Apple Silicon and Unified Memory
Two cooks share one kitchen but each one keeps their own pantry. The grill cook stocks meat, the pastry cook stocks flour and sugar, and any time a dish needs both — short ribs braised in a wine reduction with a chocolate glaze — somebody has to walk ingredients across the room. The walk is slow. The walk is where the dish gets cold. Every PC built since 1981 cooks this way. The CPU has one pantry called system RAM. The graphics card has its own pantry on the other side of the motherboard called VRAM. When the CPU wants the GPU to draw something, it copies the bytes across a narrow hallway called PCIe and waits.
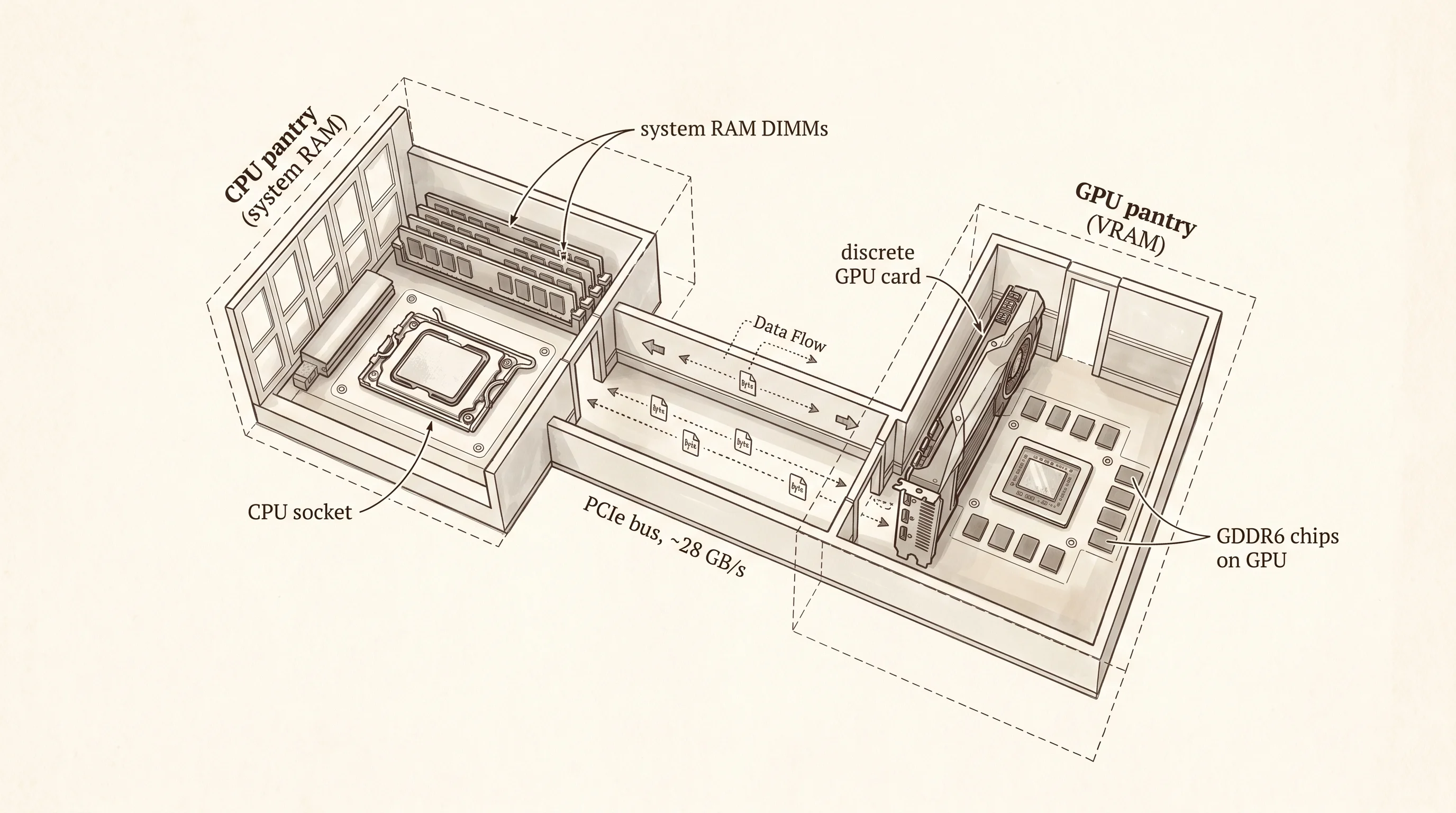
The split-pantry kitchen was an accident of history. In the 1980s graphics chips were add-on cards from companies like ATI and S3 that plugged into a motherboard slot. Nobody designed VRAM and system RAM as one thing because nobody made both. By the time NVIDIA owned the GPU world and Intel owned the CPU world, neither side wanted to give up its pantry. The hallway between them — first AGP, then PCIe — got wider every few years, but it was still a hallway. PCIe 4.0 x16 on a 2023 gaming rig moves about 28 gigabytes a second. The GPU's local VRAM moves a thousand. The hallway is forty times slower than the room.
Apple did something different because Apple could. The first M1 chip shipped in November 2020, the work of a team led by Johny Srouji that Apple had been quietly building since they bought the chip designer PA Semi in 2008. Srouji's team had already done the iPhone chips — the A-series — and on those they had been forced from the start to share memory across CPU and GPU because a phone has no room for a separate VRAM pantry. When they scaled that design up to a laptop, they kept the shared pantry. One pool of LPDDR5 memory, soldered to the same package as the CPU and the GPU and the Neural Engine, and a memory controller wide enough that every block on the chip can read from it at full speed.
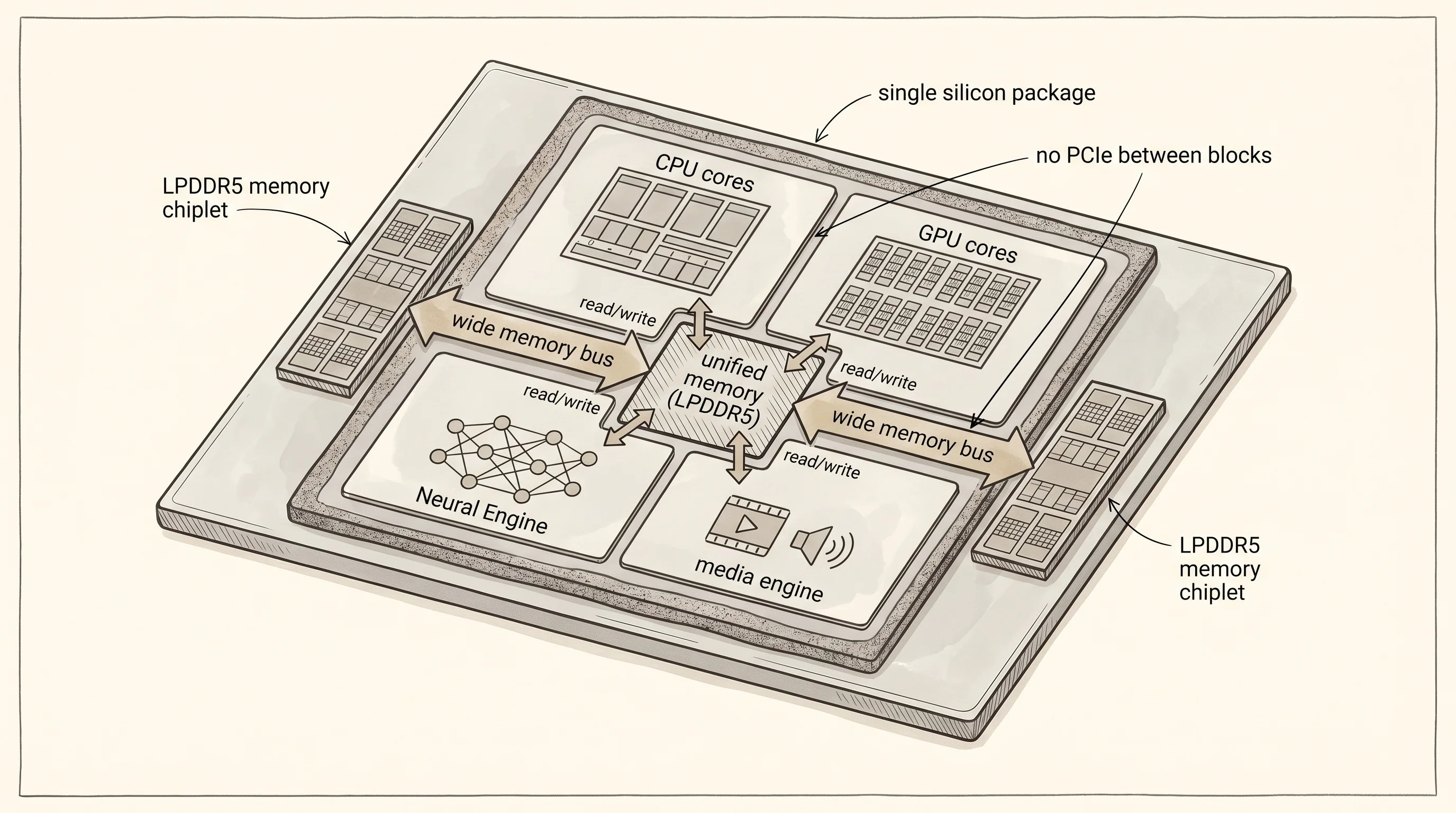
The reader who has only ever used a PC may not feel why this matters. Here is a Rust program that lays out four machines side by side. Two are split-pantry, two are unified. For each one it lists how fast the CPU can read its RAM, how fast the GPU can read its memory, and how many times you have to copy a 14-gigabyte language model before the GPU can run it.
struct Machine {
name: &'static str,
year: u16,
cpu_ram_gbps: u32,
gpu_vram_gbps: u32,
copies_to_run_model: u32,
}
const MACHINES: &[Machine] = &[
Machine {
name: "PC: Intel i9 + RTX 4090",
year: 2023,
cpu_ram_gbps: 90,
gpu_vram_gbps: 1008,
copies_to_run_model: 2,
},
Machine {
name: "Mac mini Intel + AMD GPU",
year: 2018,
cpu_ram_gbps: 38,
gpu_vram_gbps: 84,
copies_to_run_model: 2,
},
Machine {
name: "Mac mini M1 (unified)",
year: 2020,
cpu_ram_gbps: 68,
gpu_vram_gbps: 68,
copies_to_run_model: 0,
},
Machine {
name: "MacBook Pro M3 Max (unified)",
year: 2023,
cpu_ram_gbps: 400,
gpu_vram_gbps: 400,
copies_to_run_model: 0,
},
];fn main() {
println!("how memory moves on four machines");
println!(
"{:<32} {:<5} {:>10} {:>10} {:>8}",
"machine", "year", "cpu GB/s", "gpu GB/s", "copies",
);
println!("{}", "-".repeat(70));
for m in MACHINES {
println!(
"{:<32} {:<5} {:>10} {:>10} {:>8}",
m.name, m.year, m.cpu_ram_gbps, m.gpu_vram_gbps, m.copies_to_run_model,
);
}
println!("{}", "-".repeat(70));
println!();
println!("loading a 7B model (14 GB) onto the GPU:");
for m in MACHINES {
let seconds = if m.copies_to_run_model == 0 {
0.0
} else {
// PCIe 4.0 x16 tops out near 28 GB/s in practice; one copy of 14 GB.
14.0 / 28.0 * m.copies_to_run_model as f32
};
let note = if m.copies_to_run_model == 0 {
"no copy, GPU reads the same bytes"
} else {
"copy from RAM to VRAM over PCIe"
};
println!(" {:<32} {:>4.2} s {}", m.name, seconds, note);
}
}Build it and run it.
how memory moves on four machines
machine year cpu GB/s gpu GB/s copies
----------------------------------------------------------------------
PC: Intel i9 + RTX 4090 2023 90 1008 2
Mac mini Intel + AMD GPU 2018 38 84 2
Mac mini M1 (unified) 2020 68 68 0
MacBook Pro M3 Max (unified) 2023 400 400 0
----------------------------------------------------------------------
loading a 7B model (14 GB) onto the GPU:
PC: Intel i9 + RTX 4090 1.00 s copy from RAM to VRAM over PCIe
Mac mini Intel + AMD GPU 1.00 s copy from RAM to VRAM over PCIe
Mac mini M1 (unified) 0.00 s no copy, GPU reads the same bytes
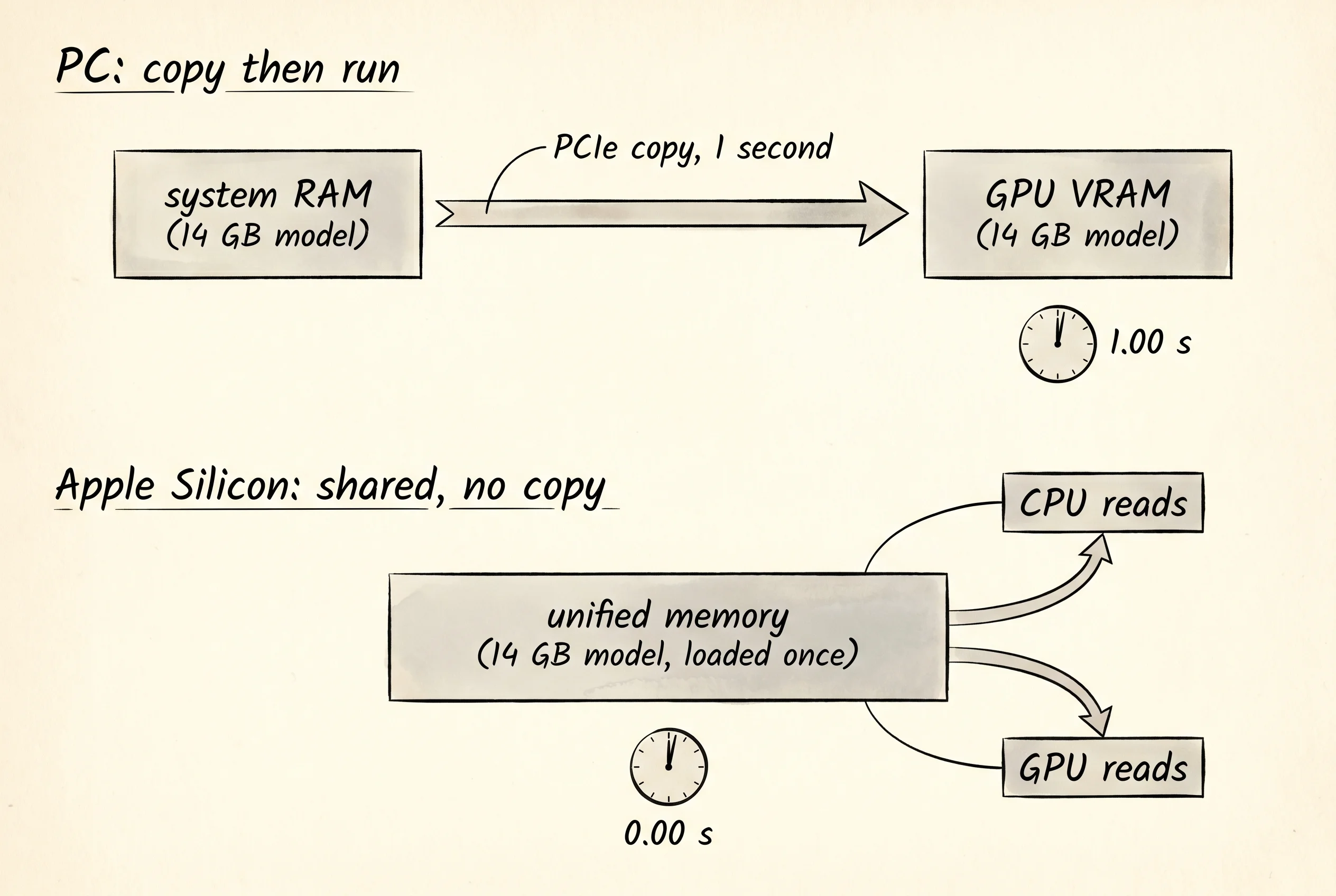
MacBook Pro M3 Max (unified) 0.00 s no copy, GPU reads the same bytesLook at the bottom block. On the PC and the Intel Mac, loading the model costs a full second of copying bytes from RAM to VRAM through the PCIe hallway. On the M1 and the M3 Max, the copy is zero seconds because there is no copy — the GPU just starts reading the same bytes the CPU loaded. For a workload that loads a model once and runs it forever, the second of copy time barely matters. For the workloads Apple actually cares about — the Photos app deciding to recognize a face the moment you scroll past it, the Mail app summarizing a thread the second it lands, an iPhone running a local language model on a battery — the copy is the whole game. You cannot fit a separate VRAM chip in an iPhone. You cannot afford the power draw of a PCIe bus when the battery is the budget.
The unified pantry also lets the M-series put more memory into the GPU than any consumer GPU on earth. An RTX 4090 ships with 24 gigabytes of VRAM and that is the ceiling. A MacBook Pro M3 Max configured with 128 gigabytes of unified memory can hand all 128 to the GPU if it wants to, because the GPU is just another resident of the same pantry. This is why researchers running 70-billion-parameter language models at home in 2024 buy Macs and not gaming PCs — the model literally does not fit in a 4090's pantry, but it fits in a Mac's shared one. The split-pantry world has a hard ceiling. The unified world has the same ceiling as the room.
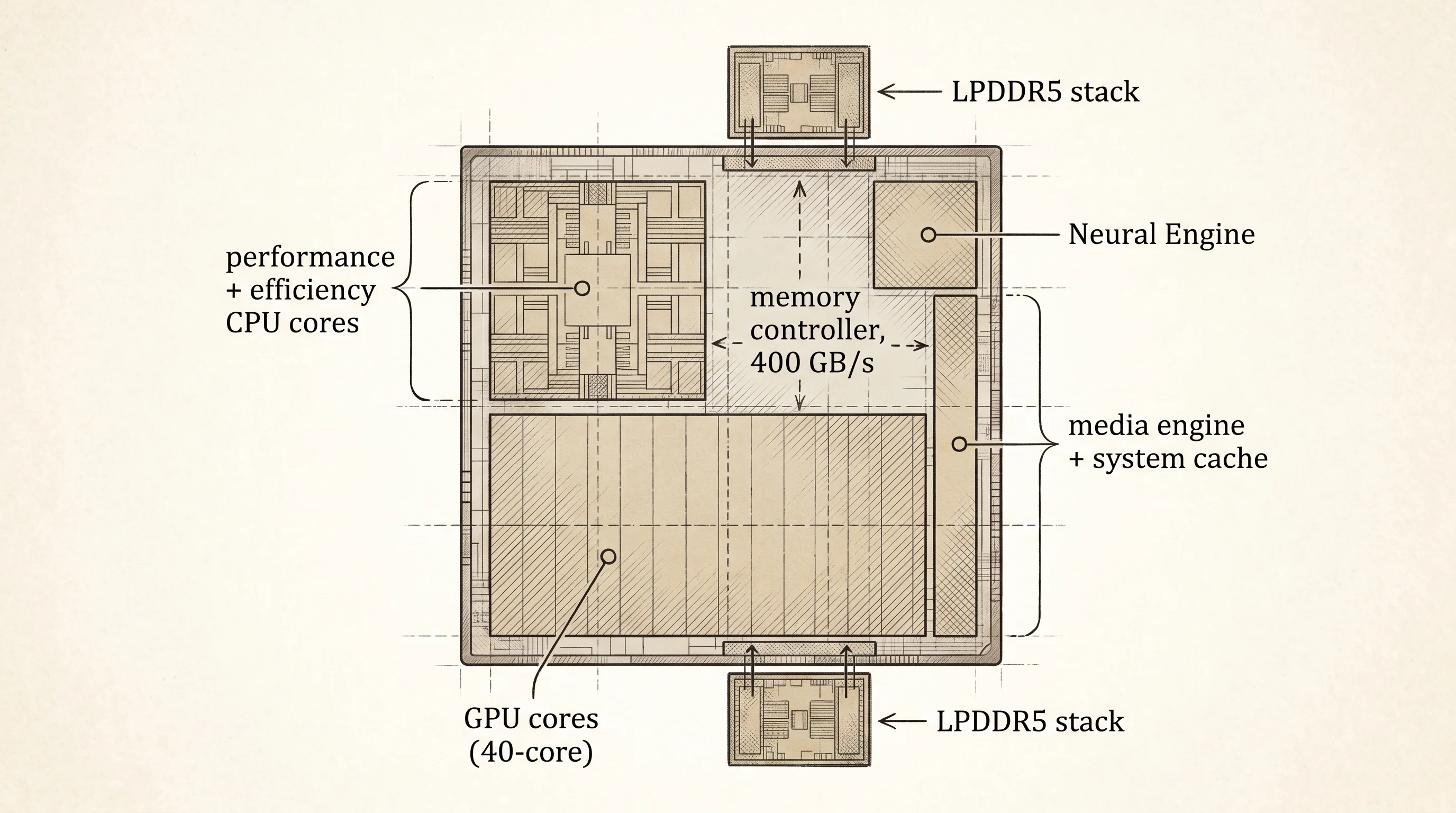
The price of the unified pantry is that you can never upgrade it. The RAM is soldered into the same silicon package as the CPU, so the 16-gigabyte model you bought in 2020 is a 16-gigabyte machine until you replace the whole laptop. PC builders trade that flexibility back for the hallway. Apple's bet — and so far it has been right — is that most buyers will take the speed and accept the locked size.
The next bottleneck is that a single chip, even with one fast pantry, still only has so many cores; the next lesson is about an instruction set anyone can implement on their own silicon without paying Apple or Intel a cent.