Testing
A spotter at the gym stands behind you with both hands hovering under the bar. He never touches the weight while things are going right. The second the bar slows, he is the reason your face does not meet the plate. A test is a spotter you wrote for your own code. Every time you change a line, the test sits behind the function, checks that the output still matches what you said it should be, and yells if it does not.
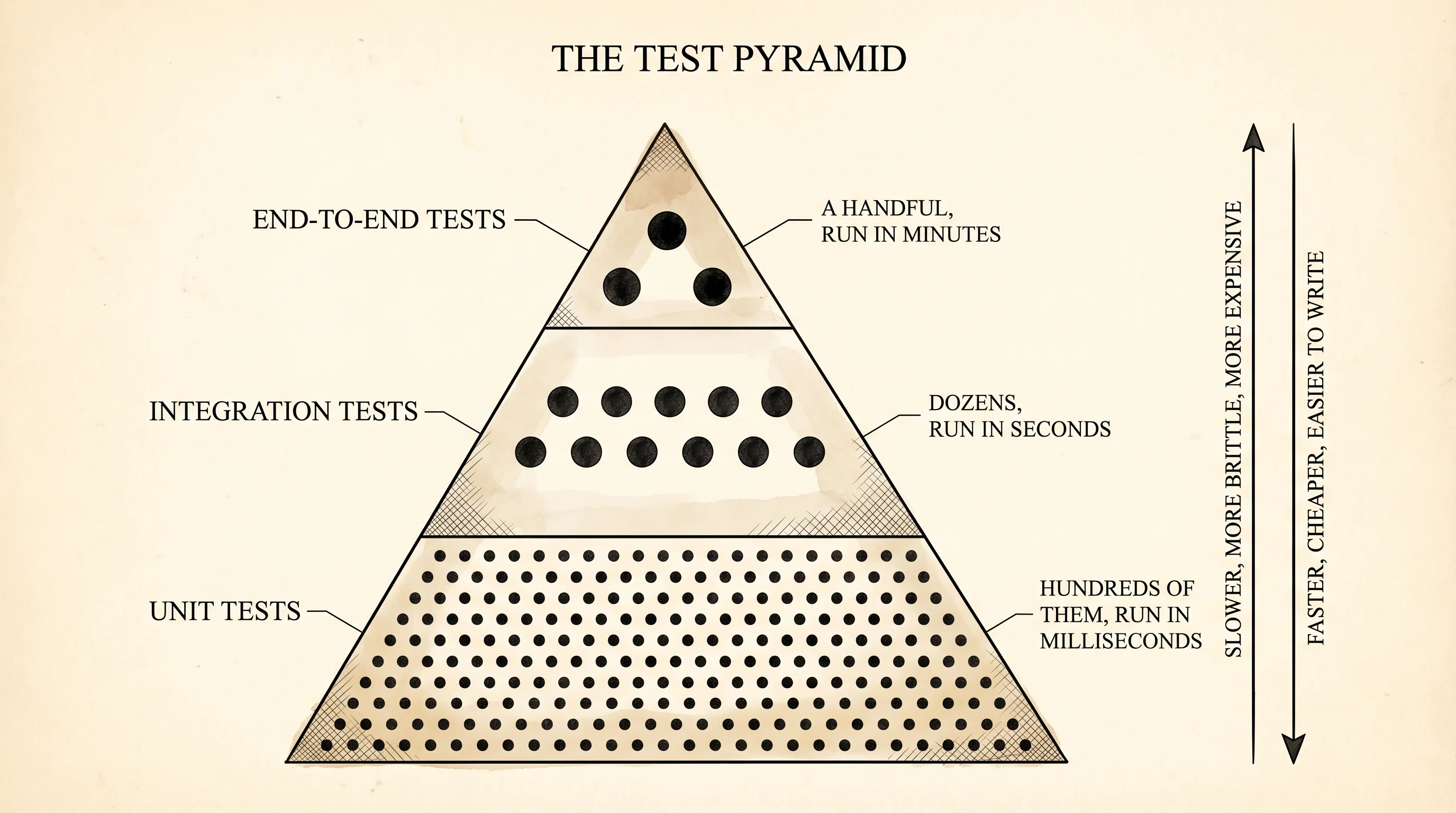
A serious gym does not hand you one spotter for everything. The deadlift bay has a guy who watches your hips on every single rep — he is fast, cheap, and only looks at one joint. The bench has a spotter standing over the bar who only steps in when the lift stalls. Once a year a powerlifting meet brings in three judges to watch the whole lift from start to rack and rule on the entire performance. The first kind catches small errors hundreds of times a session. The second catches medium errors a few dozen times. The third runs slowly and you only hire a few of them. Every codebase needs the same three layers, and the shape of how many of each you write is the test pyramid.
Kent Beck wrote the first widely-used unit testing library, JUnit, in 1997 on a flight from Zurich to Atlanta. He had been doing test-first development in Smalltalk for years and wanted the same thing in Java. JUnit shipped, Java shops adopted it, and every other language copied the design within a decade. Python shipped its own copy, called unittest, in the standard library — but it inherited JUnit's clunky Java-flavored style where every test had to live inside a class and every assertion was a method call like self.assertEqual(a, b). In 2004 a German developer named Holger Krekel wrote pytest as a cleaner alternative. Krekel's version let you write a test as a regular function whose name starts with test_ and use Python's plain assert keyword. The Python community switched, and today pytest is the default for every serious codebase. Mike Cohn drew the pyramid in 2009 in his book Succeeding with Agile, naming the three tiers and the rule that the bottom must be the widest.
Open the poker project from the last lesson. The file layout already has a src/poker/ folder with cards.py, score.py, player.py, game.py. Tests live in a sibling folder called tests/ at the project root. Install pytest into the venv first:
cd ~/learning-python/poker
source .venv/bin/activate
pip install pytest pytest-cov
mkdir tests
touch tests/__init__.py
touch tests/test_score.py
touch tests/test_game.pycd $HOME\learning-python\poker
.venv\Scripts\Activate.ps1
pip install pytest pytest-cov
mkdir tests
ni tests\__init__.py
ni tests\test_score.py
ni tests\test_game.pyThe bottom of the pyramid is unit tests. A unit test calls one pure function with one set of inputs and checks one output. It does not touch the network, the disk, or random state. It runs in microseconds. You write hundreds of them because each one is so cheap that the cost of writing it is paid back the first time it catches a regression. Open tests/test_score.py and type the smallest one you can write:
from poker.cards import Card
from poker.score import score_hand, HIGH_CARD
def test_high_card_returns_high_card_rank() -> None:
hand = [Card("2", "s"), Card("5", "h"), Card("9", "d"), Card("J", "c"), Card("K", "s")]
assert score_hand(hand)[0] == HIGH_CARDThe poker module uses suit symbols in its Card class, but tests are easier to read with letter suits — s for spades, h for hearts, d for diamonds, c for clubs — and the Card dataclass stores whatever string you hand it. Run the test from the project root:
pytest -vOutput:
========================= test session starts =========================
platform darwin -- Python 3.12.2, pytest-8.3.3, pluggy-1.5.0
collected 1 item
tests/test_score.py::test_high_card_returns_high_card_rank PASSED [100%]
========================== 1 passed in 0.02s =========================Pytest found the file because its name starts with test_. It found the function because the name starts with test_. It ran the function, noticed the assert held, and printed green. One line of real code is doing all the work. The -v flag tells pytest to print the name of every test it runs instead of a dot per test.
Every unit test has the same three-part shape under the hood. Arrange the data you need. Act by calling the function under test. Assert on the output. You arranged a 5-card hand of clearly different ranks. You acted by calling score_hand. You asserted that the first element of the returned tuple is the HIGH_CARD constant, which is 1. If the function ever regressed and started classifying this as a pair, the assertion would fail, pytest would print red, and you would know within seconds.
The scoring module has 10 hand ranks. Writing 10 separate functions for them would copy and paste the same boilerplate with small variations — the smell from the LeetCode lesson. Pytest ships a feature called parametrize that fixes it. You hand the decorator a list of input-output pairs, and pytest runs the test function once per pair as if you had written 10 separate functions. Add this block to test_score.py:
import pytest
from poker.score import (
score_hand, HIGH_CARD, ONE_PAIR, TWO_PAIR, THREE_OF_A_KIND,
STRAIGHT, FLUSH, FULL_HOUSE, FOUR_OF_A_KIND,
STRAIGHT_FLUSH, ROYAL_FLUSH,
)
@pytest.mark.parametrize("hand, expected_rank", [
([("2","s"),("5","h"),("9","d"),("J","c"),("K","s")], HIGH_CARD),
([("A","s"),("A","h"),("9","d"),("J","c"),("K","s")], ONE_PAIR),
([("A","s"),("A","h"),("K","d"),("K","c"),("9","s")], TWO_PAIR),
([("A","s"),("A","h"),("A","d"),("K","c"),("9","s")], THREE_OF_A_KIND),
([("5","s"),("6","h"),("7","d"),("8","c"),("9","s")], STRAIGHT),
([("2","s"),("3","s"),("4","s"),("5","s"),("7","s")], FLUSH),
([("A","s"),("A","h"),("A","d"),("K","c"),("K","s")], FULL_HOUSE),
([("A","s"),("A","h"),("A","d"),("A","c"),("9","s")], FOUR_OF_A_KIND),
([("5","s"),("6","s"),("7","s"),("8","s"),("9","s")], STRAIGHT_FLUSH),
([("10","s"),("J","s"),("Q","s"),("K","s"),("A","s")], ROYAL_FLUSH),
])
def test_hand_ranks(hand, expected_rank) -> None:
cards = [Card(r, su) for r, su in hand]
assert score_hand(cards)[0] == expected_rankOne decorator, 10 parameter sets, 10 tests. Run pytest -v again:
tests/test_score.py::test_hand_ranks[hand0-1] PASSED
tests/test_score.py::test_hand_ranks[hand1-2] PASSED
tests/test_score.py::test_hand_ranks[hand2-3] PASSED
tests/test_score.py::test_hand_ranks[hand3-4] PASSED
tests/test_score.py::test_hand_ranks[hand4-5] PASSED
tests/test_score.py::test_hand_ranks[hand5-6] PASSED
tests/test_score.py::test_hand_ranks[hand6-7] PASSED
tests/test_score.py::test_hand_ranks[hand7-8] PASSED
tests/test_score.py::test_hand_ranks[hand8-9] PASSED
tests/test_score.py::test_hand_ranks[hand9-10] PASSED
============= 11 passed in 0.04s =============Each parameter set becomes a separate test case in the report. If row 3 broke, only that one would show red, and the report would tell you exactly which hand failed. This is the pattern for testing anything that has many input-output pairs.
Edge cases are where bugs hide. The wheel straight (A-2-3-4-5) counts the Ace as 1 and tops out at 5. A tie between two hands of the same rank is decided by the kickers packed into the tuple. A flush that is also a straight is a straight flush, not two separate wins. Each of these is a one-liner test:
def test_wheel_straight_tops_at_five() -> None:
cards = [Card("A","s"), Card("2","h"), Card("3","d"), Card("4","c"), Card("5","s")]
score = score_hand(cards)
assert score[0] == STRAIGHT
assert score[1] == 5
def test_two_pair_ranked_by_higher_pair() -> None:
aces_over_kings = [Card("A","s"), Card("A","h"), Card("K","d"), Card("K","c"), Card("2","s")]
kings_over_queens = [Card("K","s"), Card("K","h"), Card("Q","d"), Card("Q","c"), Card("2","s")]
assert score_hand(aces_over_kings) > score_hand(kings_over_queens)
def test_same_pair_decided_by_kicker() -> None:
ace_kicker = [Card("K","s"), Card("K","h"), Card("A","d"), Card("3","c"), Card("2","s")]
queen_kicker = [Card("K","s"), Card("K","h"), Card("Q","d"), Card("3","c"), Card("2","s")]
assert score_hand(ace_kicker) > score_hand(queen_kicker)
def test_four_of_a_kind_beats_full_house() -> None:
quads = [Card("7","s"), Card("7","h"), Card("7","d"), Card("7","c"), Card("2","s")]
full = [Card("A","s"), Card("A","h"), Card("A","d"), Card("K","c"), Card("K","s")]
assert score_hand(quads) > score_hand(full)
def test_flush_not_a_straight() -> None:
cards = [Card("2","s"), Card("5","s"), Card("9","s"), Card("J","s"), Card("K","s")]
assert score_hand(cards)[0] == FLUSH
def test_equal_hands_return_equal_scores() -> None:
a = [Card("A","s"), Card("K","h"), Card("Q","d"), Card("J","c"), Card("10","s")]
b = [Card("A","d"), Card("K","c"), Card("Q","s"), Card("J","h"), Card("10","c")]
assert score_hand(a) == score_hand(b)These six tests, plus the 10 parametrized ones, plus the first one, give 17 unit tests on score.py alone. A real codebase keeps going past 50. Each one runs in under a millisecond. The whole file finishes before you have looked away from the terminal. That speed is what makes the bottom of the pyramid wide. You never hesitate to write another unit test, because the cost is rounding error.
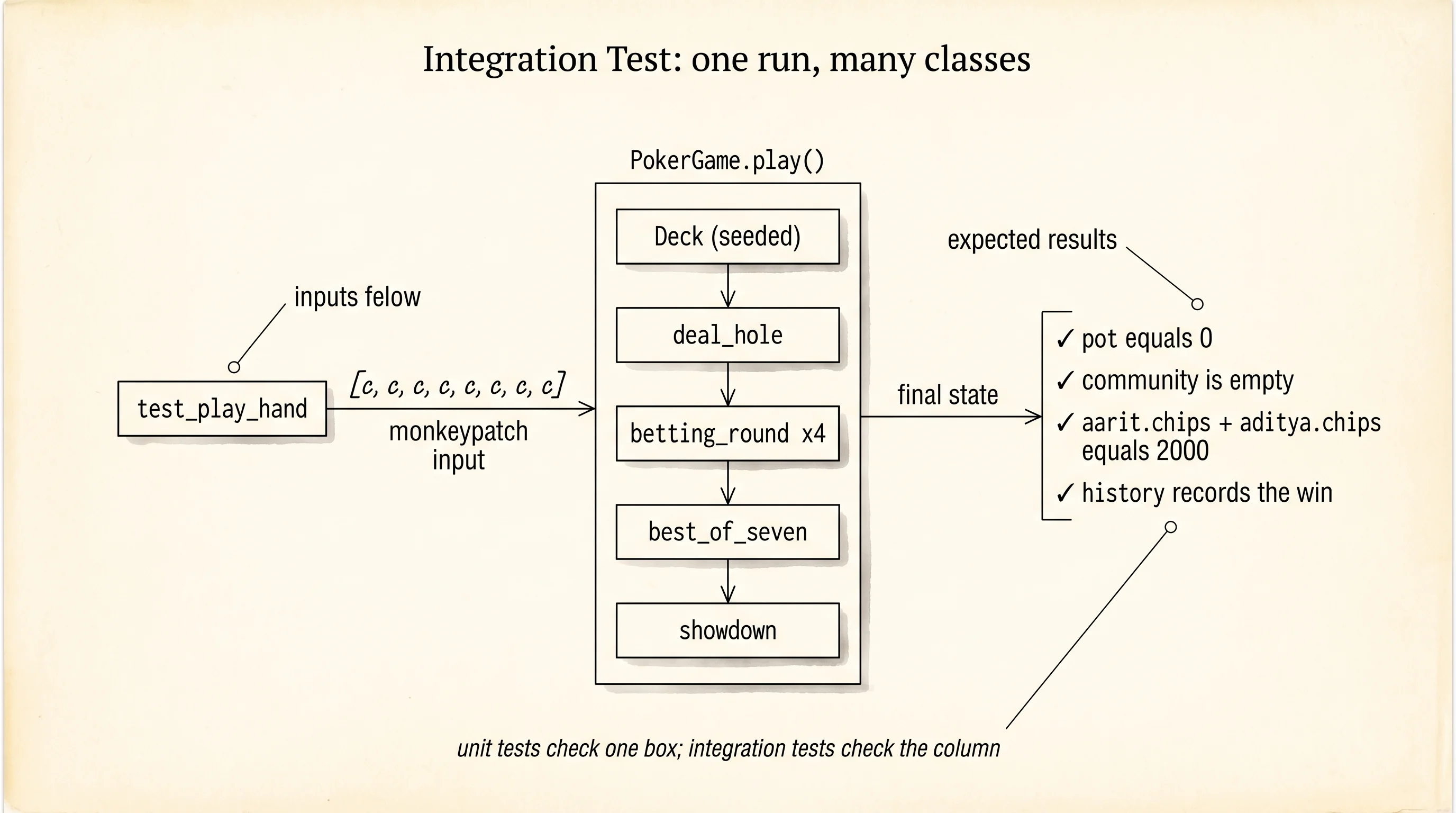
The middle tier of the pyramid is integration tests. A unit test calls one function in isolation. An integration test wires several real classes together and checks that the whole assembly does the right thing end to end. For the poker project, the unit tests covered score_hand perfectly, but no test has yet asked: when PokerGame.play runs a full hand from shuffle to showdown, does the pot end up with the right player, are the hole cards what the deck handed out, does the action history record every move? Each of those answers depends on Card, Deck, Player, scoring, and the game loop all working together. A single integration test exercises that full path.
The hard part of testing PokerGame.play is that it asks for keyboard input on every betting round and shuffles a real deck with random.shuffle. Both of those are sources of non-determinism — the kind of thing that turns a green test red for no real reason. Pytest fixes both with two tools: monkeypatch to swap the input function with a scripted answer, and a fixed random seed to make the shuffle reproducible. A fixture in pytest is a function decorated with @pytest.fixture that returns some setup value; any test that asks for an argument with the same name gets that value. Open tests/test_game.py and write the seeded-deck fixture first:
import random
import pytest
from poker.cards import Card, Deck
from poker.player import Player
from poker.game import PokerGame
from poker.score import best_of_seven, TWO_PAIR, ONE_PAIR
@pytest.fixture
def seeded_deck() -> Deck:
random.seed(42)
deck = Deck()
deck.shuffle()
return deck
def test_seeded_deck_is_reproducible() -> None:
random.seed(42)
a = Deck()
a.shuffle()
random.seed(42)
b = Deck()
b.shuffle()
assert a.cards == b.cardsrandom.seed(42) locks the shuffler to a deterministic sequence. Two runs of the seeded deck produce the exact same 52-card order. Now write the integration test that plays a full hand. The test needs to: seed the deck so the deal is predictable, replace input with a script of fixed answers (one per betting prompt, 8 prompts total for two players across four rounds), run PokerGame.play, and assert on the final state.
def scripted_input(answers: list[str]):
iterator = iter(answers)
def fake_input(_prompt: str = "") -> str:
return next(iterator)
return fake_input
def test_play_hand_runs_full_game_to_showdown(monkeypatch) -> None:
random.seed(42)
answers = ["c", "c", "c", "c", "c", "c", "c", "c"]
monkeypatch.setattr("builtins.input", scripted_input(answers))
aarit = Player(name="Aarit")
aditya = Player(name="Aditya")
game = PokerGame(players=[aarit, aditya])
winner = game.play()
assert winner.name in {"Aarit", "Aditya"}
assert len(game.community) == 0
assert game.pot == 0
assert aarit.chips + aditya.chips == 2000
assert len(aarit.hole) == 2
assert len(aditya.hole) == 2
assert any("won" in event for event in game.history)Eight c answers script every player to check on every street, so no chips move during betting and the hand goes to a clean showdown. The asserts cover every promise the game makes. The pot is back to 0 because showdown paid it out. The community list is empty because showdown cleared it. Total chips conserved at 2000 means no money was created or destroyed. Both players still have 2 hole cards. The history records the win. Run it:
pytest -v tests/test_game.pytests/test_game.py::test_seeded_deck_is_reproducible PASSED
tests/test_game.py::test_play_hand_runs_full_game_to_showdown PASSED
============= 2 passed in 0.03s =============A second integration test pins down the bet-and-fold path. Aarit bets on every street, Aditya folds on the flop, Aarit wins by default without a showdown comparison:
def test_play_hand_awards_pot_when_opponent_folds(monkeypatch) -> None:
random.seed(42)
answers = ["b", "c", "b", "f", "c", "c"]
monkeypatch.setattr("builtins.input", scripted_input(answers))
aarit = Player(name="Aarit")
aditya = Player(name="Aditya")
game = PokerGame(players=[aarit, aditya])
winner = game.play()
assert winner.name == "Aarit"
assert aarit.chips == 1000
assert aditya.chips == 1000
assert game.pot == 0
assert any("Aditya folded" in event for event in game.history)
assert any("Aarit won 100" in event for event in game.history)The answer list has six entries because the prompts trail off once Aditya folds. Pre-flop both players are prompted (Aarit bets, Aditya checks). Flop both are prompted (Aarit bets, Aditya folds). On the turn and river, betting_round skips Aditya via the if player.folded: continue guard, so only Aarit answers (he checks both). Aarit puts 50 in pre-flop and 50 on the flop, the pot reaches 100, and showdown hands all 100 back to him because he is the only live player. His stack lands at 1000 minus 100 bet plus 100 won, which is exactly where it started. Aditya never bet, so his 1000 is untouched. Total chips conserved.
The integration test composes Card, Deck, Player, scoring, and the game loop in a single run. If any of them regressed — if deal_community stopped burning a card, if showdown forgot to clear the pot, if best_of_seven ranked hands wrong — one of these assertions would fail. Unit tests pinpoint which line broke; integration tests prove the lines still work together.
The top of the pyramid is end-to-end tests. An E2E test treats your program as a black box and drives it the way a real user would. For the poker game, the unit and integration tests both call Python functions directly — the integration test even patched input instead of typing in a real terminal. An E2E test would launch python main.py as a real subprocess, pipe c\nc\nc\nc\nc\nc\nc\nc\n into its stdin, capture its stdout, and assert that the printed report says someone won the pot. The test catches things the lower tiers cannot: the pip install -e . step worked, the main.py entry point exists, the package imports resolve at startup.
E2E tests are slow. Spawning a subprocess takes hundreds of milliseconds per test, where unit tests measure in microseconds. They are also brittle — change the printed format and every E2E test breaks even though the logic is fine. The pyramid says: write hundreds of unit tests, dozens of integration tests, and a handful of E2E tests. The handful is enough to catch the assembly errors that integration tests miss, without paying the speed and brittleness tax for every code path.
The poker game's E2E surface is small enough that the integration tests carry most of the weight. The chatbot lesson at the end of the site builds something where the E2E layer is the natural fit: you want to know that the deployed CLI, talking to a real LLM, with a real .env file, returns the expected response to a real user question. We come back to E2E there.
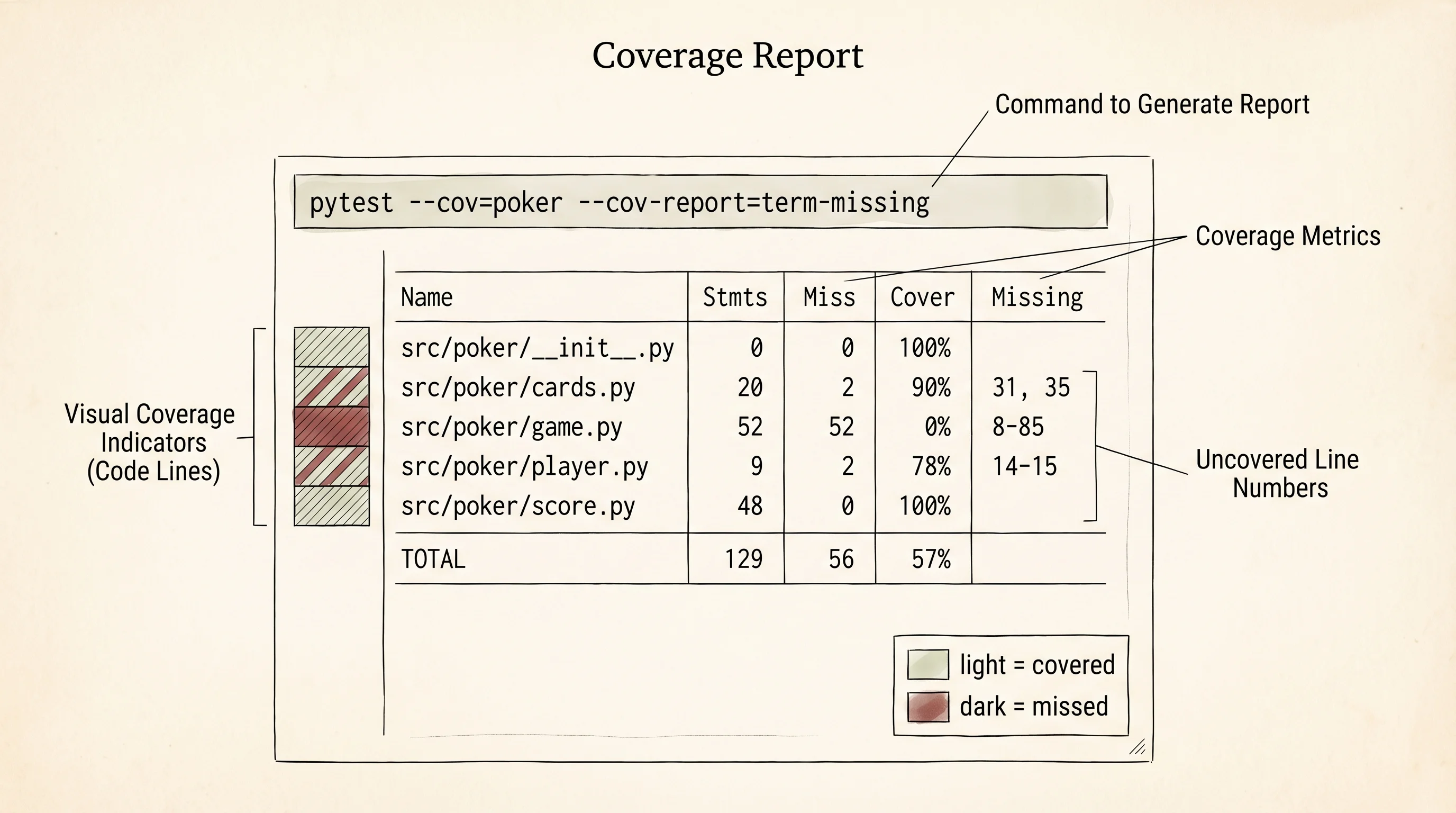
A passing test suite is a floor, not a ceiling. Coverage measures how many lines of your code were actually run by your tests. A line that was never hit during testing is a line you are trusting on faith. The pytest-cov plugin you installed earlier tells you the ratio:
pytest --cov=poker --cov-report=term-missingOutput:
Name Stmts Miss Cover Missing
--------------------------------------------------------
src/poker/__init__.py 0 0 100%
src/poker/cards.py 20 1 95% 29
src/poker/game.py 52 2 96% 62-63
src/poker/player.py 9 0 100%
src/poker/score.py 48 0 100%
--------------------------------------------------------
TOTAL 129 3 98%The unit tests covered score.py end to end. The integration tests dragged cards.py, player.py, and almost all of game.py along for the ride. The 2 lines still missing in game.py are the early-fold branch of showdown for the case where every other player folded but the live winner was determined inside the betting round — a code path the existing tests did not script. Adding one more integration test where Aditya folds pre-flop would close the gap. This is the coverage report you read every time a pull request lands. A drop in coverage means somebody added code without adding a spotter.
You have unit tests guarding every scoring rule, integration tests guarding the full hand flow, and a coverage number that tells you where the spotters are thin. The thing your tests do not yet guard is the bet outside the program — the install step, the entry point, the printed output a real human reads. The chatbot lesson handles that, because a chatbot has nothing to test except its end-to-end conversation with a real model. Before you write more spotters, the next bottleneck is bigger: every project so far has copied src/poker/ into a folder. Real reuse means turning the module into a library that any project can install with one command.