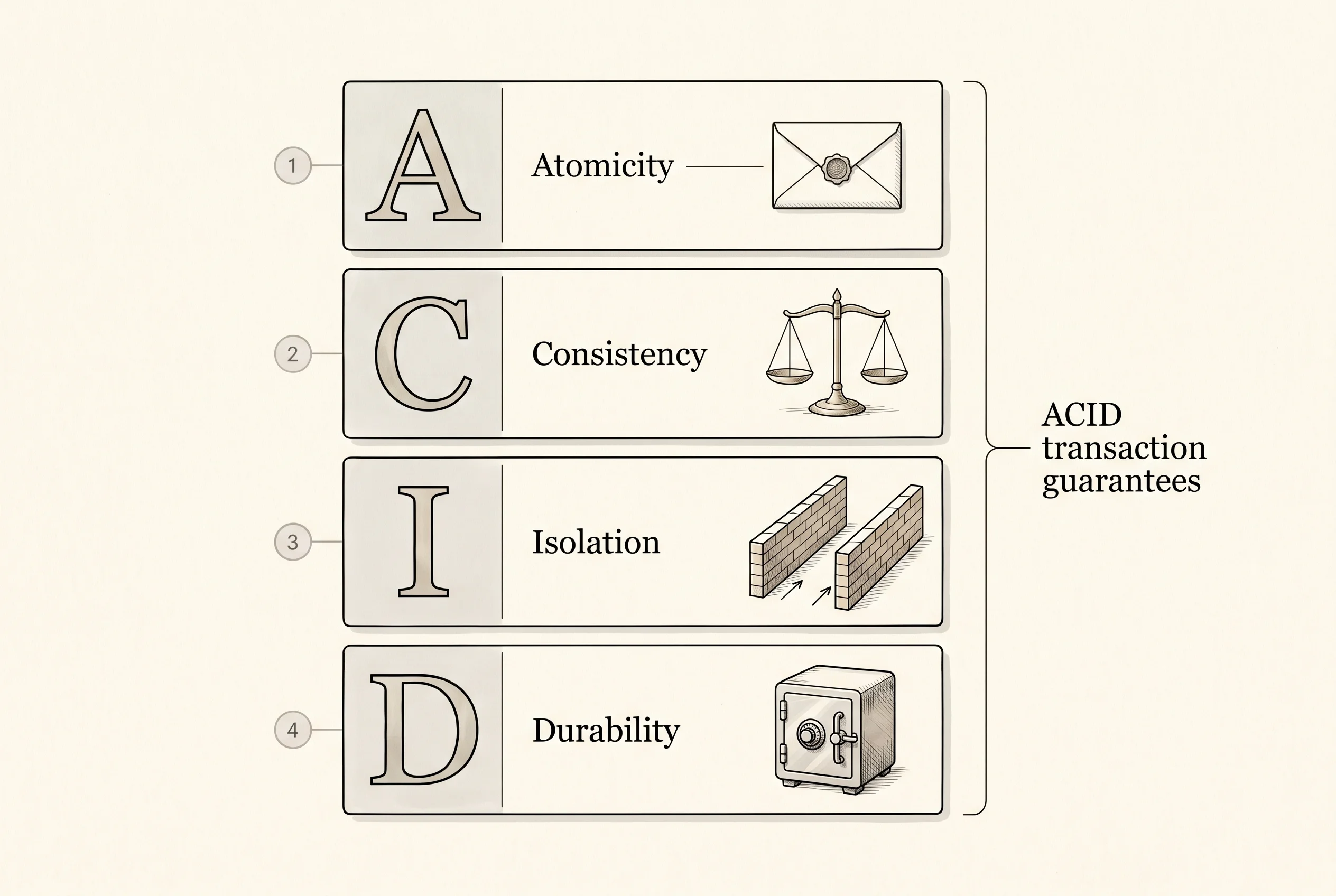
This is half of what people mean when they say a database is ACID. The four letters stand for Atomicity (the batch is all or nothing), Consistency (the data always follows the rules), Isolation (one transaction does not see the half-finished work of another), and Durability (once the database says "committed," the data survives a power cut). Jim Gray at IBM and later Tandem spent the 1970s and 1980s working out how to actually deliver these guarantees on machines that could fail at any moment. The receipt your bank prints when you withdraw cash is downstream of ACID. The promise that the account either has 100 less or it does not, and never some in-between state where the cash came out but the ledger forgot, is exactly atomicity.
The relational model — tables, rows, columns, SQL — is one family but not the only one. A document store like MongoDB keeps records as nested JSON blobs and lets each record have a different shape, which is friendlier when the data is messy or evolving and slower when the data is a tight grid. A key-value store like Redis is a single giant hash map — give it a key, get back a value, no schema, no joins — and it is the fastest of the four for the small set of jobs it can do. A graph database like Neo4j stores nodes and edges as first-class things and answers questions like "friends of my friends who live in Austin" in one query instead of seven joins. Each family is shaped around a different bottleneck the relational model fits awkwardly.
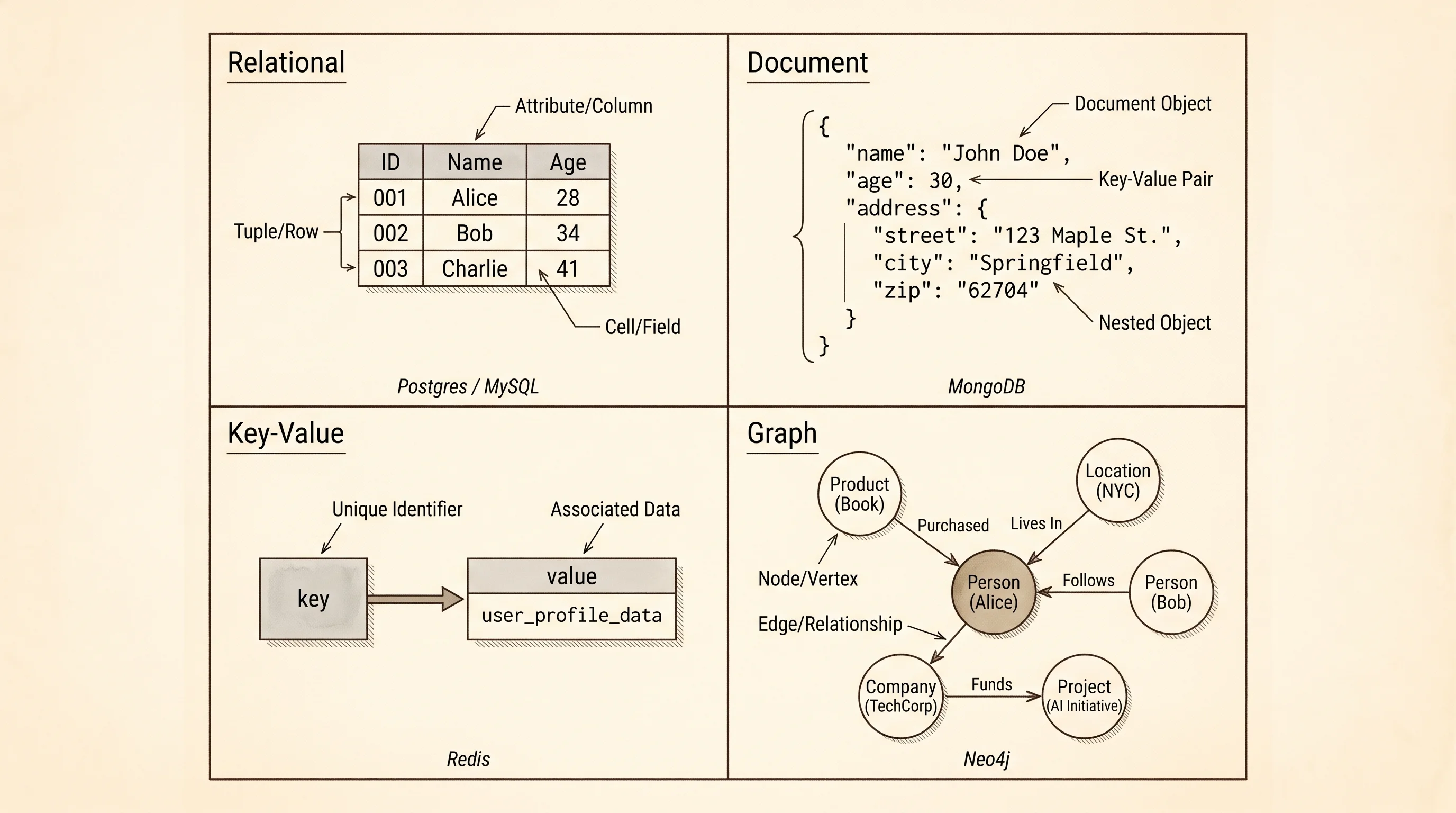
The four families fought a real war in the 2000s. Google, Amazon, and Facebook were storing more data than any single relational machine could hold, and the joins that worked on one box did not scale to a thousand. They wrote papers — Bigtable in 2006, Dynamo in 2007 — describing NoSQL systems that gave up some of ACID to get horizontal scale. A wave of open-source projects followed, the term NoSQL stuck, and for a decade every new startup picked a document store by default. The pendulum swung back in the 2010s when a generation of NewSQL systems — Spanner at Google, CockroachDB outside it — figured out how to keep the relational model and ACID guarantees while spreading the data across many machines. The cabinet got bigger without giving up its rules.
Now drive the in-memory cabinet through a full run and watch each piece work.
fn show_schema() {
let mut db = Database::new();
db.create_table("users", &["id", "name", "city"]);
println!("--- schema ---");
let table = db.tables.get("users").expect("users exists");
println!("table: users");
println!("columns: {}", table.columns.join(", "));
println!("rows: {}", table.rows.len());
println!();
}
fn show_inserts() {
let mut db = build_users();
println!("--- after 4 inserts ---");
print_table(&db, "users");
let dup = db.insert("users", &["1", "Eve", "Austin"]);
println!("insert dup id 1: {:?}", dup);
let wrong = db.insert("users", &["5", "Frank"]);
println!("insert wrong col count: {:?}", wrong);
println!();
}
fn show_select_scan() {
let db = build_users();
println!("--- SELECT * FROM users WHERE city = 'Austin' ---");
let hits = db.select_where("users", "city", "Austin");
for row in &hits {
println!("{}", row.join(" | "));
}
println!("matched {} rows", hits.len());
println!();
}
fn show_index_lookup() {
let db = build_users();
println!("--- index lookup by primary key ---");
let row = db.find_by_pk("users", "3");
println!("pk=3 -> {:?}", row);
let miss = db.find_by_pk("users", "99");
println!("pk=99 -> {:?}", miss);
println!();
}
fn show_transaction() {
let mut db = build_users();
println!("--- transaction (commit and rollback) ---");
let snap = db.snapshot("users").expect("snapshot");
db.insert("users", &["5", "Eve", "Denver"]).expect("insert");
db.insert("users", &["6", "Frank", "Boise"]).expect("insert");
println!("inside transaction:");
print_table(&db, "users");
db.restore("users", snap);
println!("after rollback:");
print_table(&db, "users");
}
fn build_users() -> Database {
let mut db = Database::new();
db.create_table("users", &["id", "name", "city"]);
db.insert("users", &["1", "Ada", "Austin"]).expect("insert");
db.insert("users", &["2", "Ben", "Boston"]).expect("insert");
db.insert("users", &["3", "Cleo", "Austin"]).expect("insert");
db.insert("users", &["4", "Dan", "Chicago"]).expect("insert");
db
}
fn print_table(db: &Database, name: &str) {
let table = match db.tables.get(name) {
Some(t) => t,
None => {
println!("no such table: {}", name);
return;
}
};
println!("{}", table.columns.join(" | "));
for row in &table.rows {
println!("{}", row.join(" | "));
}
}--- schema ---
table: users
columns: id, name, city
rows: 0
--- after 4 inserts ---
id | name | city
1 | Ada | Austin
2 | Ben | Boston
3 | Cleo | Austin
4 | Dan | Chicago
insert dup id 1: Err("duplicate primary key")
insert wrong col count: Err("wrong column count")
--- SELECT * FROM users WHERE city = 'Austin' ---
1 | Ada | Austin
3 | Cleo | Austin
matched 2 rows
--- index lookup by primary key ---
pk=3 -> Some(["3", "Cleo", "Austin"])
pk=99 -> None
--- transaction (commit and rollback) ---
inside transaction:
id | name | city
1 | Ada | Austin
2 | Ben | Boston
3 | Cleo | Austin
4 | Dan | Chicago
5 | Eve | Denver
6 | Frank | Boise
after rollback:
id | name | city
1 | Ada | Austin
2 | Ben | Boston
3 | Cleo | Austin
4 | Dan | ChicagoThe schema block shows the empty users table with three columns and zero rows. The insert block fills it with four rows and then proves the cabinet rejects bad sheets — a duplicate id 1 comes back as Err("duplicate primary key") and a sheet with two values instead of three comes back as Err("wrong column count"). The select block runs the equivalent of SELECT * FROM users WHERE city = 'Austin' and finds Ada and Cleo. The index lookup jumps straight to row 3 without scanning, and asking for the missing pk 99 returns None instead of crashing. The transaction block inserts Eve and Frank inside a snapshotted batch, prints the drawer with six rows, then restores the snapshot and prints the drawer back at four rows. Eve and Frank are gone as if they were never written.
One question worth asking — why does the snapshot copy the whole table instead of just remembering what changed? The reason is honesty over speed. Copying is the simplest thing that gets the rollback exactly right, so the lesson can show it without hand-waving. The price is memory proportional to the table size, which is fine for four rows and unacceptable for four million. A real database uses a write-ahead log so the rollback cost is proportional to the size of the batch instead of the size of the table. Same guarantee, different bookkeeping.
The thing this cabinet cannot do is share its drawers across two computers at once. Every read and write goes through one Database struct in one process, and the moment a second program wants to write to the same table the cabinet has no answer for who wins — which is the bottleneck the next lesson breaks open by treating the database as a JSON file two threads fight over.