Hash Tables
The library has shelves, chains, carts, and lines. Find any of them by position and you are golden. Try to find a book by its title and you walk every shelf in the building. The card catalog solved this in the 1870s. Melvil Dewey at Amherst College gave every book an address derived from its subject, and the librarians filed reference cards in wooden drawers grouped by the first few letters of the title. Want Moby Dick? Walk to the M drawer, flip three cards, read the shelf address, walk straight there. The catalog is the difference between an O(n) hunt and an O(1) jump. The hash table is the same trick, mechanized.
The mechanization shows up in 1953 inside an IBM internal memo. Hans Peter Luhn, a researcher who had spent the 1940s building punched-card sorters for the textile industry, was working on the problem of looking up records in IBM's new electronic computers. He proposed running a quick numeric formula on each record's key — a person's last name, say — and using the result as a slot number in a fixed-size table. Two records with different keys could land in the same slot, which Luhn called a "collision." His proposed fix was chaining: keep a small linked list at each slot and append collisions to it. The IBM memo never made the open literature, but the technique became the standard implementation across every language that followed. Donald Knuth gave it the analysis treatment in 1973 in volume 3 of TAOCP. Python's dict is a more elaborate version of the same shape, with the additional twist that since version 3.7 in 2017 it preserves the order in which keys were inserted, a feature originally added as an implementation accident in 3.6 and then promoted to a guaranteed property of the language.
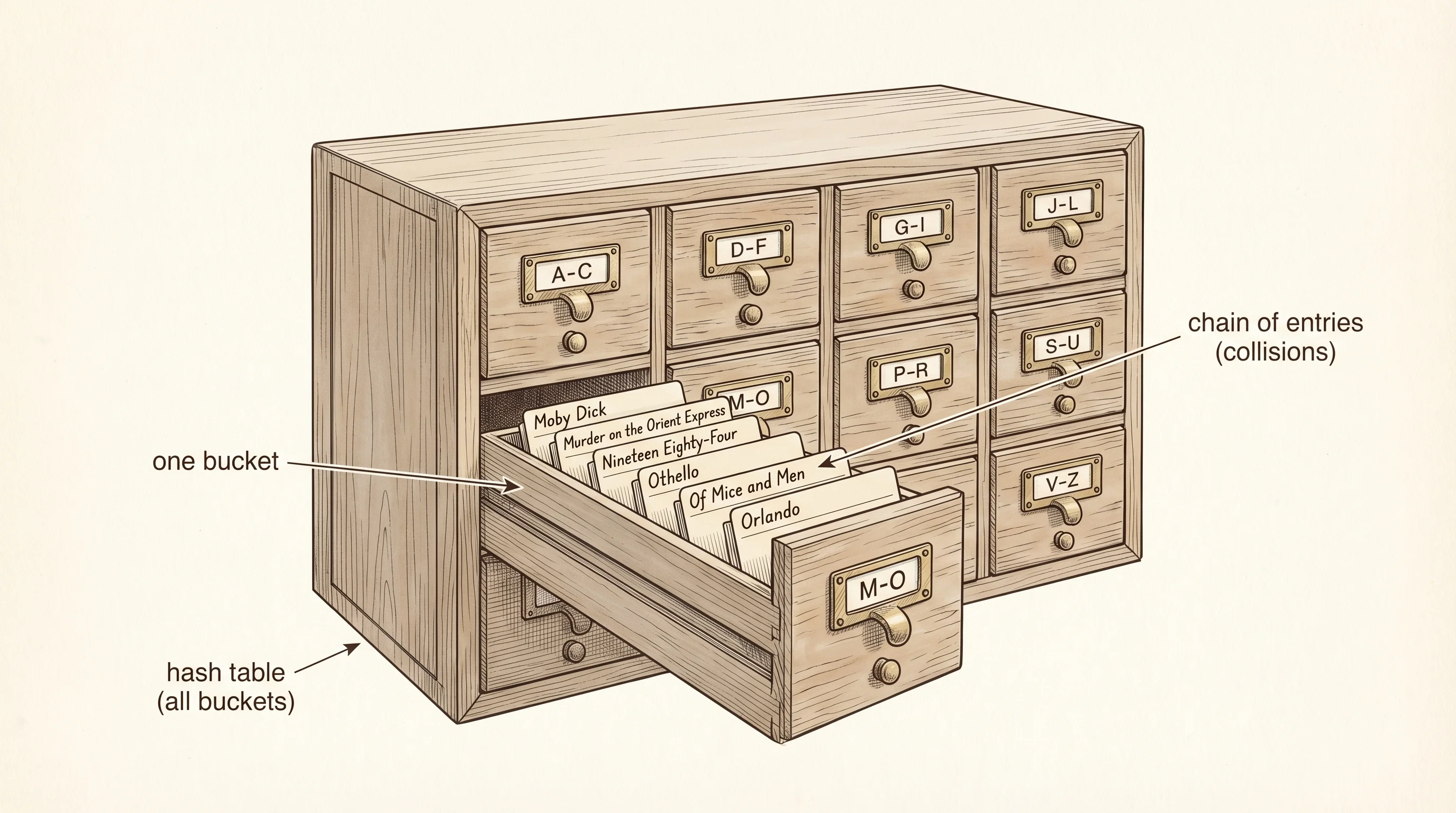
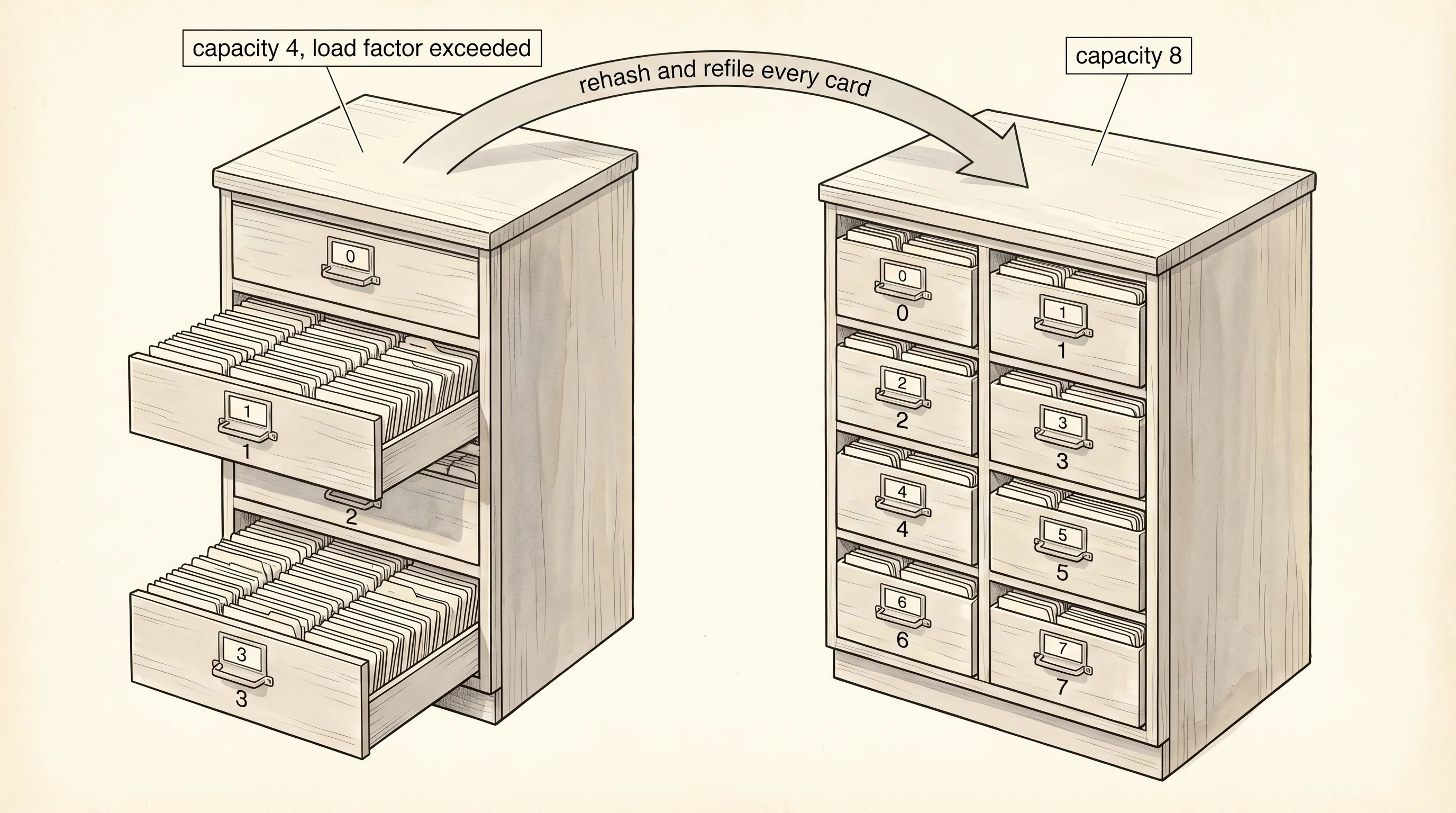
Build the catalog yourself in hashmap.py. Two ingredients: a hash function that turns a string key into an integer, and a list of buckets, each bucket a small list that holds key-value pairs. Collisions accumulate inside a bucket. When the table fills past 75 percent — that is the load factor, the ratio of stored entries to total buckets — you double the bucket count and rehash everyone, the same move the array's resize made.
class MyHashMap:
def __init__(self, capacity=4):
self.capacity = capacity
self.size = 0
self.buckets = [[] for _ in range(capacity)]
def _index(self, key):
return hash(key) % self.capacity
def put(self, key, value):
bucket = self.buckets[self._index(key)]
for pair in bucket:
if pair[0] == key:
pair[1] = value
return
bucket.append([key, value])
self.size += 1
if self.size / self.capacity > 0.75:
self._resize()
def get(self, key):
bucket = self.buckets[self._index(key)]
for pair in bucket:
if pair[0] == key:
return pair[1]
raise KeyError(key)
def _resize(self):
old = self.buckets
self.capacity *= 2
self.buckets = [[] for _ in range(self.capacity)]
self.size = 0
for bucket in old:
for key, value in bucket:
self.put(key, value)
def show(self):
print(f"size={self.size} cap={self.capacity}")
for i, bucket in enumerate(self.buckets):
content = ", ".join(f"{k}={v}" for k, v in bucket)
print(f" bucket[{i}]: [{content}]")Python's built-in hash() function turns any hashable value into a long integer. Modulo by capacity squeezes that integer into a bucket index. Type a few puts and watch the catalog reshape.
m = MyHashMap()
m.show()
print()
for key, value in [("apple", 1), ("banana", 2), ("cherry", 3), ("date", 4), ("elderberry", 5)]:
m.put(key, value)
m.show()
print()Output (your hash values will look the same shape but may differ in which key lands where, because Python randomizes its hash seed at startup):
size=0 cap=4
bucket[0]: []
bucket[1]: []
bucket[2]: []
bucket[3]: []
size=1 cap=4
bucket[0]: []
bucket[1]: [apple=1]
bucket[2]: []
bucket[3]: []
size=2 cap=4
bucket[0]: [banana=2]
bucket[1]: [apple=1]
bucket[2]: []
bucket[3]: []
size=3 cap=4
bucket[0]: [banana=2]
bucket[1]: [apple=1]
bucket[2]: []
bucket[3]: [cherry=3]
size=4 cap=8
bucket[0]: []
bucket[1]: [apple=1]
bucket[2]: [banana=2]
bucket[3]: []
bucket[4]: [date=4]
bucket[5]: []
bucket[6]: [cherry=3]
bucket[7]: []
size=5 cap=8
bucket[0]: []
bucket[1]: [apple=1]
bucket[2]: [banana=2]
bucket[3]: []
bucket[4]: [date=4, elderberry=5]
bucket[5]: []
bucket[6]: [cherry=3]
bucket[7]: []Read top to bottom. The first three puts dropped each key into a different bucket. The fourth put — date=4 — pushed size to 4 out of capacity 4, blowing past the 0.75 threshold. The resize built an 8-bucket table and rehashed every existing key into it. Notice the keys land in different buckets after the resize, because hash(key) % 8 gives a different answer than hash(key) % 4. The fifth put, elderberry=5, hashed into a bucket that already held date. That is a collision. The chain inside bucket[4] now holds two pairs. A get on date walks the chain, compares each key, and returns when it finds a match.
The whole catalog is doing one trick: turn a name into a slot number, then walk the small chain at that slot. Average-case performance is O(1). Worst case — if every key hashed to the same bucket — collapses to O(n), which is why a good hash function and a low load factor matter.
Now meet dict. Python's built-in does the same trick with three improvements: it preserves insertion order, it stores keys and values in a separate compact array (the buckets only hold pointers into that array), and the C implementation handles collisions with open addressing instead of chaining. The interface is the friendliest in the language.
m = {}
print(m)
for key, value in [("apple", 1), ("banana", 2), ("cherry", 3), ("date", 4), ("elderberry", 5)]:
m[key] = value
print(m)
print("get banana:", m["banana"])
print("len:", len(m))
print("contains 'cherry'?", "cherry" in m)
del m["apple"]
print("after delete apple:", m)Output:
{}
{'apple': 1}
{'apple': 1, 'banana': 2}
{'apple': 1, 'banana': 2, 'cherry': 3}
{'apple': 1, 'banana': 2, 'cherry': 3, 'date': 4}
{'apple': 1, 'banana': 2, 'cherry': 3, 'date': 4, 'elderberry': 5}
get banana: 2
len: 5
contains 'cherry'? True
after delete apple: {'banana': 2, 'cherry': 3, 'date': 4, 'elderberry': 5}Same lookup, hidden behind brackets. The order is preserved because dict has been insertion-ordered since 3.7. Notice dict never tells you when it resized. The CPython implementation grows when the table is two-thirds full, copies every entry into a larger backing array, and continues — exactly what MyHashMap did, just without a print statement.
Question: in the MyHashMap trace above, which two keys ended up sharing a bucket after the resize?
Answer: date and elderberry, both in bucket[4] of the 8-bucket table. The chain holds two pairs and a get on either key walks that two-element chain to find the match.
The catalog answers "where is the book named X?" instantly. It cannot answer "give me the book that comes alphabetically before this one" without scanning every entry. The catalog has no order beyond the hash. If your books need to know who their neighbors are — alphabetically, or numerically, or in any other ranking — you need a structure with parents and children, not buckets and chains.