AWS Lambda
The gym's ticket window needs someone to pick up the slips. Hire a full-time maintenance tech and you pay 40 hours a week whether the pile has 200 slips or zero. Rent a tech by the minute — show up, fix a treadmill, leave, get paid for the 14 minutes — and the gym pays nothing when the pile is empty. The tech is on call, not on payroll. AWS Lambda is that pay-by-the-minute tech for code. You hand AWS a Python function and the events that should trigger it, and AWS holds the function in a warm slot until something happens. An SQS message arrives, the slot wakes up, the function runs, the bill ticks up by the millisecond, and the slot goes cold. This lesson rents a Python Lambda and points it at the PokerHandsQueue you built last lesson.
Lambda launched at re:Invent 2014 as the first real serverless product. Tim Wagner, the engineer who designed it, had been running the AWS logs team and was tired of paying for EC2 instances that sat idle between log bursts. His pitch inside Amazon was "what if the smallest unit of compute was not an instance but a function." The team built it on top of Firecracker, a microVM technology Amazon later open-sourced in 2018. A cold start — the first invocation after a slot has been torn down — takes 100 to 400 milliseconds for Python and spins up a fresh microVM. A warm invocation, on an already-spun container, takes 1 to 10 milliseconds of pure your-code time. AWS bills per GB-ms: runtime in milliseconds multiplied by memory in GB. The Free Tier covers 400,000 GB-seconds a month, which for a 128 MB function is about 3 million invocations under 100 ms each. The lessons in this section fit inside it.
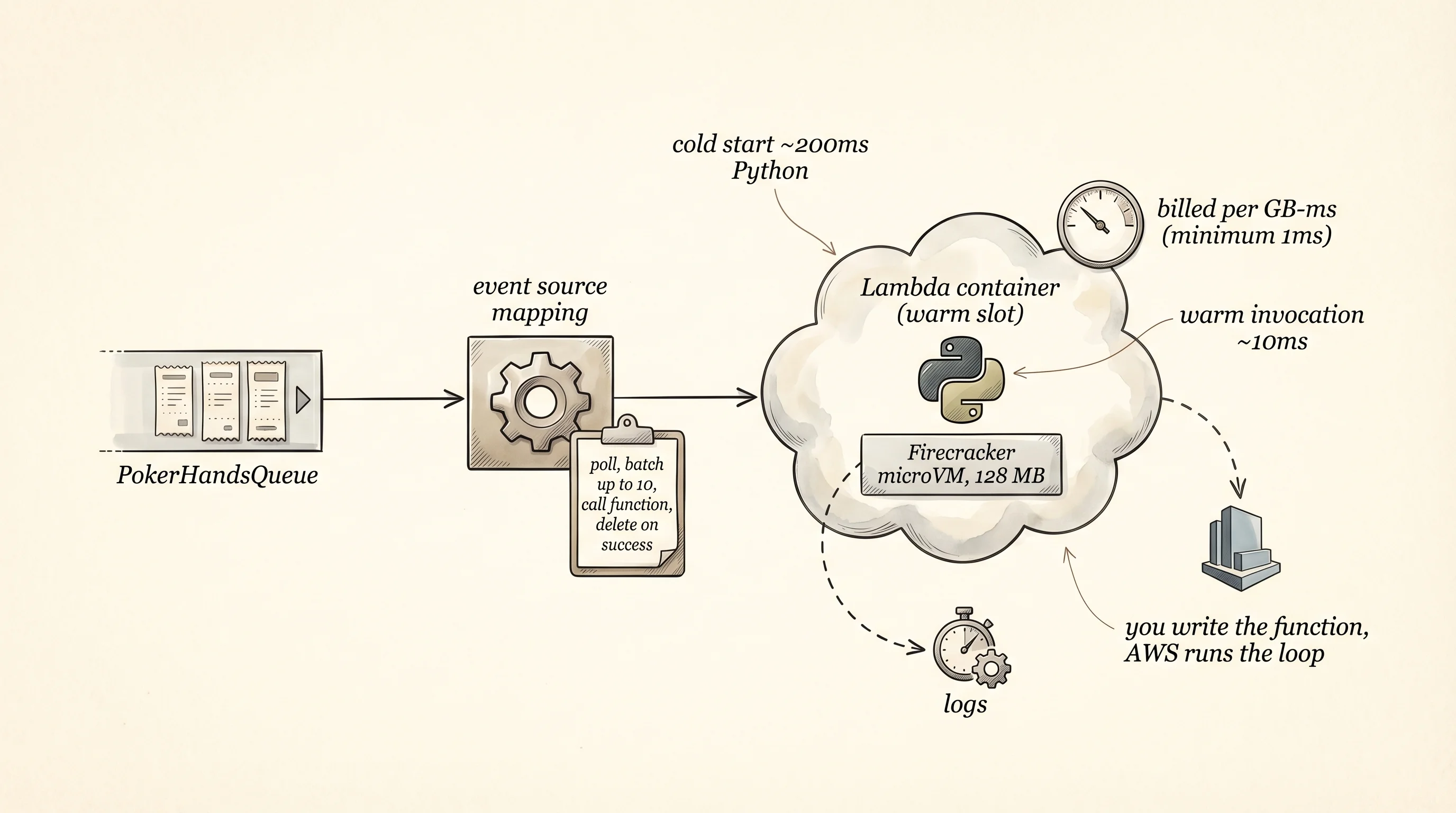
A Lambda function is three things: a zip file of your code, a runtime (Python 3.12 in our case), and an IAM role — a set of permissions the function runs under. When SQS triggers the function, it does not hand you one message at a time. It batches up to 10 messages and hands them to the function in a single invocation as event["Records"]. Your function processes the batch, and Lambda decides per-message whether it was handled. The convention is partial batch response: if any message in the batch fails, the function returns the list of failed message IDs in batchItemFailures, and SQS re-delivers only those. The successful messages are deleted automatically. This is the happy path for queue consumers in 2025.
The trigger itself is an event-source mapping, a separate AWS resource that sits between the queue and the function. You point it at the queue ARN and the function ARN, set a batch size, and AWS polls the queue on your behalf. You do not write the polling loop. When the mapping sees messages, it invokes the function. When the function returns success, it calls delete_message for you. The mapping is the manager who hangs the tech's pager — the tech never checks the window, the manager pages them.
The first step is an IAM role with permission to read from SQS and write to CloudWatch Logs. Roles are AWS's version of "a set of keys for a specific job." The function assumes the role when it runs.
import boto3
import json
import time
import zipfile
import io
from botocore.exceptions import ClientError
region = "us-east-1"
function_name = "PokerHandsConsumer"
role_name = "PokerHandsLambdaRole"
iam = boto3.client("iam", region_name=region)
trust = {
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "lambda.amazonaws.com"},
"Action": "sts:AssumeRole",
}],
}
try:
role_resp = iam.create_role(
RoleName=role_name,
AssumeRolePolicyDocument=json.dumps(trust),
)
role_arn = role_resp["Role"]["Arn"]
print(f"created role {role_arn}")
except ClientError as exc:
if exc.response["Error"]["Code"] == "EntityAlreadyExists":
role_arn = iam.get_role(RoleName=role_name)["Role"]["Arn"]
print(f"role exists: {role_arn}")
else:
raise
iam.attach_role_policy(
RoleName=role_name,
PolicyArn="arn:aws:iam::aws:policy/service-role/AWSLambdaSQSQueueExecutionRole",
)
print("attached SQS execution policy")
time.sleep(10)The trust policy above says "the Lambda service may assume this role on behalf of any function that uses it." The AWS-managed policy AWSLambdaSQSQueueExecutionRole bundles the four permissions a Lambda needs to consume a queue: receive, delete, get-attributes on the queue, and write logs. The time.sleep(10) is there because IAM is eventually consistent — a role created right now is not yet visible to Lambda for a few seconds.
Now write the handler code. Save this to a file called handler.py in the same directory.
import json
import logging
import os
log = logging.getLogger()
log.setLevel(logging.INFO)
def lambda_handler(event, context):
request_id = context.aws_request_id
memory_mb = context.memory_limit_in_mb
log.info(
"invoke request_id=%s memory_mb=%s records=%s",
request_id, memory_mb, len(event.get("Records", [])),
)
failures = []
for record in event.get("Records", []):
message_id = record["messageId"]
body = json.loads(record["body"])
try:
delta = body["chip_delta"]
if not isinstance(delta, int):
raise ValueError(
f"chip_delta must be int, got {type(delta).__name__}"
)
log.info(
"ok user=%s hole=%s delta=%+d result=%s",
body["user_id"], body["hole_cards"], delta, body["result"],
)
except (ValueError, KeyError) as exc:
log.error("FAIL message_id=%s reason=%s", message_id, exc)
failures.append({"itemIdentifier": message_id})
return {"batchItemFailures": failures}The context argument is what Lambda hands the function alongside the event. It carries the request ID (unique per invocation, matches the CloudWatch log stream), the memory limit, the remaining time in the budget, and the ARN of the function itself. Logging with a plain log.info(...) call sends the line to CloudWatch automatically — Lambda redirects stdout and the logger to its own log stream.
Package the handler and deploy.
lambda_client = boto3.client("lambda", region_name=region)
sqs = boto3.client("sqs", region_name=region)
queue_url = sqs.get_queue_url(QueueName="PokerHandsQueue")["QueueUrl"]
queue_arn = sqs.get_queue_attributes(
QueueUrl=queue_url,
AttributeNames=["QueueArn"],
)["Attributes"]["QueueArn"]
buf = io.BytesIO()
with zipfile.ZipFile(buf, "w", zipfile.ZIP_DEFLATED) as zf:
with open("handler.py", "rb") as src:
zf.writestr("handler.py", src.read())
zip_bytes = buf.getvalue()
try:
lambda_client.create_function(
FunctionName=function_name,
Runtime="python3.12",
Role=role_arn,
Handler="handler.lambda_handler",
Code={"ZipFile": zip_bytes},
MemorySize=128,
Timeout=10,
)
print(f"created function {function_name}")
except ClientError as exc:
if exc.response["Error"]["Code"] == "ResourceConflictException":
lambda_client.update_function_code(
FunctionName=function_name,
ZipFile=zip_bytes,
)
print(f"updated function code")
else:
raise
lambda_client.get_waiter("function_active_v2").wait(FunctionName=function_name)128 MB of memory is the smallest size Lambda offers and it is plenty for parsing JSON. A 10-second timeout is generous for this workload. The handler string handler.lambda_handler tells Lambda the module (the file name minus the .py) and the function to call inside it.
Wire the queue to the function with an event-source mapping.
mappings = lambda_client.list_event_source_mappings(
FunctionName=function_name,
EventSourceArn=queue_arn,
)["EventSourceMappings"]
if not mappings:
lambda_client.create_event_source_mapping(
EventSourceArn=queue_arn,
FunctionName=function_name,
BatchSize=10,
FunctionResponseTypes=["ReportBatchItemFailures"],
)
print("created event source mapping")
else:
print(f"mapping exists: {mappings[0]['UUID']}")FunctionResponseTypes=["ReportBatchItemFailures"] opts into partial batch responses. Without it, Lambda treats a failed batch as entirely failed and re-delivers every message. With it, only the IDs your handler returned in batchItemFailures get re-delivered.
Send a fresh batch of hands into the queue (the same 10 from the SQS lesson) and watch Lambda consume them. After ~5 seconds, pull the log stream.
logs = boto3.client("logs", region_name=region)
log_group = f"/aws/lambda/{function_name}"
time.sleep(8)
try:
streams = logs.describe_log_streams(
logGroupName=log_group,
orderBy="LastEventTime",
descending=True,
limit=1,
)["logStreams"]
if streams:
stream_name = streams[0]["logStreamName"]
events = logs.get_log_events(
logGroupName=log_group,
logStreamName=stream_name,
limit=50,
)["events"]
print(f"\n=== {stream_name} ===")
for event in events:
print(event["message"].rstrip())
except ClientError as exc:
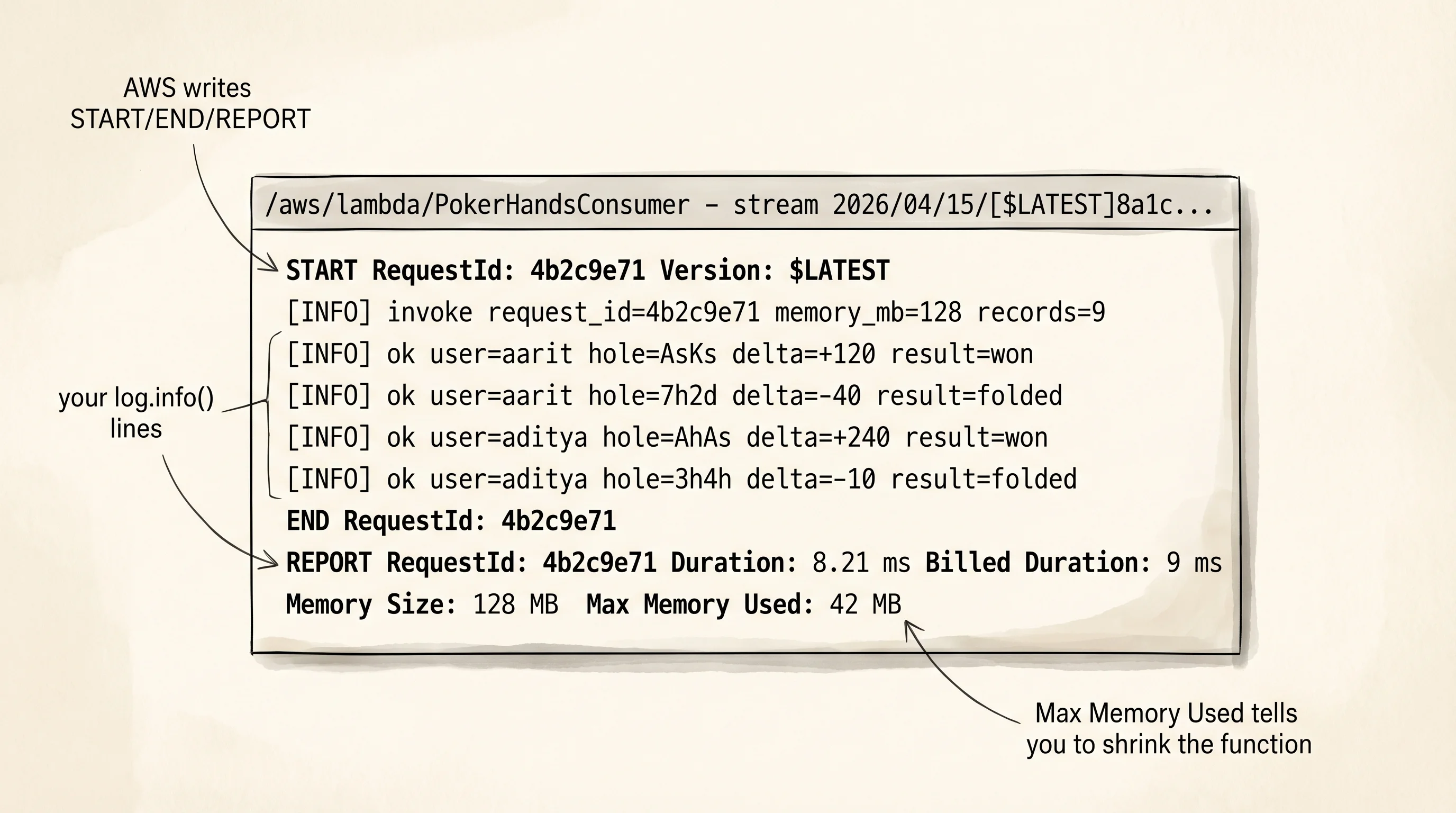
print(f"logs not ready yet: {exc}")The first few log lines AWS inserts itself: a START line with the request ID and memory, an END line, and a REPORT line with duration, billed duration, and max memory used. Your own log.info calls sit in between.
=== 2026/04/15/[$LATEST]8a1c... ===
START RequestId: 4b2c9e71-03a5-4d1e-9f2e-d7c51e8a2001 Version: $LATEST
[INFO] invoke request_id=4b2c9e71-03a5-4d1e-9f2e-d7c51e8a2001 memory_mb=128 records=9
[INFO] ok user=aarit hole=AsKs delta=+120 result=won
[INFO] ok user=aarit hole=7h2d delta=-40 result=folded
[INFO] ok user=aarit hole=QdQh delta=+75 result=won
[INFO] ok user=aditya hole=JsTs delta=-20 result=lost
[INFO] ok user=aditya hole=AhAs delta=+240 result=won
[INFO] ok user=aarit hole=5c6c delta=-15 result=folded
[INFO] ok user=aditya hole=KhQh delta=+60 result=won
[INFO] ok user=aarit hole=9d9s delta=+35 result=won
[INFO] ok user=aditya hole=3h4h delta=-10 result=folded
END RequestId: 4b2c9e71-03a5-4d1e-9f2e-d7c51e8a2001
REPORT RequestId: 4b2c9e71-... Duration: 8.21 ms Billed Duration: 9 ms Memory Size: 128 MB Max Memory Used: 42 MB Init Duration: 186.53 ms
START RequestId: 6a71d0e4-9b21-4a37-8bcd-d091e7f4b0a8 Version: $LATEST
[INFO] invoke request_id=6a71d0e4-9b21-4a37-8bcd-d091e7f4b0a8 memory_mb=128 records=1
[ERROR] FAIL message_id=9e4d6c12-... reason=chip_delta must be int, got str
END RequestId: 6a71d0e4-9b21-4a37-8bcd-d091e7f4b0a8The batch of 9 valid hands ran once in about 8 ms, billed at 9 ms with 42 MB of peak memory against a 128 MB cap. The init duration on the first line is the cold-start overhead — 186 ms to unpack the zip, start the Python interpreter, and import the handler. Every warm invocation after this one skips it. The poison message comes back in later invocations until the event-source mapping reports it failed 3 times, at which point the DLQ from the SQS lesson catches it. You can confirm the DLQ depth with the same SQS poll call from last lesson.
Why did the ok batch run in one invocation and the FAIL on its own? Because Lambda reported the TsJs message ID in batchItemFailures, SQS kept re-delivering only that message. The event-source mapping never groups successful deliveries with failed ones in subsequent retries. Partial batch responses are the cheapest way to get "process what you can, retry what broke" semantics.
Clean up when you finish.
for mapping in lambda_client.list_event_source_mappings(
FunctionName=function_name,
EventSourceArn=queue_arn,
)["EventSourceMappings"]:
lambda_client.delete_event_source_mapping(UUID=mapping["UUID"])
lambda_client.delete_function(FunctionName=function_name)
iam.detach_role_policy(
RoleName=role_name,
PolicyArn="arn:aws:iam::aws:policy/service-role/AWSLambdaSQSQueueExecutionRole",
)
iam.delete_role(RoleName=role_name)
print("cleaned up function, mapping, and role")The stack now has storage (S3), shaped data (DynamoDB), async communication (SQS), and on-demand compute (Lambda) — enough to run most of a distributed system without owning a single server. The next section teaches the last piece: how to put intelligence into this plumbing by calling an LLM from your own Python.