ECS, EKS, Fargate
A food truck shows up at a parking lot, plugs into a generator, serves lunch, and rolls away by dinner. The truck is the application. The kitchen inside is everything the application needs to cook — the stove, the pots, the spice rack. The parking lot is the place the truck sits while it serves customers. Containers work the same way. A container is a self-contained kitchen the app brings with it, and the cloud provider rents you the parking lot. The whole game is deciding who owns the lot, who plugs in the generator, and who tows the truck away when the day is done.
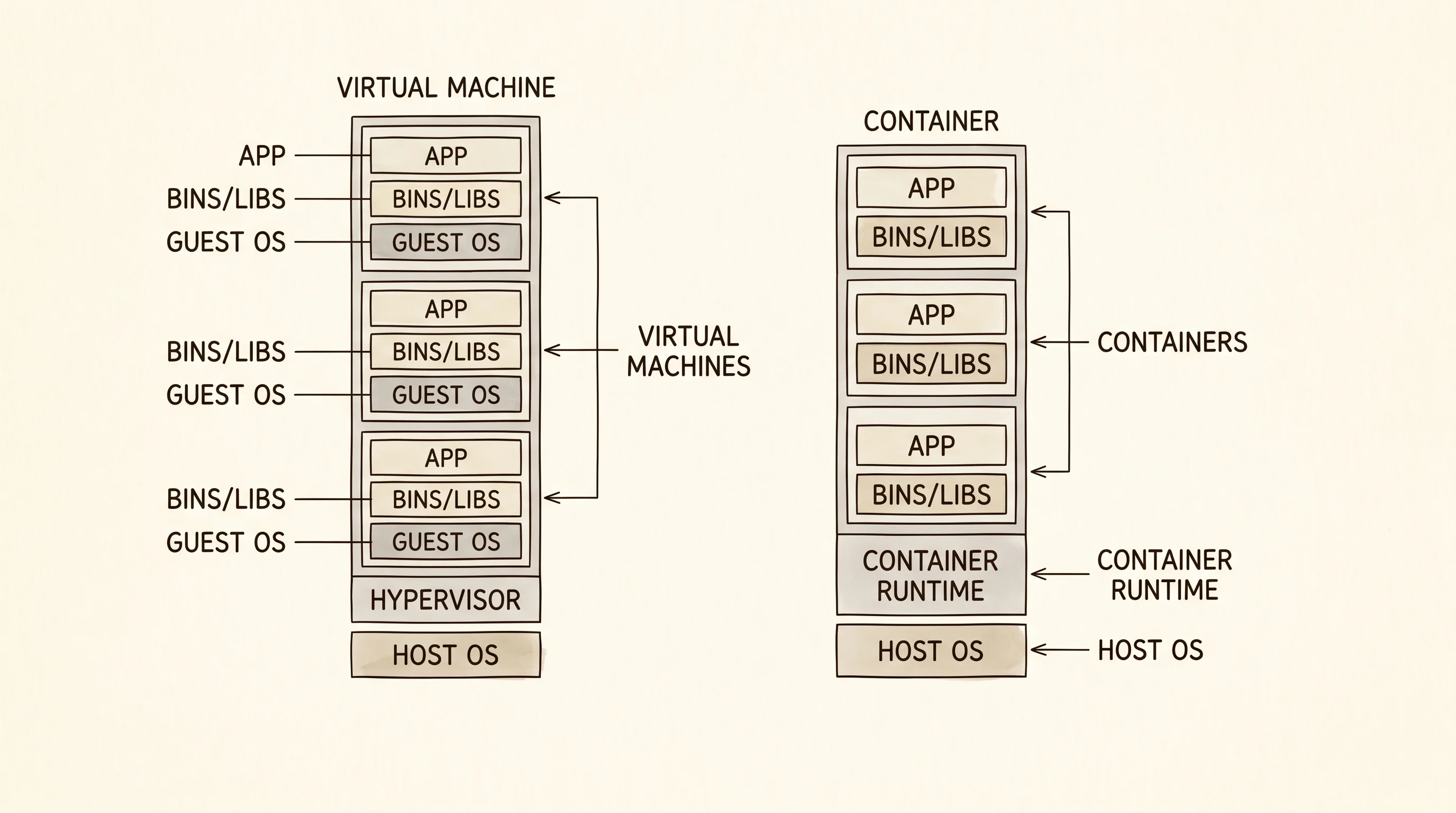
Docker shipped in 2013 and the container idea exploded. Within a year every team at Amazon had a folder of docker run commands they were sshing onto EC2 boxes by hand, and the bottleneck became obvious — you could build the truck in 10 minutes, but parking a fleet of them took a week of yak-shaving with init scripts and load balancers. AWS launched ECS in 2014 as the answer. The Elastic Container Service was the parking-lot manager. You handed it a description of the truck — the image, the cpu, the memory, the port — and ECS found a spot, parked the truck, and replaced it if the truck broke down. The description got a name: the Task Definition.
A Task Definition is a recipe card. It does not run anything on its own. It says "this is what one running instance of the truck looks like." A Task is the running truck itself, started from the recipe. A Service is the rule that says "keep three of these trucks parked at all times, and if one drives off, start another." A Cluster is the parking lot — a named pool of compute that the Service draws from. Four words, four sizes. The trick is that everything else in the system flows through those four shapes.
#[derive(Copy, Clone, PartialEq, Eq)]
enum Runtime {
Ec2,
Fargate,
}
struct Task {
id: u32,
image: &'static str,
runtime: Runtime,
cpu: u32,
mem: u32,
}
struct Cluster {
name: &'static str,
tasks: Vec<Task>,
next_id: u32,
}Read the types in order. A Runtime is exactly one of two things — Ec2, meaning you own the parking lot and AWS just helps you park, or Fargate, meaning AWS owns the lot and bills you by the minute the truck is plugged in. A Task is the running truck — it has an id, an image name, a runtime, and the cpu and memory it reserved. A Cluster is the lot itself, holding the list of currently-running tasks and the next id it will hand out. These shapes mirror the ones AWS uses, just shrunk down enough to fit on a page.
The control surface is a handful of methods that the rest of the system goes through.
impl Cluster {
fn new(name: &'static str) -> Self {
Self {
name,
tasks: Vec::new(),
next_id: 1,
}
}
fn launch(&mut self, image: &'static str, runtime: Runtime, cpu: u32, mem: u32) -> u32 {
let id = self.next_id;
self.next_id += 1;
self.tasks.push(Task {
id,
image,
runtime,
cpu,
mem,
});
id
}
fn scale_to(&mut self, image: &'static str, runtime: Runtime, cpu: u32, mem: u32, count: usize) {
let current = self.tasks.iter().filter(|t| t.image == image).count();
if count > current {
for _ in current..count {
self.launch(image, runtime, cpu, mem);
}
}
}
fn kill(&mut self, id: u32) -> Result<(), &'static str> {
let before = self.tasks.len();
self.tasks.retain(|t| t.id != id);
if self.tasks.len() == before {
return Err("no such task");
}
Ok(())
}
}
fn runtime_label(r: Runtime) -> &'static str {
match r {
Runtime::Ec2 => "EC2",
Runtime::Fargate => "Fargate",
}
}
fn render(c: &Cluster) -> String {
let mut out = String::new();
out.push_str(&format!("cluster: {} ({} tasks)\n", c.name, c.tasks.len()));
for t in &c.tasks {
out.push_str(&format!(
" task {:>2} image={:<10} on={:<7} cpu={} mem={}MB\n",
t.id,
t.image,
runtime_label(t.runtime),
t.cpu,
t.mem
));
}
out
}launch is the API call that hands ECS a recipe card. It picks an id, builds the Task, and parks it on the cluster. scale_to is the Service rule — you tell it "I want 5 of these images running" and it works out the gap and launches the difference. kill is the tow truck — it takes an id, removes the task, and returns a Result because the id might not match anything. The order matters. scale_to calls launch because scaling up is just launching more of the same thing, and a real Service does exactly that under the hood — it never reinvents the launch path, it just calls it in a loop until the desired count is reached.

Three years after ECS shipped, AWS noticed that the parking-lot half of the problem was where most teams still got stuck. You could describe the truck perfectly, but you still had to keep a fleet of EC2 boxes patched, sized right, and standing by — and the boxes sat half-empty most of the time because nobody could predict the next traffic spike. In 2017 they shipped Fargate, which billed teams for the truck-minute instead of the lot-minute. The cluster stopped being a list of boxes you owned and became an abstract handle that AWS sized on demand. You still wrote the same Task Definition. You still set up the same Service. The only thing that changed was the Runtime field on the recipe card.
EKS arrived a year later, in 2018, after Kubernetes had won the open-source war and customers were threatening to leave AWS rather than rewrite their YAML to ECS-flavored JSON. EKS is the same parking-lot service but with a Kubernetes control plane instead of an AWS-native one. You file the same Task Definition shape, except now it is called a Pod Spec, and the Service is called a Deployment, and the Cluster comes with kubectl instead of the AWS console. The reason to pick EKS over ECS is almost never technical — it is that your team already speaks Kubernetes from a previous job and rewriting that knowledge costs more than the EKS premium.
Run the cluster model through a lifecycle the same way a real Service would — launch a few tasks, scale one of the images up, kill one off, watch the table reshape each time.
fn show_types() {
let cluster = Cluster::new("prod-web");
println!("--- empty cluster ---");
print!("{}", render(&cluster));
println!();
}
fn show_lifecycle() {
let mut cluster = Cluster::new("prod-web");
println!("--- launch 3 tasks ---");
cluster.launch("nginx", Runtime::Fargate, 256, 512);
cluster.launch("nginx", Runtime::Fargate, 256, 512);
cluster.launch("redis", Runtime::Ec2, 512, 1024);
print!("{}", render(&cluster));
println!();
println!("--- scale nginx to 5 ---");
cluster.scale_to("nginx", Runtime::Fargate, 256, 512, 5);
print!("{}", render(&cluster));
println!();
println!("--- kill task 3 ---");
match cluster.kill(3) {
Ok(()) => println!("killed task 3"),
Err(why) => println!("kill failed: {}", why),
}
print!("{}", render(&cluster));
println!();
}
fn show_comparison() {
println!("--- where each flavor fits ---");
println!("ECS on EC2 you patch the boxes, you save money at scale");
println!("ECS on Fargate AWS runs the boxes, you pay per task-second");
println!("EKS same trade, but the control plane is Kubernetes");
}--- empty cluster ---
cluster: prod-web (0 tasks)
--- launch 3 tasks ---
cluster: prod-web (3 tasks)
task 1 image=nginx on=Fargate cpu=256 mem=512MB
task 2 image=nginx on=Fargate cpu=256 mem=512MB
task 3 image=redis on=EC2 cpu=512 mem=1024MB
--- scale nginx to 5 ---
cluster: prod-web (6 tasks)
task 1 image=nginx on=Fargate cpu=256 mem=512MB
task 2 image=nginx on=Fargate cpu=256 mem=512MB
task 3 image=redis on=EC2 cpu=512 mem=1024MB
task 4 image=nginx on=Fargate cpu=256 mem=512MB
task 5 image=nginx on=Fargate cpu=256 mem=512MB
task 6 image=nginx on=Fargate cpu=256 mem=512MB
--- kill task 3 ---
killed task 3
cluster: prod-web (5 tasks)
task 1 image=nginx on=Fargate cpu=256 mem=512MB
task 2 image=nginx on=Fargate cpu=256 mem=512MB
task 4 image=nginx on=Fargate cpu=256 mem=512MB
task 5 image=nginx on=Fargate cpu=256 mem=512MB
task 6 image=nginx on=Fargate cpu=256 mem=512MB
--- where each flavor fits ---
ECS on EC2 you patch the boxes, you save money at scale
ECS on Fargate AWS runs the boxes, you pay per task-second
EKS same trade, but the control plane is KubernetesRead the output top to bottom. The empty cluster prints with zero tasks because nothing has been launched yet. The first launch round drops three tasks on the cluster — two nginx running on Fargate and one redis running on EC2. The mix is deliberate and AWS supports it; one cluster can hold tasks on both runtimes at the same time. The scale-to-5 step bumps nginx from 2 to 5 by launching three more, leaving the total at 6 — the scale function only added the gap. The kill step removes task 3, which was the redis, and the table reshapes around the hole.
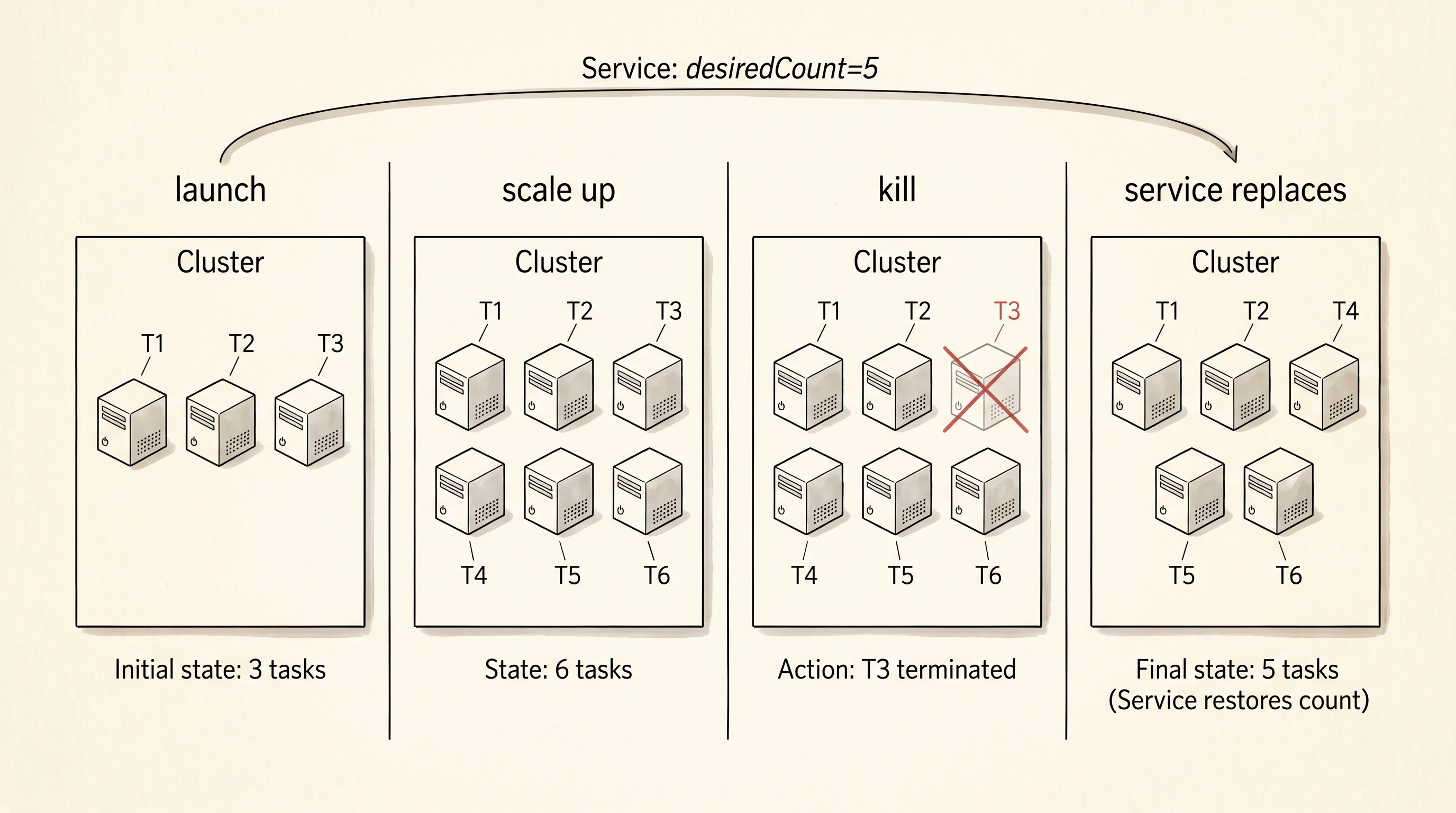
One question worth asking — why does scale_to only ever launch new tasks instead of also killing extras when the count is too high? The reason is that a real Service does scale both ways, but the scale-down side has to pick which specific tasks to kill, and that choice depends on connection draining, deploy version, and which availability zone is overloaded. A toy model that scales both ways without those checks would be lying about what ECS does. Showing only the launch side keeps the story honest and matches the most common path teams hit in practice.
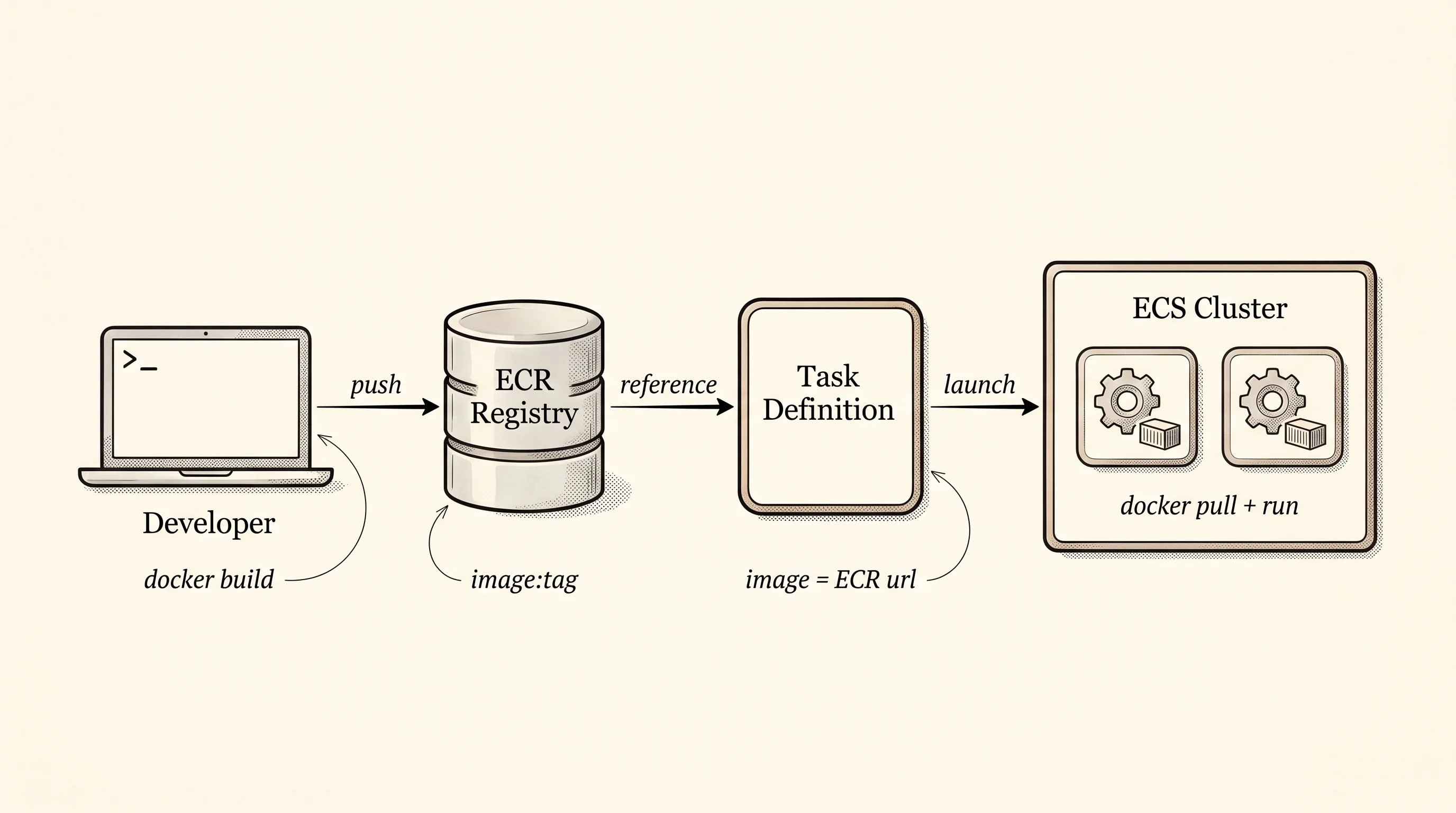
The thing this design cannot do on its own is build the truck in the first place. The image name "nginx" in the recipe card has to point at a real, versioned, signed container image sitting in a registry that the cluster can pull from — which is what Elastic Container Registry exists to solve.