Graph Algorithms
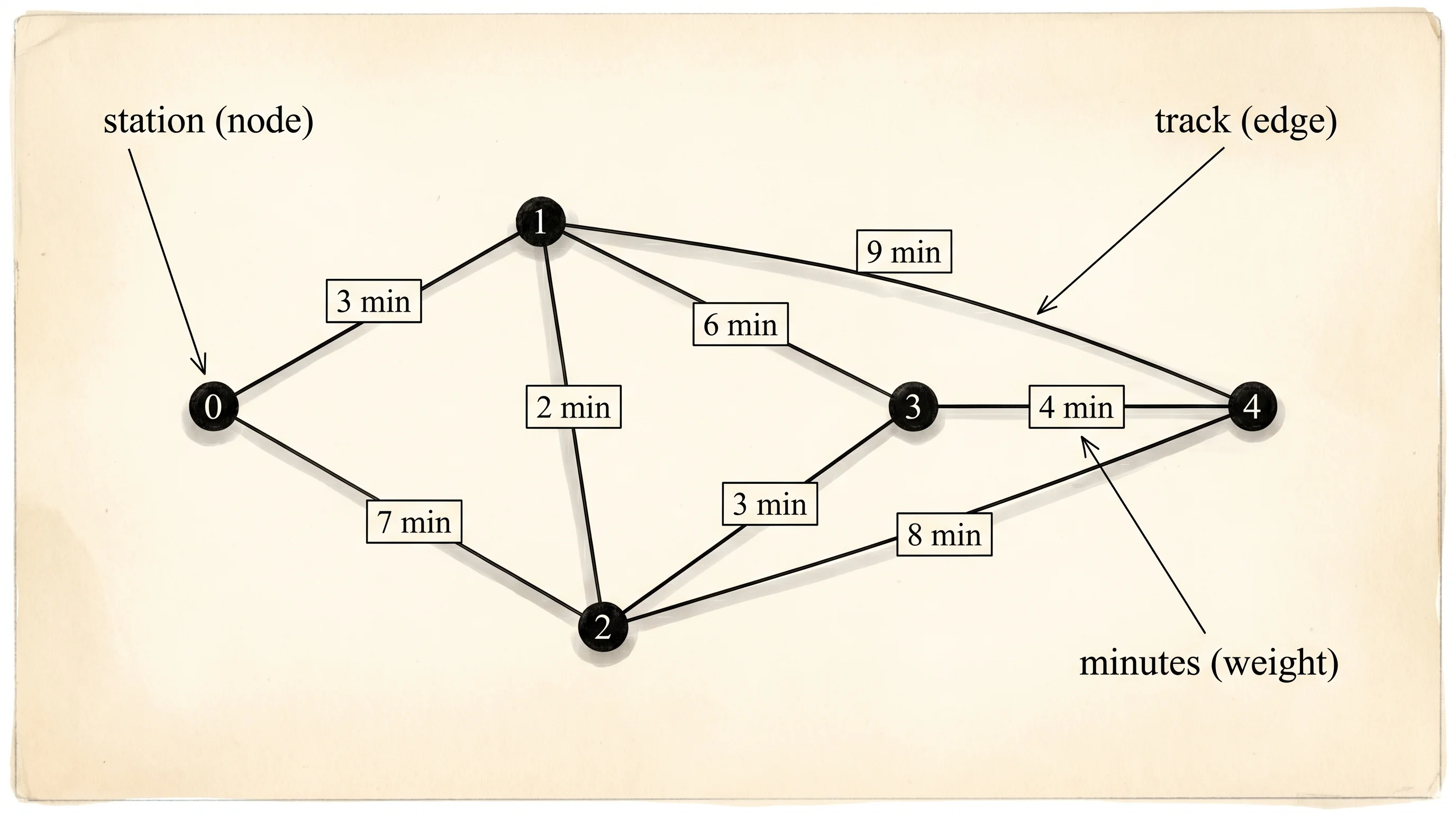
A subway map is a graph with prices on every line. Stations are dots, tracks are edges, and the number painted on each track is the minutes between the two stations. You stand on the platform at station 0 and want to know the fastest route to every other station on the system. Not the route with the fewest stops. The route that takes the least total time. The trick that every modern routing app uses to answer that question — Google Maps, the train screen at the airport, Uber's dispatcher — is one algorithm sketched out by a Dutch programmer in 1956.
Edsger Dijkstra was 26 and working at the Mathematisch Centrum in Amsterdam, helping demonstrate a room-sized computer called ARMAC to people who had never seen a computer. He needed a problem the audience could picture. He picked the shortest route between Rotterdam and Groningen on a map of the Dutch road network. He worked the algorithm out in his head over coffee one afternoon, without paper, while his fiancée shopped — 20 minutes of thinking. He did not publish it for 3 years, because he was sure it must already be known. When he finally wrote it up in 1959 it ran 2 and a half pages. The same 2 and a half pages are why your phone can plot a route through a city in 50 milliseconds.
The idea is simple enough to hold in one breath. Keep a notebook with one row per station and a current best time written next to each. The source station gets 0 minutes. Every other station starts at infinity, because you have not figured out how to get there yet. Then pick the station with the smallest current best time that you have not yet declared final. Walk every track leaving that station, and if going through this station gets you to a neighbor faster than the neighbor's current best time, update the neighbor. Declare this station final and never touch it again. Repeat until every station is final. The final number next to each station is the true shortest time from the source.
That description has a hidden cost. Every round, you have to find the smallest unsettled station. Scan the whole notebook and you pay for one scan per station — a quadratic cost on a big network. The fix is a min-heap. Keep a tiny stack-shaped data structure that always knows its smallest element. Push a station every time you find a cheaper route to it. Pop the smallest one when you need the next station to settle. Each push and pop costs about as much as walking a tree of log-n levels, which on a thousand-station map is about ten operations instead of a thousand.
// 5 stations. Each edge is (a, b, minutes) and goes both ways.
const EDGES: [(usize, usize, u32); 8] = [
(0, 1, 3),
(0, 2, 7),
(1, 2, 2),
(1, 3, 6),
(2, 3, 3),
(2, 4, 8),
(3, 4, 4),
(1, 4, 9),
];
const STATIONS: usize = 5;
fn build_lines() -> Vec<Vec<(usize, u32)>> {
let mut lines: Vec<Vec<(usize, u32)>> = vec![Vec::new(); STATIONS];
for (a, b, minutes) in EDGES {
lines[a].push((b, minutes));
lines[b].push((a, minutes));
}
// Sort each bucket so the trace prints the same on every machine.
for bucket in lines.iter_mut() {
bucket.sort();
}
lines
}
fn print_lines(lines: &[Vec<(usize, u32)>]) {
println!("-- station map (station -> [(neighbor, minutes)]) --");
for (station, bucket) in lines.iter().enumerate() {
println!(" station {station}: {bucket:?}");
}
}The graph itself is the boring part. Five stations, eight tracks, each track a triple of (a, b, minutes). The build_lines function walks the edges and pushes each track into both endpoints' buckets, because subway tracks run in both directions. Sorting each bucket at the end is not free, but it makes the trace deterministic — on a machine that hashed the edges in a different order, the trace would be shuffled and the snapshot would fail. Sort first, trace later.
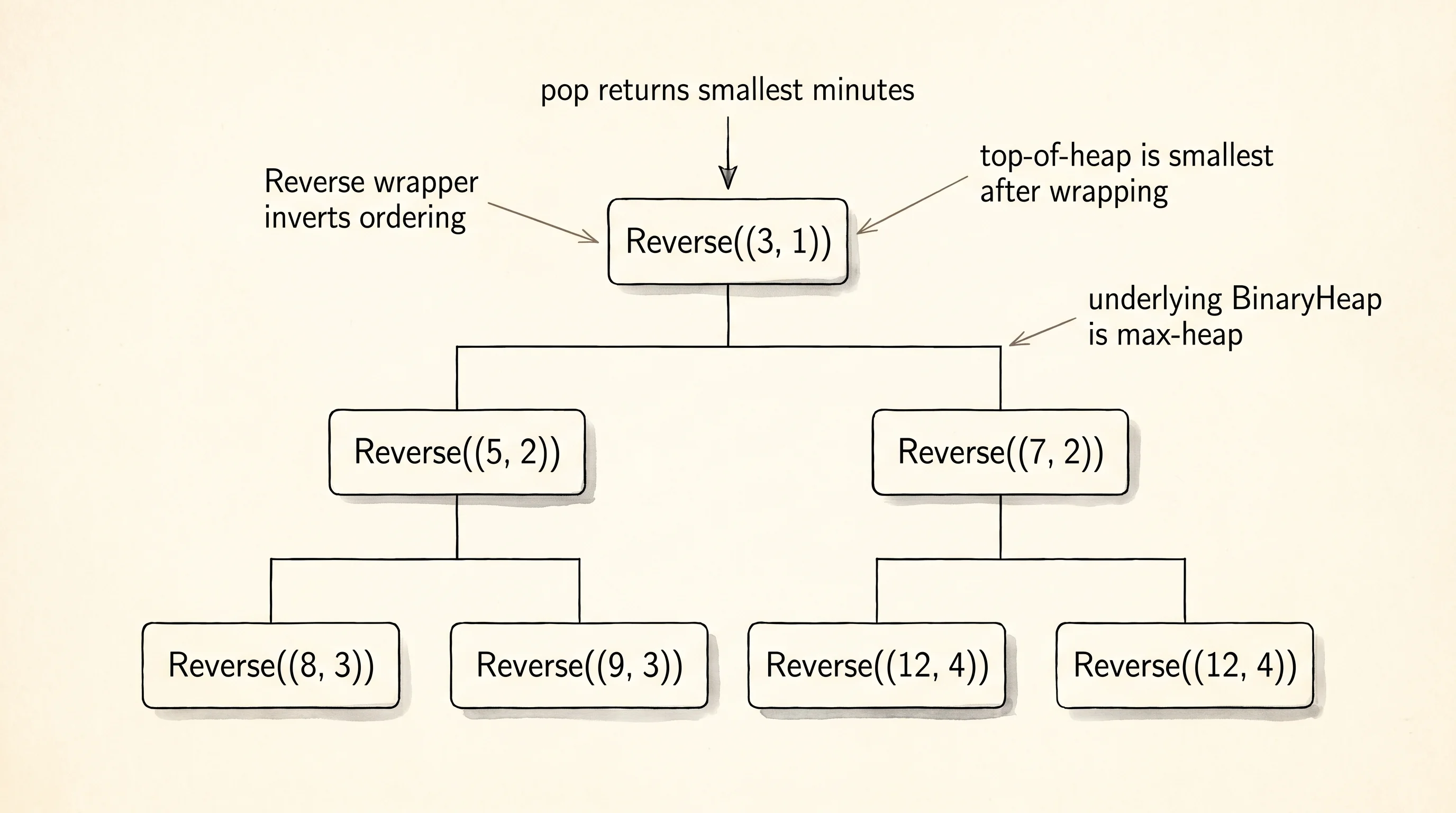
Now the algorithm itself. Rust has a min-heap in the standard library — sort of. BinaryHeap is what's there, and it is a max-heap. Pop gives you the biggest element, not the smallest. For Dijkstra that is exactly wrong. The fix is a one-line wrapper. std::cmp::Reverse is a tuple struct that inverts the ordering of whatever you put inside. Wrap a (minutes, station) pair in Reverse(...) and the heap will order it backward — smallest minutes on top. Pop returns the smallest. The wrapper costs nothing at runtime. The compiler inlines the inverted comparison and the assembly looks identical to a hand-written min-heap.
fn dijkstra(lines: &[Vec<(usize, u32)>], source: usize) -> (Vec<u32>, Vec<Option<usize>>) {
let n = lines.len();
let mut dist: Vec<u32> = vec![u32::MAX; n];
let mut prev: Vec<Option<usize>> = vec![None; n];
let mut heap: BinaryHeap<Reverse<(u32, usize)>> = BinaryHeap::new();
dist[source] = 0;
heap.push(Reverse((0, source)));
println!(" push station={source} minutes=0");
while let Some(Reverse((minutes, station))) = heap.pop() {
if minutes > dist[station] {
println!(" skip station={station} (stale entry {minutes} > {})", dist[station]);
continue;
}
println!(" settle station={station} minutes={minutes}");
for &(neighbor, hop) in &lines[station] {
let candidate = minutes + hop;
if candidate < dist[neighbor] {
dist[neighbor] = candidate;
prev[neighbor] = Some(station);
heap.push(Reverse((candidate, neighbor)));
println!(" relax {station}->{neighbor} new={candidate}");
}
}
}
(dist, prev)
}Read the loop body twice. pop hands you the cheapest unsettled entry. The first check — if minutes > dist[station] — is the lazy-deletion trick. When we relax an edge and find a cheaper route, we just push a new entry into the heap. We do not bother finding and deleting the old one, because heaps cannot delete-by-key cheaply. So the heap accumulates stale entries pointing at higher times than the current best. When one of those stale entries finally bubbles up, the check sees that the recorded distance is already smaller than what this entry promises, and we throw the entry away. That single line is what makes the algorithm work without a fancier heap.
The relax step is where the actual learning happens. For each neighbor, compute the time to reach it through the current station — that is minutes + hop. If that is less than the neighbor's recorded best, update the best, write down which station you came from in prev, and push a new entry into the heap. The prev array is how you reconstruct the path later. It is a parent pointer, one per station, that says "to reach me by the best route, come from this station."
fn walk_back(prev: &[Option<usize>], target: usize) -> Vec<usize> {
let mut steps: Vec<usize> = Vec::new();
let mut here = Some(target);
while let Some(station) = here {
steps.push(station);
here = prev[station];
}
steps.reverse();
steps
}walk_back is the path reconstruction. Start at the target, look up its predecessor, then that one's predecessor, all the way back to a station whose prev is None. That's the source. Push each station as you go, then reverse the list so it reads source-to-target instead of target-to-source.
fn main() {
let lines = build_lines();
print_lines(&lines);
println!();
let source: usize = 0;
println!("-- Dijkstra from station {source} --");
let (dist, prev) = dijkstra(&lines, source);
println!();
println!("dist[0..{}] = {:?}", dist.len(), dist);
println!("prev[0..{}] = {:?}", prev.len(), prev);
println!();
println!("-- shortest path from {source} to each station --");
for target in 0..dist.len() {
let path = walk_back(&prev, target);
println!(" to {target}: {dist} min, route {path:?}", dist = dist[target]);
}
}The main function builds the graph, runs Dijkstra from station 0, prints the final distance table, then walks back through prev to print the actual route from 0 to every station.
-- station map (station -> [(neighbor, minutes)]) --
station 0: [(1, 3), (2, 7)]
station 1: [(0, 3), (2, 2), (3, 6), (4, 9)]
station 2: [(0, 7), (1, 2), (3, 3), (4, 8)]
station 3: [(1, 6), (2, 3), (4, 4)]
station 4: [(1, 9), (2, 8), (3, 4)]
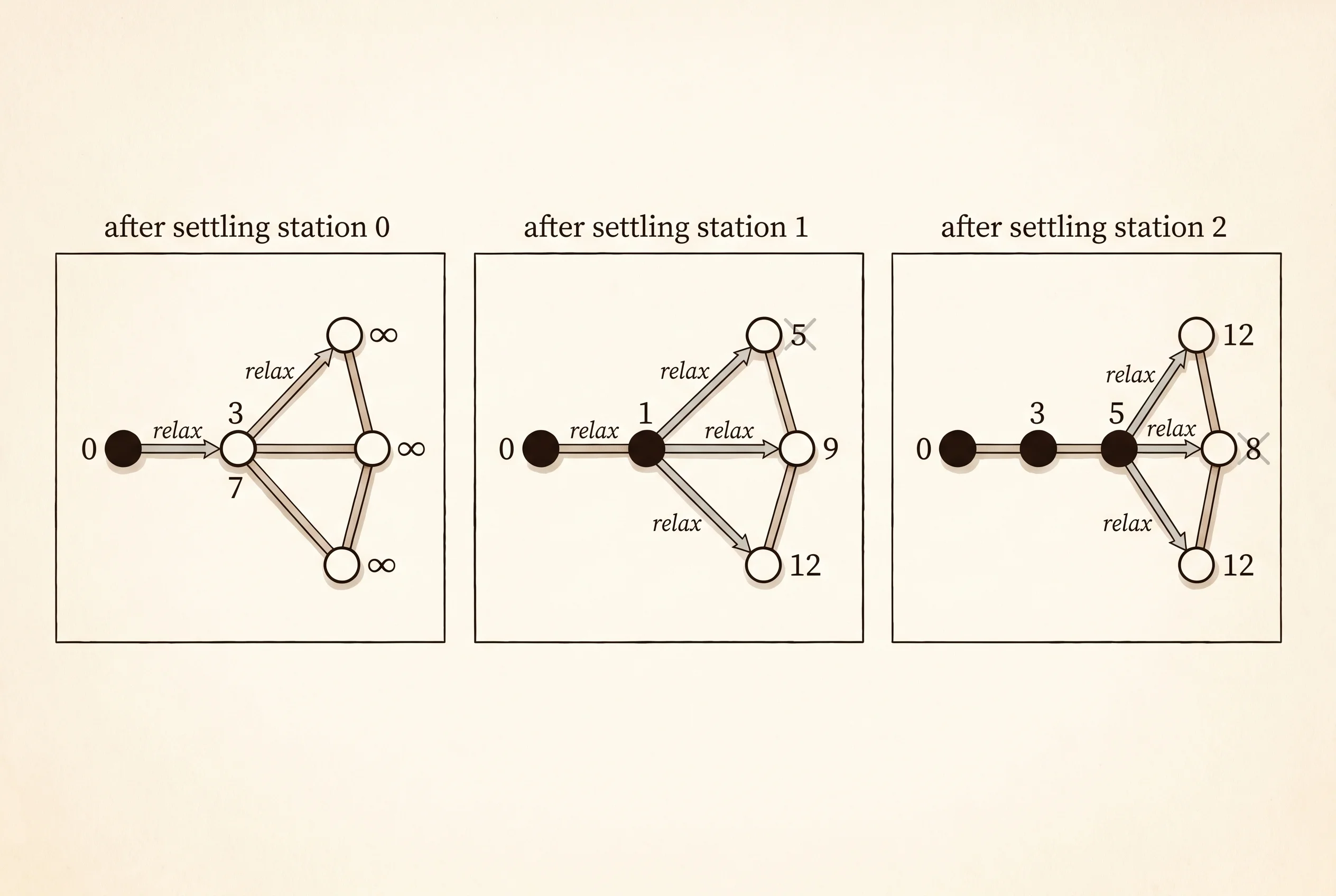
-- Dijkstra from station 0 --
push station=0 minutes=0
settle station=0 minutes=0
relax 0->1 new=3
relax 0->2 new=7
settle station=1 minutes=3
relax 1->2 new=5
relax 1->3 new=9
relax 1->4 new=12
settle station=2 minutes=5
relax 2->3 new=8
skip station=2 (stale entry 7 > 5)
settle station=3 minutes=8
skip station=3 (stale entry 9 > 8)
settle station=4 minutes=12
dist[0..5] = [0, 3, 5, 8, 12]
prev[0..5] = [None, Some(0), Some(1), Some(2), Some(1)]
-- shortest path from 0 to each station --
to 0: 0 min, route [0]
to 1: 3 min, route [0, 1]
to 2: 5 min, route [0, 1, 2]
to 3: 8 min, route [0, 1, 2, 3]
to 4: 12 min, route [0, 1, 4]The map block at the top is the graph. Each station's bucket shows its neighbors and the minutes to reach them. Station 0 has two tracks — to station 1 in 3 minutes and to station 2 in 7 minutes. Station 1 has four tracks because we built it as a hub.
The Dijkstra block is the trace, in order. The heap starts with just station 0 at 0 minutes. Pop it, settle it, look at its neighbors. Push 1 with cost 3, push 2 with cost 7. The heap now has two entries — (3, 1) and (7, 2). The next pop is (3, 1) because 3 is smaller. Settle station 1. Look at its neighbors. Neighbor 2 currently has dist 7. Going through station 1 costs 3+2 = 5, which beats 7, so relax — update dist[2] to 5 and push (5, 2) into the heap. The old (7, 2) is still in there; we just leave it. Push (9, 3) and (12, 4) from station 1's other tracks. Pop again — the smallest is (5, 2). Settle station 2, relax 2->3 from 9 down to 8. Now pop (7, 2) — the stale entry. The check sees that dist[2] is already 5, prints skip, and discards it. Pop (8, 3). Settle station 3. Its neighbor 4 has dist 12; going through 3 costs 8+4 = 12, which is not strictly less, so no relax. Pop (9, 3) — stale, skip. Pop (12, 4) — settle 4. Heap empty. Done.
The final distance table is [0, 3, 5, 8, 12]. Station 0 to station 4 takes 12 minutes. The route comes from walking prev backward: 4 came from 1, 1 came from 0. So the route is [0, 1, 4] — take the direct track from station 0 to 1 (3 minutes), then the long track from 1 to 4 (9 minutes), total 12. The other option through stations 0-1-2-3-4 is 3+2+3+4 = 12 — same total, but Dijkstra committed to the first route it found that was 12 and never looked back.
One question to sit with. Dijkstra refuses to work if a track has a negative weight. Why? Because the moment we settle a station and declare its distance final, we trust that no future discovery will make it cheaper. A negative-weight edge can break that promise by making it cheaper to reach a settled station through a longer detour. The fix is a different algorithm — Bellman-Ford — which is slower but tolerates negatives. The next bottleneck Dijkstra cannot solve is when the same overlapping problem appears in a thousand subgraphs and you want to memoize the answers — which is what dynamic programming is for.