RISC-V
Every instruction set before RISC-V belonged to a company. x86 is Intel's. ARM is the Arm holding company's. MIPS, SPARC, PowerPC — pick any chip you have ever used and a corporate lawyer somewhere owns the rulebook that tells silicon how to add two numbers. RISC-V is the first ISA that ships like a cookbook. The recipe pages are public. Anyone can cook from them, sell what they cook, change the recipe in their own kitchen, and never send a check to the author. That is the whole story, and it took fifty years for the rest of the industry to admit it had to happen.

The cookbook got written in a Berkeley lab in 2010. Krste Asanović, Andrew Waterman, Yunsup Lee, and David Patterson were teaching a graduate computer architecture class and kept hitting the same wall. To do real chip work the students needed a clean instruction set, and every clean instruction set was either dead, expensive to license, or so layered with patents that you could not safely tape out silicon from it. Patterson had spent his career arguing that simple beats complex — he co-wrote the original RISC paper in 1980 and watched ARM prove him right in everyone's pocket. So the lab wrote their own ISA from scratch, called it the fifth in their RISC lineage, and put it under a BSD license. By 2015 the RISC-V Foundation was incorporated in Switzerland, and the founders moved the headquarters out of the US in 2020 specifically so no single government could ever pull export-control strings on the standard.
What sits in that cookbook is small. The base integer ISA, the one called RV32I, has 47 instructions. Every instruction is exactly 32 bits wide, every one packs into one of six fixed shapes, and every shape names its slots in the same places. A chip that decodes one instruction knows where to look for the destination register in every other instruction, because byte 11 through 7 is always the destination register slot. That regularity is the whole RISC bet. Decoders get small. Pipelines get short. The thing you save in silicon you spend on running faster.

The six formats earn letters: R for register-register math, I for an immediate value baked into the instruction, S for storing to memory, B for branching on a comparison, U for an upper-immediate that loads a constant into the top of a register, and J for an unconditional jump. Type the formats into a Rust program and let the program print the layout so you can stare at it.
struct Format {
name: &'static str,
layout: &'static str,
example: &'static str,
use_case: &'static str,
}
const FORMATS: &[Format] = &[
Format {
name: "R",
layout: "funct7[7] | rs2[5] | rs1[5] | funct3[3] | rd[5] | opcode[7]",
example: "add x5, x6, x7",
use_case: "register-register math",
},
Format {
name: "I",
layout: "imm[12] | rs1[5] | funct3[3] | rd[5] | opcode[7]",
example: "addi x5, x6, 10",
use_case: "immediate, loads, jalr",
},
Format {
name: "S",
layout: "imm[7] | rs2[5] | rs1[5] | funct3[3] | imm[5] | opcode[7]",
example: "sw x5, 8(x6)",
use_case: "store to memory",
},
Format {
name: "B",
layout: "imm[7] | rs2[5] | rs1[5] | funct3[3] | imm[5] | opcode[7]",
example: "beq x5, x6, +12",
use_case: "conditional branch",
},
Format {
name: "U",
layout: "imm[20] | rd[5] | opcode[7]",
example: "lui x5, 0x12345",
use_case: "upper immediate",
},
Format {
name: "J",
layout: "imm[20] | rd[5] | opcode[7]",
example: "jal x1, +64",
use_case: "unconditional jump",
},
];The numbers in brackets are how many bits each slot eats. R-type uses all 32 bits across six slots. I-type collapses the two register slots and the two function-code slots into a single 12-bit immediate so the chip can carry a small number with the opcode itself. S and B share the same shape because storing to memory and branching to an address are the same shape of work — you have two registers and a small offset. U and J spend twenty whole bits on the immediate because loading a constant or jumping a long distance needs the room. Compile the program and read the table.
RV32I base instruction formats
------------------------------
fmt layout example use
R funct7[7] | rs2[5] | rs1[5] | funct3[3] | rd[5] | opcode[7] add x5, x6, x7 register-register math
I imm[12] | rs1[5] | funct3[3] | rd[5] | opcode[7] addi x5, x6, 10 immediate, loads, jalr
S imm[7] | rs2[5] | rs1[5] | funct3[3] | imm[5] | opcode[7] sw x5, 8(x6) store to memory
B imm[7] | rs2[5] | rs1[5] | funct3[3] | imm[5] | opcode[7] beq x5, x6, +12 conditional branch
U imm[20] | rd[5] | opcode[7] lui x5, 0x12345 upper immediate
J imm[20] | rd[5] | opcode[7] jal x1, +64 unconditional jump
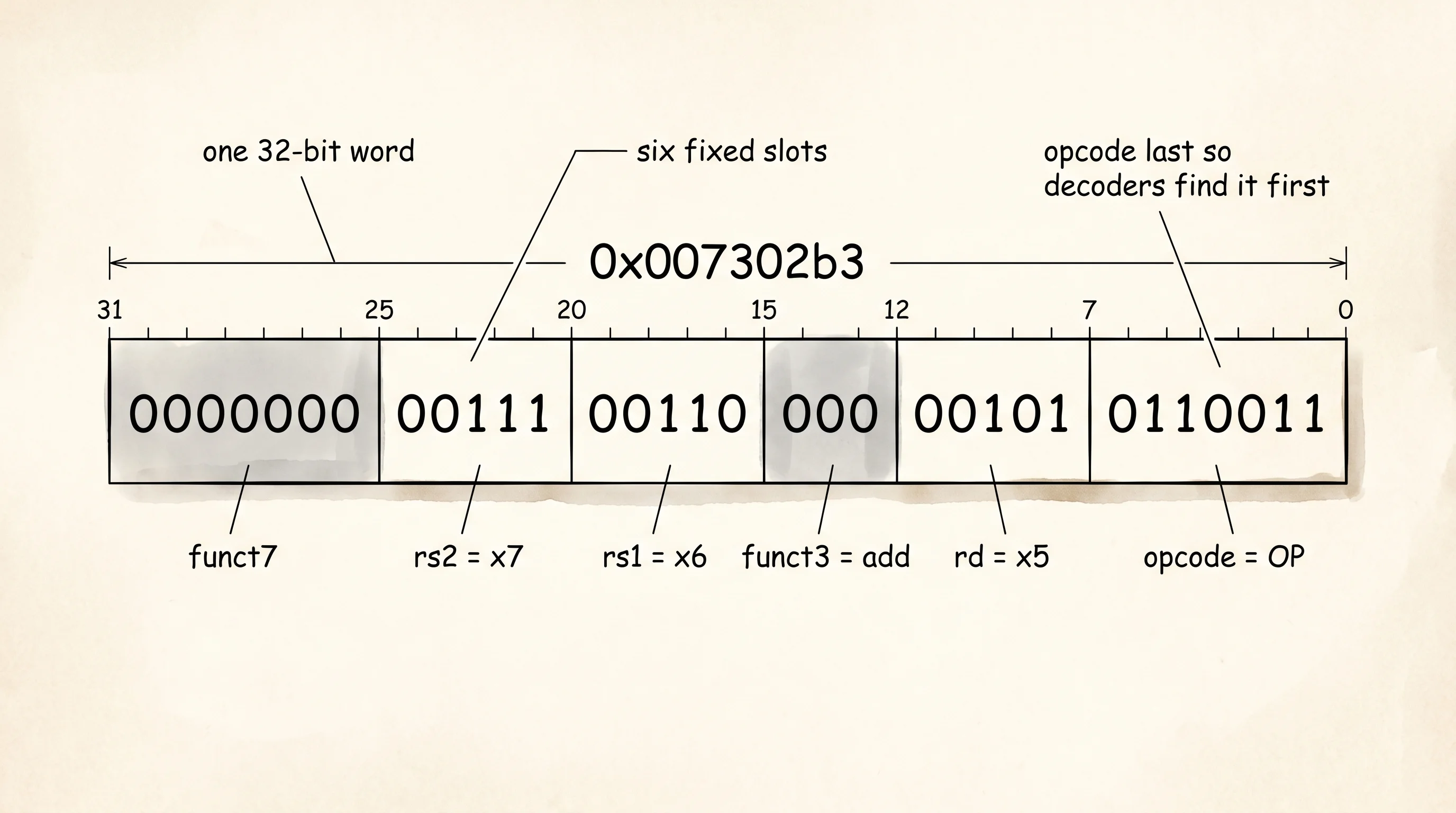
worked example: add x5, x6, x7
32-bit machine word: 0x007302b3
field bits value
funct7 31-25 0000000
rs2 24-20 00111 (x7)
rs1 19-15 00110 (x6)
funct3 14-12 000 (add)
rd 11-7 00101 (x5)
opcode 6-0 0110011 (OP)The second half of that output picks one real instruction and shows the bits. add x5, x6, x7 says take the contents of register 6, add the contents of register 7, store the sum in register 5. The chip sees the 32-bit word 0x007302b3. Read it from the right. The bottom seven bits, 0110011, are the opcode that means "integer register-register operation." The next five bits, 00101, are the binary number 5 — that is the destination register x5. Three bits of function code say "add." Five more bits hold 6. Five more hold 7. Seven top bits of secondary function code are all zero. The chip walks across the word, plucks the right bits from the right slots, and the add happens in one cycle. The encoder is a one-line Rust function that ORs the fields together.
fn encode_add(rd: u32, rs1: u32, rs2: u32) -> u32 {
let opcode: u32 = 0b0110011;
let funct3: u32 = 0b000;
let funct7: u32 = 0b0000000;
(funct7 << 25) | (rs2 << 20) | (rs1 << 15) | (funct3 << 12) | (rd << 7) | opcode
}
fn bits(word: u32, hi: u32, lo: u32) -> String {
let mut out = String::new();
let mut i = hi;
loop { // allow:loop has explicit break on lo
let bit = (word >> i) & 1;
out.push(if bit == 1 { '1' } else { '0' });
if i == lo {
break;
}
i -= 1;
}
out
}
That is the part the cookbook is open about. The clever part is what the cookbook leaves out. RV32I is a base. The standard then defines optional extensions — M for integer multiply and divide, A for atomics, F for single-precision floats, D for double, C for compressed 16-bit instructions, V for vectors. A small embedded chip can ship the base alone and pass certification. A datacenter chip can ship the base plus M, A, F, D, C, and V and pass the same certification. The cookbook standardizes the interface and lets the chip designer choose which chapters to cook from. Nobody pays a license fee in either direction.
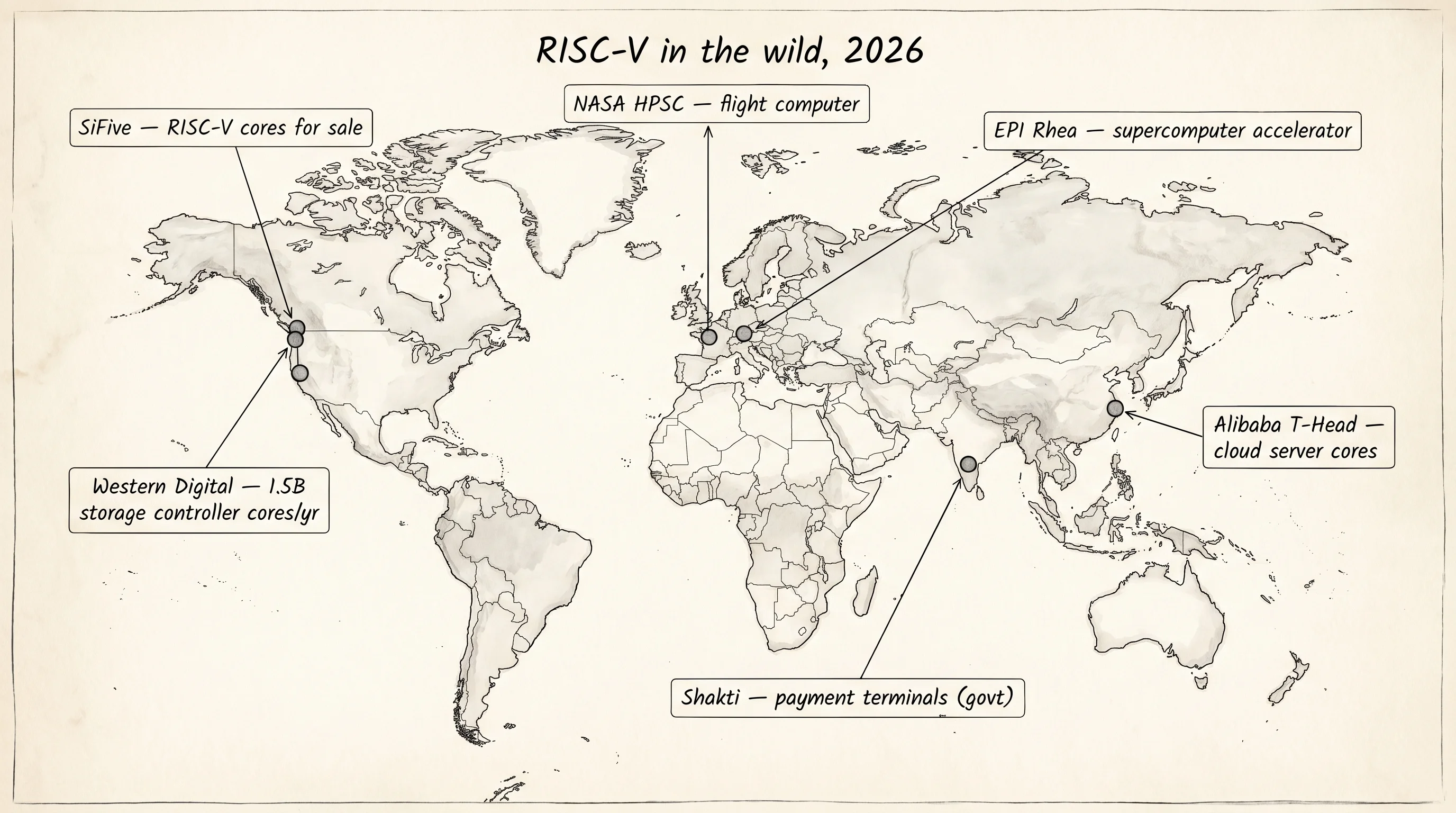
That arrangement is why the industry moved. India's central government picked RISC-V for the Shakti family of processors that ship inside the country's payment terminals. The European Processor Initiative chose RISC-V for the cores around its Rhea supercomputer accelerator. Western Digital announced in 2018 that every controller chip inside its hard drives and SSDs — a billion-and-a-half chips a year — would migrate to RISC-V cores so the company could stop paying ARM royalties on storage controllers that customers never see. SiFive, the startup the Berkeley team founded, sells RISC-V cores to anyone with a chip design. Alibaba's T-Head designs ship in Chinese cloud servers. NASA chose a RISC-V core, the HPSC, as the flight computer for its next deep-space missions because the agency wanted source it could audit without an export license.
The thing the cookbook does not yet promise is the high end. RISC-V chips today win in places where price and openness matter more than raw single-thread speed — microcontrollers, storage controllers, accelerators, classroom FPGAs, anywhere the chip designer wants to add custom instructions without asking permission. The fastest cores on the planet are still ARM and x86, with twenty more years of pipeline tuning behind them. Whether RISC-V closes that gap depends on whether the next ten years of silicon money goes into the open base or stays inside the proprietary ones. The trend line points one way. The cookbook is open. The next lesson leaves silicon entirely and looks at the work the chip does most — moving numbers in and out of memory fast enough to keep the cores fed.