Dynamic Programming
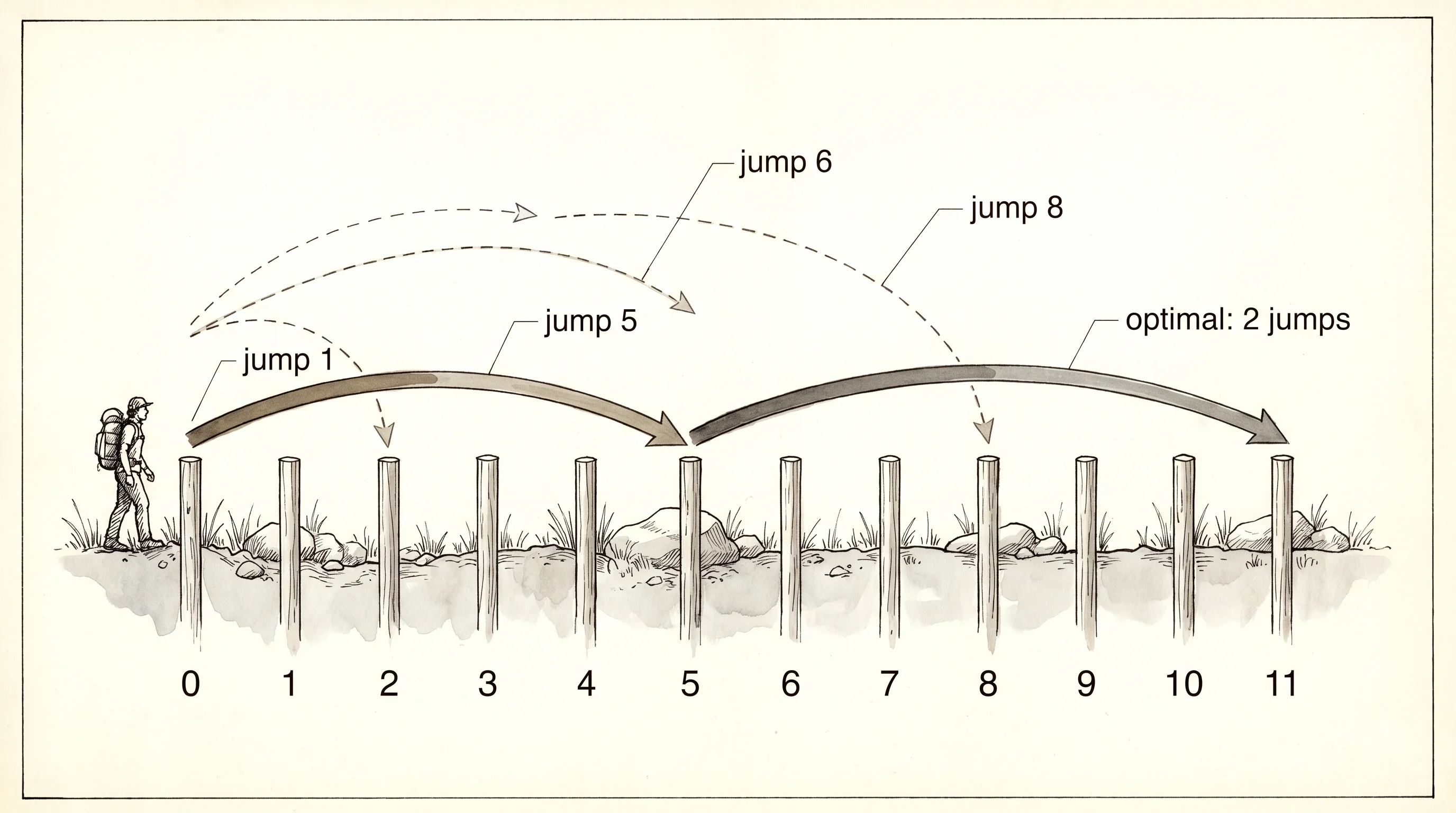
Dynamic programming is a hiking trail with numbered checkpoints. The trailhead is checkpoint 0. The summit is checkpoint 11. Between them the trail has 10 marked posts, and the only moves your legs know are jumps of length 1, 5, 6, or 8. The question the trail asks is the question every dynamic programming problem asks. What is the fewest jumps you need to land exactly on the summit? Stand at the trailhead and try to solve it by guessing. You will burn the afternoon. The trick that turns the puzzle into a stroll is realizing that the cheapest path to checkpoint 11 is the cheapest path to one of 10, 6, 5, or 3, plus one final jump. The cheapest path to each of those is the cheapest path to four smaller checkpoints, plus one. The whole problem unwraps into one tiny question repeated 11 times. Solve the small questions first, write the answers on a board, and the big question solves itself by looking up the board.
The word "dynamic" in the name fits nothing about the technique, and that is on purpose. Richard Bellman was a mathematician at the RAND Corporation in 1953, working on optimal control problems for the Air Force. His boss was Charles Wilson, the Secretary of Defense, a man who hated research. Wilson would walk into a room, see a chalkboard with the word "research" on it, and start glaring. Bellman needed a phrase to describe the recursive optimization machinery he was inventing — something that would survive a budget hearing. He picked "dynamic programming" because it sounded active and industrial. "Dynamic" because the problems unfolded over stages of time. "Programming" because the Air Force used the word to mean planning, not coding. The name stuck for 70 years even though every algorithm under it could just as well be called "remembered recursion." Bellman wrote in his autobiography that he picked the words because nobody, not even a senator, could object to them.
The trail problem has a name. It is called the coin change problem. The checkpoints are dollar amounts, the jumps are coin denominations, and the question is the minimum number of coins that add up to a target. The smallest honest version uses coins of 1, 5, 6, and 8 to make 11 cents. The reason that combination is honest is that the greedy answer — keep grabbing the biggest coin that fits — gives you 8 + 1 + 1 + 1, four coins, which is wrong. The right answer is 5 + 6, two coins. Greedy fails because picking the biggest coin first burns through the budget without leaving room for a clean finish. Dynamic programming exists for problems greedy gets wrong.
Try the naive version first. Start from the target and ask the same question recursively at every smaller amount. At amount 11, try each coin, recurse on the leftover, take the best. At amount 6, do the same. At amount 5, the same again. Walk the recursion tree on paper for a minute and you will spot the problem — the same checkpoint gets visited again and again from different branches, and each visit starts the whole subproblem from scratch.
const COINS: [u32; 4] = [1, 5, 6, 8];
const TARGET: u32 = 11;
fn naive_min_coins(amount: u32, call_count: &mut u64) -> u32 {
*call_count += 1;
if amount == 0 {
return 0;
}
let mut best = u32::MAX;
for &coin in COINS.iter() {
if coin <= amount {
let sub = naive_min_coins(amount - coin, call_count);
if sub != u32::MAX && sub + 1 < best {
best = sub + 1;
}
}
}
best
}The function takes the amount and a mutable counter, bumps the counter on every entry, then loops through the coin denominations. For each coin that fits, it recurses on the leftover and keeps the best result. The base case is amount 0, which costs 0 coins. Run it for amount 11 and the counter tells you how many times the function ran. The number is not 11. It is not 50. It is 77. The recursion fans out so widely that the same small amounts get recomputed dozens of times, and the function spends most of its life redoing work it has already done.
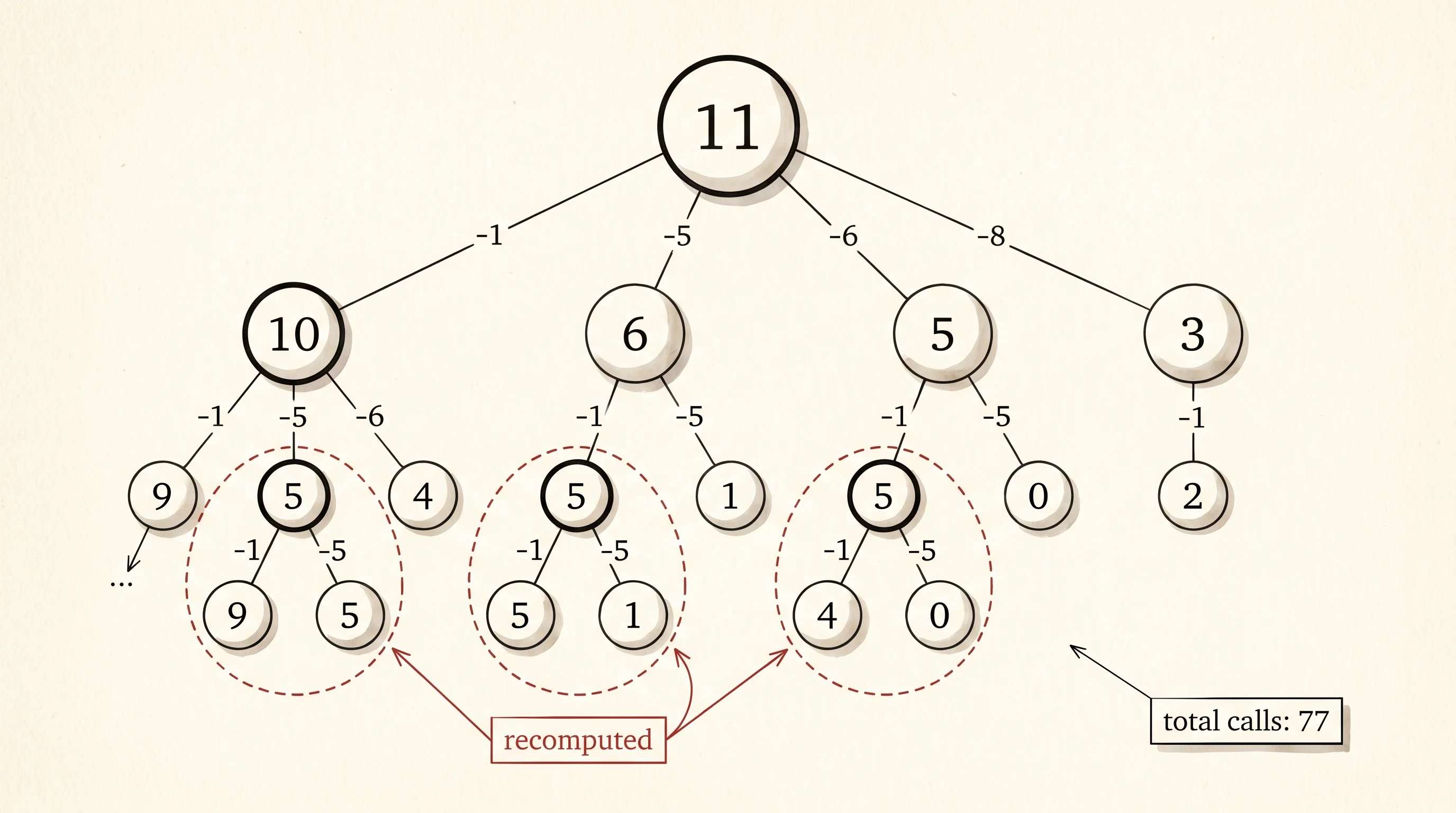
Look at the picture and count the duplicates. The subtree rooted at amount 5 appears in three different branches — once below the path through coin 1, once below coin 6, and once nested inside other branches. Each appearance restarts the whole subtree. With four coins, the call count grows as a four-way branching tree, and the tree gets exponentially taller as the target gets bigger. Bump the target from 11 to 30 and the call count goes from 77 to millions. That blow-up is what Bellman was staring at in 1953. His move was the move you would make at the kitchen table — write the answer down the first time, and on every visit after, read it off the paper instead of recomputing.
The Rust version of that paper is a Vec<Option<u32>>. One slot per checkpoint, each slot either None if you have not been there yet or Some(answer) if you have. The function checks the slot first. If it has an answer, return it. If not, do the work, write the answer into the slot, then return.
fn topdown(amount: u32, memo: &mut Vec<Option<u32>>) -> u32 {
if amount == 0 {
return 0;
}
if let Some(answer) = memo[amount as usize] {
return answer;
}
let mut best = u32::MAX;
for &coin in COINS.iter() {
if coin <= amount {
let sub = topdown(amount - coin, memo);
if sub != u32::MAX && sub + 1 < best {
best = sub + 1;
}
}
}
memo[amount as usize] = Some(best);
best
}The body of the function is nearly identical to the naive version. The only changes are the early lookup at the top and the assignment at the bottom. That is the whole top-down dynamic programming pattern. It is recursion with a notepad. The recursion still flows from the top of the problem down to the base case, but every answer gets memorized on the way back up. The second time the recursion asks about amount 5, the answer is sitting in the memo and the work is skipped. The technical word for the notepad is "memoization," from the Latin word for "to be remembered." Donald Michie at Edinburgh coined the term in 1968 in a paper about chess-playing programs that ran out of memory before they ran out of moves.
The other direction is to flip the recursion around and walk up from the base case instead of down from the target. That version is called bottom-up, or tabulation. Allocate the full table, fill in the base case at index 0, then fill index 1 by looking at the coins, then index 2 the same way, all the way up to the target. By the time you reach the last cell, every smaller cell already holds the right answer and nothing recurses at all. The whole loop is two nested fors — one over checkpoints, one over coins.
fn bottomup(amount: u32) -> Vec<u32> {
let n = amount as usize;
let mut table = vec![u32::MAX; n + 1];
table[0] = 0;
for spot in 1..=n {
for &coin in COINS.iter() {
let c = coin as usize;
if c <= spot && table[spot - c] != u32::MAX && table[spot - c] + 1 < table[spot] {
table[spot] = table[spot - c] + 1;
}
}
}
table
}The outer loop walks from spot = 1 to spot = amount. The inner loop tries each coin. If the coin fits and the leftover cell has an answer, the candidate is table[spot - c] + 1. Keep the smaller of the current best and the candidate. When the outer loop finishes, the whole table is full and table[amount] is the final answer. Print the table to see the shape.
fn print_table(table: &[u32]) {
print!(" amount: ");
for (i, _) in table.iter().enumerate() {
print!("{i:>3} ");
}
println!();
print!(" coins: ");
for &cell in table.iter() {
if cell == u32::MAX {
print!(" . ");
} else {
print!("{cell:>3} ");
}
}
println!();
}Run all three solvers in one program and read the output side by side.
-- naive recursion: count every call --
naive answer for 11: 2 coins
naive call count: 77
-- top-down memoized: same answer, far fewer calls --
top-down answer for 11: 2 coins
memo after run: [., 1, 2, 3, 4, 1, 1, 2, 1, 2, 2, 2]
-- bottom-up table: fill left to right --
amount: 0 1 2 3 4 5 6 7 8 9 10 11
coins: 0 1 2 3 4 1 1 2 1 2 2 2
bottom-up answer for 11: 2 coinsThe naive run answers 2 coins after 77 function calls — proof that the right answer is reachable but expensive. The top-down run answers 2 coins and dumps the memo. The first slot is a dot because amount 0 returns before the function ever writes to the memo. The rest of the slots are filled, and reading them left to right gives you the minimum coin count for every amount from 1 to 11. Slot 11 says 2, which matches. The bottom-up run prints the same answers in a clean table. Index 5 says 1 coin, because you can make 5 with a single 5-piece. Index 6 says 1, because the 6-piece exists. Index 11 says 2, because 11 = 5 + 6. Walk the table left to right and watch each cell get computed from cells to its left — that is the whole algorithm, visible as a row of numbers.
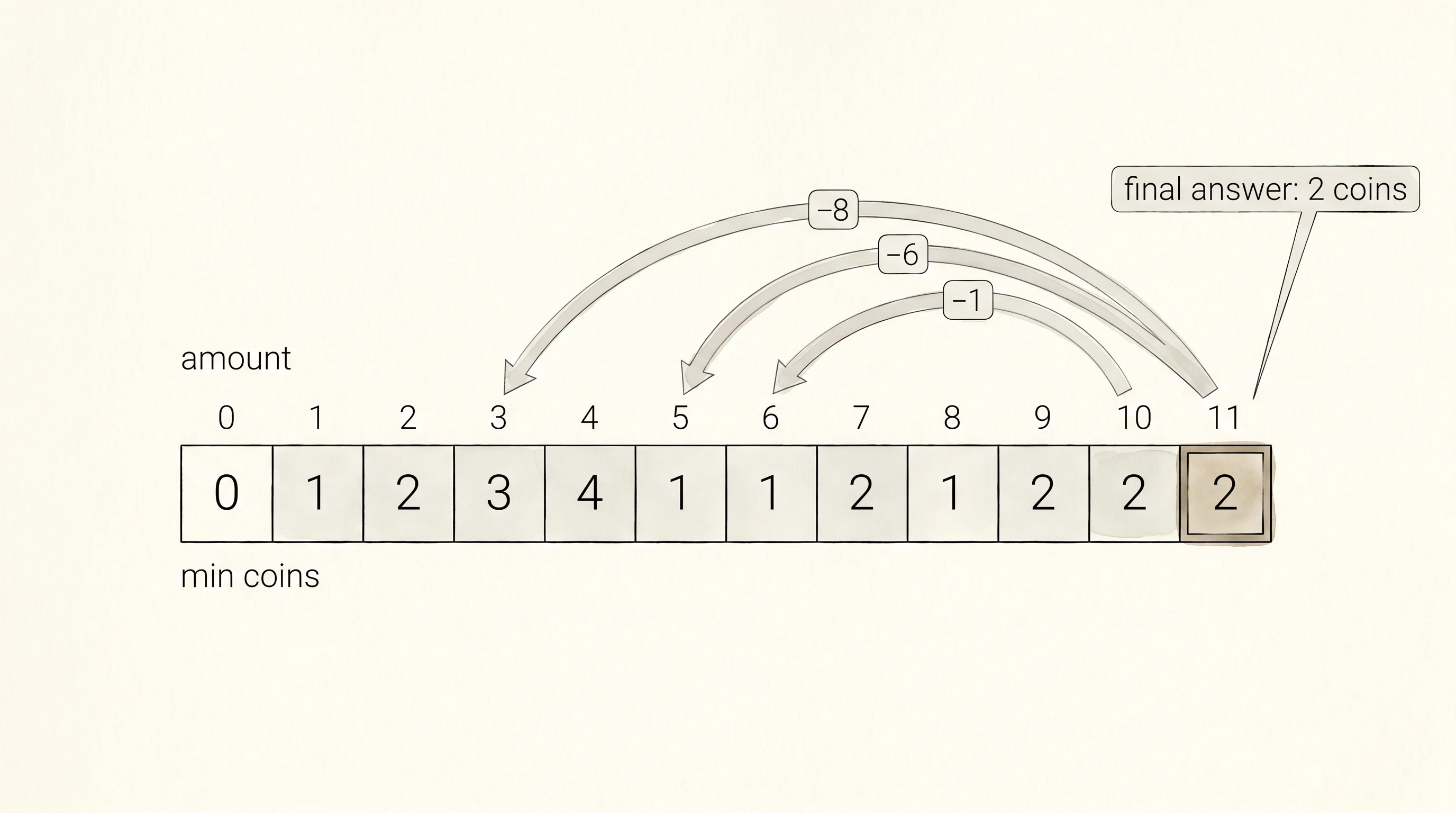
A question worth answering from the output. Why is slot 4 in the bottom-up table a 4, when the slots on either side of it are smaller? Because the only way to make 4 with coins from 8 is four 1-pieces. No bigger coin fits inside 4, so the algorithm cannot do better than 1+1+1+1. The neighboring slots — 3 and 5 — happen to have shortcuts. Slot 5 has the 5-piece. Slot 3 needs three 1-pieces, which is fewer than four. Dynamic programming does not invent denominations. It only finds the best path given the ones you handed it.
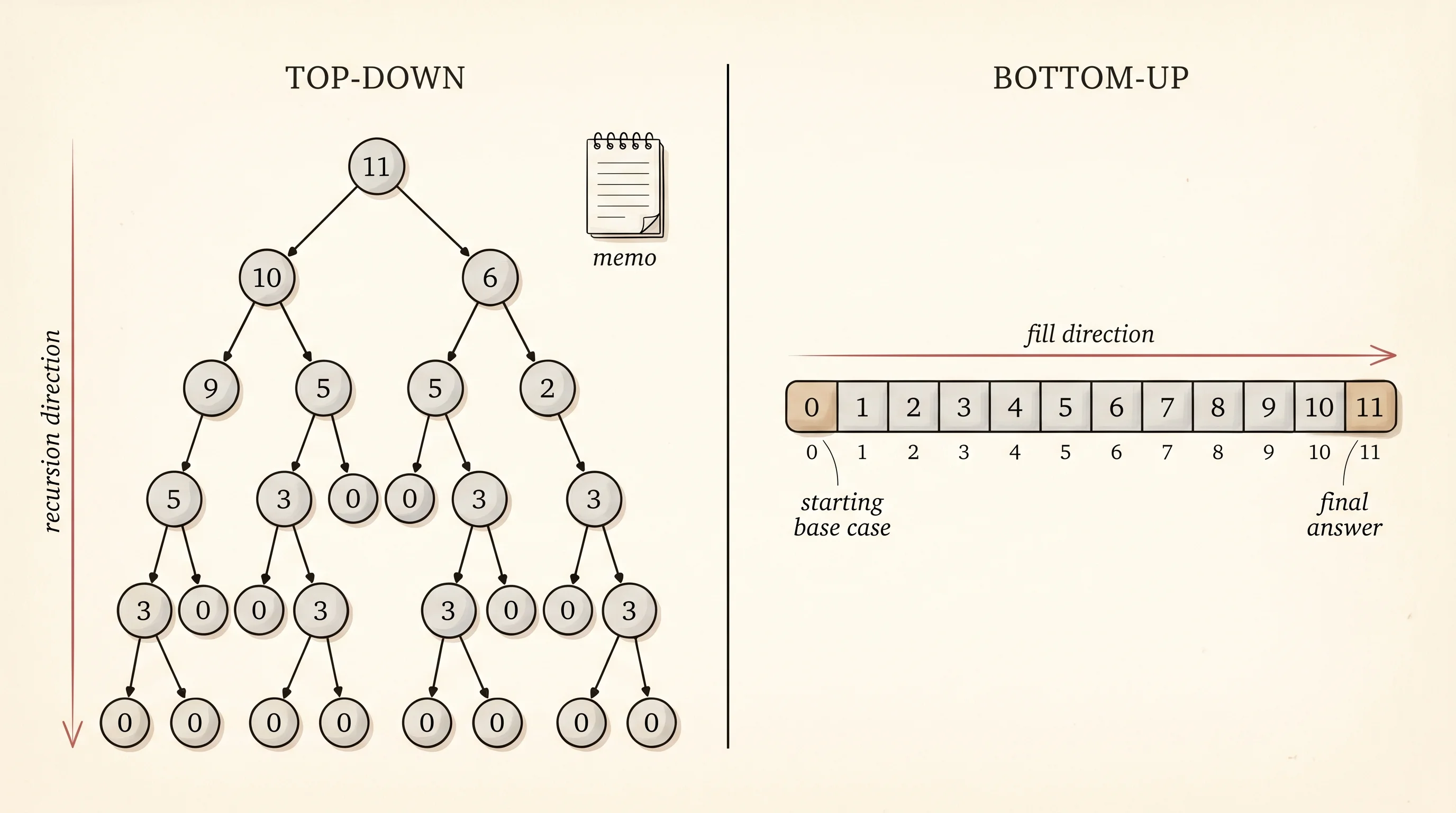
Top-down and bottom-up give the same answer and do the same total work. Which one you reach for depends on the shape of the problem. Top-down only computes the cells the target actually needs, so when most of the table is unreachable from the target, it wins. Bottom-up has no recursion stack and no function-call overhead, so when every cell will be visited anyway, it wins. Real code mostly uses the bottom-up version because it is one tight loop and the compiler turns it into very fast machine code. The top-down version is easier to write the first time you encounter a new problem, because you can describe the recurrence and let the memo handle the bookkeeping.
The trail version of dynamic programming has one weakness. The whole world has to fit in a table, and the table has to be small enough to hold in memory. A problem like shortest path on a graph with millions of nodes blows that assumption apart, because the connections between cells are not the simple "one step shorter" of a number line but a tangled web of who points to whom. The next lesson is the first one where the cells become real nodes and the recurrence becomes a search across edges instead of an index lookup.