Dynamic Programming
A gym logbook is the smartest piece of paper in the building. Last Tuesday you squatted 225 for 5. You write it down. Next Tuesday you do not have to guess what you can do — you open the book, read the line, add 5 pounds, and lift. Without the book you would either repeat the same weight forever or pull a hamstring guessing too high. Dynamic programming is the same trick applied to a function: when the function is about to recompute something it already solved, it looks the answer up in a notebook instead.
The technique was named in 1953 by Richard Bellman at the RAND Corporation. The name is famously misleading. Bellman wrote in his autobiography that his boss at RAND, the secretary of defense Charles Wilson, was "a man who hated the very word 'research.'" Bellman needed to call his work something his boss would fund, so he picked words that sounded important and unmathematical. "Dynamic programming." It stuck. The technique itself is older — Bellman formalized what mathematicians had been doing by hand since at least Fermat. The point is the same: when the same subproblem shows up many times in a recursive call tree, solve it once, store the answer, return the stored answer every other time. The cost goes from exponential to polynomial.
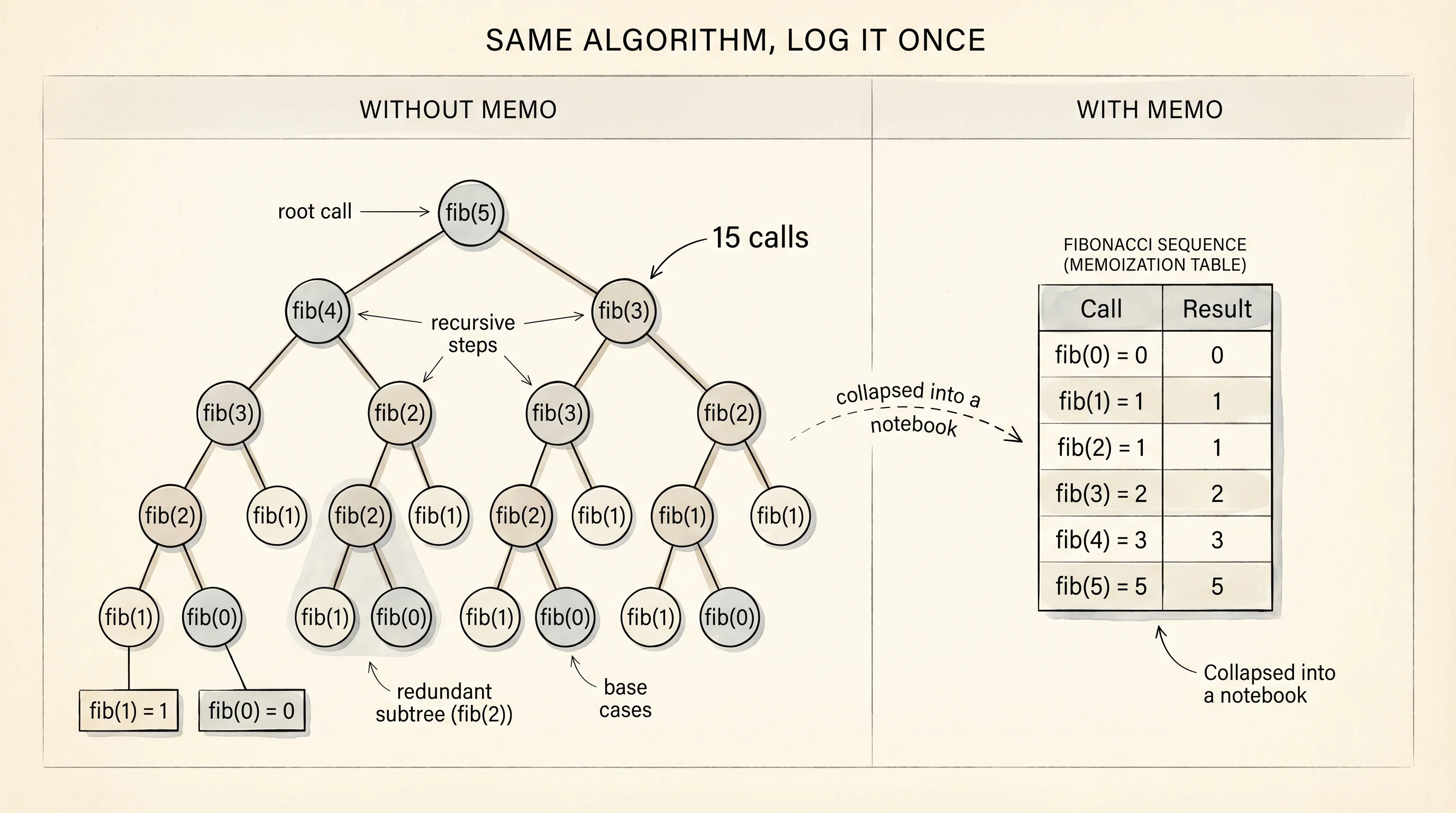
The cleanest case is Fibonacci. You saw the bad version last lesson. The recursion tree of fib(5) had fib(2) showing up three times and fib(1) showing up five times. For fib(35) the tree has more than a billion nodes and a modern laptop takes about 30 seconds. Every call past fib(2) is wasted work. Open dp.py and watch the cache fix it.
def fib_memo(n, memo=None):
if memo is None:
memo = {}
if n in memo:
return memo[n]
if n < 2:
return n
result = fib_memo(n - 1, memo) + fib_memo(n - 2, memo)
memo[n] = result
print(f"memo after fib({n}): {memo}")
return result
fib_memo(8)memo after fib(2): {2: 1}
memo after fib(3): {2: 1, 3: 2}
memo after fib(4): {2: 1, 3: 2, 4: 3}
memo after fib(5): {2: 1, 3: 2, 4: 3, 5: 5}
memo after fib(6): {2: 1, 3: 2, 4: 3, 5: 5, 6: 8}
memo after fib(7): {2: 1, 3: 2, 4: 3, 5: 5, 6: 8, 7: 13}
memo after fib(8): {2: 1, 3: 2, 4: 3, 5: 5, 6: 8, 7: 13, 8: 21}Read the memo growing from 1 entry to 7. Every time a new fib(n) finishes, it writes its answer to the dictionary. When the recursion needs fib(2) for the second time it reads the answer instead of recomputing the subtree. The runtime drops from O(2^n) to O(n) because each value is computed exactly once. fib(35) now runs in microseconds. Same algorithm shape, one dictionary, a billion times faster.
Python ships with a decorator that does this for you. functools.lru_cache wraps any function and gives it an automatic memo dictionary, with a size limit so it does not eat all your memory. The "lru" stands for "least recently used" — when the cache fills up, the entries you have not touched recently are evicted first. With maxsize=None the cache never evicts.
from functools import lru_cache
@lru_cache(maxsize=None)
def fib_cached(n):
if n < 2:
return n
return fib_cached(n - 1) + fib_cached(n - 2)
print(fib_cached(100))
print(fib_cached.cache_info())354224848179261915075
CacheInfo(hits=98, misses=101, currsize=101)fib_cached(100) runs instantly. The cache info is the receipt: 101 unique calls computed, 98 lookups served from cache. Without memoization that call would take longer than the universe has existed.
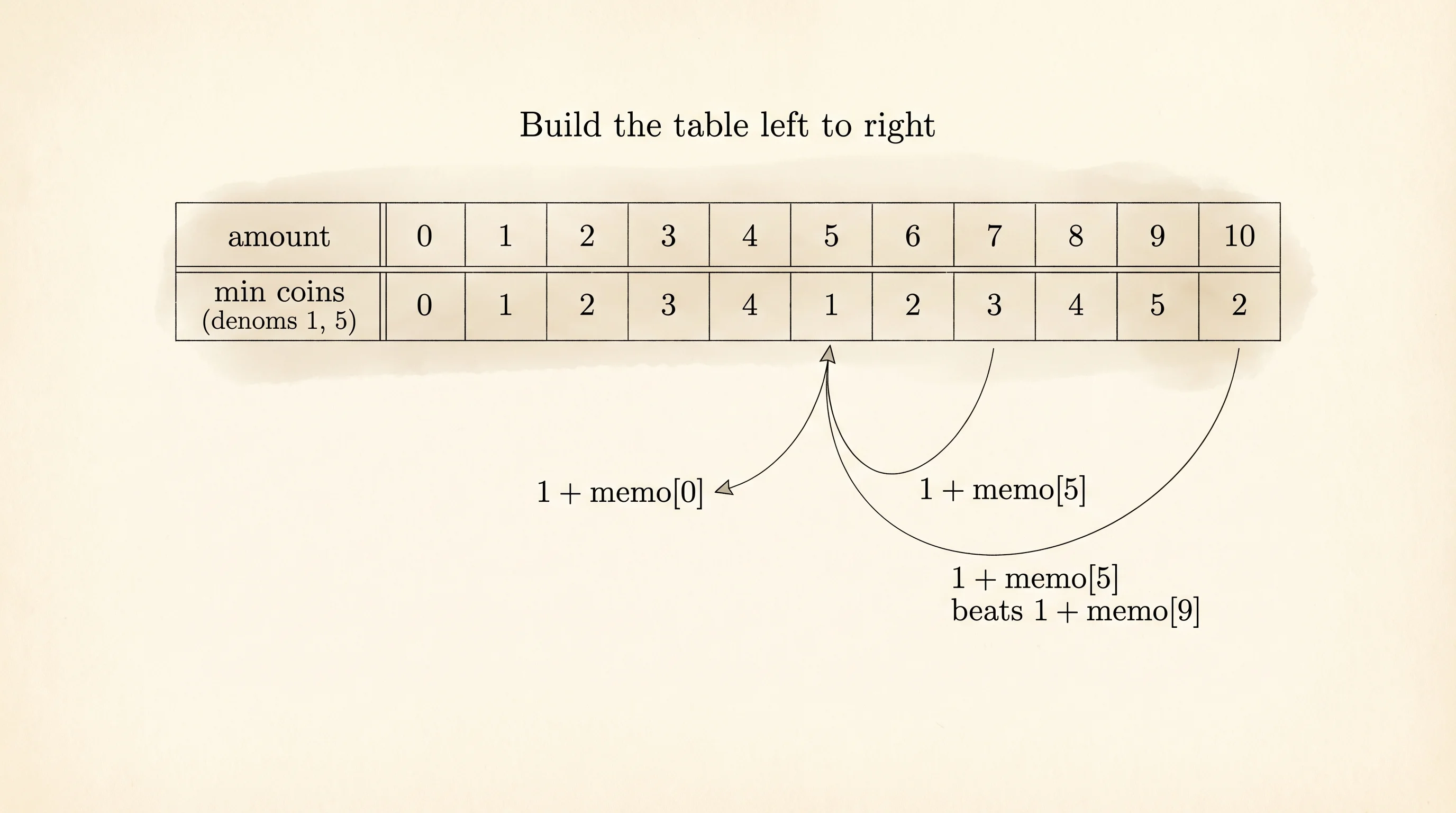
The coin change problem is harder and shows where DP earns its keep on a problem that does not have an obvious recursive form. You have coins of denominations like [1, 5, 10, 25] and a target amount like 30. What is the smallest number of coins you can use to make exactly that amount? The recursive insight: the best way to make amount a is 1 + min(best way to make a - c) for each coin c you might use last. Base case: 0 coins to make amount 0.
def coin_change(coins, amount, memo=None):
if memo is None:
memo = {0: 0}
if amount in memo:
return memo[amount]
best = float("inf")
for coin in coins:
if coin <= amount:
sub = coin_change(coins, amount - coin, memo)
if sub + 1 < best:
best = sub + 1
memo[amount] = best
print(f"memo[{amount}] = {best}")
return best
coin_change([1, 5, 10, 25], 30)memo[1] = 1
memo[2] = 2
memo[3] = 3
memo[4] = 4
memo[5] = 1
memo[6] = 2
memo[7] = 3
memo[8] = 4
memo[9] = 5
memo[10] = 1
memo[11] = 2
... (continues)
memo[29] = 5
memo[30] = 2Read the table. memo[5] is 1 because one nickel makes 5. memo[10] is 1 because one dime makes 10. memo[30] is 2 because the cheapest answer is one quarter and one nickel. The algorithm builds up answers for every smaller amount along the way. Without memoization the same subproblems would explode into a tree of overlapping work. With it, each amount is solved once.
The last classic is longest common subsequence — given two strings, find the longest sequence of characters that appears in both, in order, but not necessarily consecutively. The LCS of "ABCBDAB" and "BDCAB" is "BCAB", length 4. This is the algorithm git uses to compute diffs. The recursive insight: if the last characters of the two strings match, the LCS is 1 + LCS(s1[:-1], s2[:-1]). If they do not match, it is the longer of LCS(s1[:-1], s2) and LCS(s1, s2[:-1]).
def lcs(s1, s2):
memo = {}
def helper(i, j):
if i == 0 or j == 0:
return 0
if (i, j) in memo:
return memo[(i, j)]
if s1[i - 1] == s2[j - 1]:
result = 1 + helper(i - 1, j - 1)
else:
result = max(helper(i - 1, j), helper(i, j - 1))
memo[(i, j)] = result
return result
answer = helper(len(s1), len(s2))
print(f"memo entries: {len(memo)}")
return answer
print(lcs("ABCBDAB", "BDCAB"))The function returns 4. Without memoization the recursion would explode — each call branches into two subcalls of slightly smaller prefixes, and the same (i, j) pair gets re-derived through hundreds of paths. With the memo keyed on (i, j), every prefix-pair is computed exactly once. The total work drops from exponential to O(m × n) where m and n are the string lengths.
Memoization always trades memory for speed. The cache holds n entries instead of the original 1 entry. For Fibonacci that is a free trade — n integers is nothing. For LCS on two huge strings it can be gigabytes. The tabulation style of DP — building a 2D array bottom-up instead of recursing top-down — sometimes lets you throw away rows you no longer need and keep only the latest, dropping the memory cost from O(m × n) to O(min(m, n)). The decision is always the same calculus: are the recomputations cheaper than the bookkeeping?
You have the whole algorithm toolbox. The next move is to use it on the kind of problems someone hands you in a job interview.