Build an ETL Pipeline
A restaurant kitchen runs three stations in a line. Crates of vegetables and meat land at the back door. A prep cook trims, chops, and sorts. A plating station arranges the finished portions onto dishes that go out to the dining room. Nothing skips a station. Nothing goes from the back door straight to the plate. An ETL pipeline is the same idea applied to data — extract pulls the raw bytes from somewhere, transform cleans and reshapes them, load hands the finished rows to whatever wants to use them. The stations are short. The flow only goes forward. Each station hides the mess of the previous one from the next.

The name comes from the data warehouse work IBM and Teradata were doing in the late 1970s, when companies first started shipping nightly batches of transactions from operational databases into reporting systems. The early jobs were one giant SQL script that did everything at once, and they were impossible to debug because a bad row in the input would corrupt the report and nobody could tell at which step the corruption happened. Breaking the script into three named stages — extract, transform, load — meant that a failure at any station left the previous station's output sitting on disk where an engineer could read it and figure out what went wrong. The acronym ETL stuck. Forty years later the stations are the same. The crates are S3 buckets and the dining room is a Snowflake warehouse, but the kitchen layout has not changed.
The first station is extract. Its only job is to pull raw bytes from the source and hand back rows the next station can read.
// In production this string would be a file read, a HTTP body, or an S3
// object. The shape of the pipeline does not care where the bytes come from,
// so a hardcoded blob is enough to show the work.
const SOURCE: &str = "\
region,product,units,price
west,boots,4,89.50
east,boots,2,89.50
west,jacket,1,210.00
south,boots,7,82.00
east,jacket,3,205.00
west,scarf,9,18.00
south,jacket,2,199.00
east,scarf,12,17.50
south,scarf,5,18.00
west,boots,0,89.50
";
struct RawRow<'a> {
region: &'a str,
product: &'a str,
units: &'a str,
price: &'a str,
}
fn extract() -> Vec<RawRow<'static>> {
let mut rows: Vec<RawRow<'static>> = Vec::new();
let mut lines = SOURCE.lines();
let header = lines.next().expect("header line");
println!("extract: header = {header}");
for line in lines {
let parts: Vec<&str> = line.split(',').collect();
if parts.len() != 4 {
println!(" skip malformed line: {line}");
continue;
}
rows.push(RawRow {
region: parts[0],
product: parts[1],
units: parts[2],
price: parts[3],
});
}
println!("extract: pulled {} raw rows", rows.len());
println!();
rows
}The source string is hardcoded so the lesson stays deterministic, but the shape is what matters. In a real pipeline that &'static str is a file read, an HTTP body from an API, or an object pulled out of an S3 bucket. The extract function does not care. It splits the blob on newlines, peels off the header so the next line is a real record, and walks the rest one by one. A line with the wrong number of columns gets logged and skipped, because the alternative is a panic in the middle of the batch and a corrupted output file. The function returns a Vec<RawRow> where every field is still a &str — no parsing, no validation, no opinions about what the data means yet. That work belongs to the next station.
A RawRow borrows from the source string instead of owning copies, which is the cheapest possible representation. No allocations during extract. The whole batch of strings already lives in the binary as one chunk and the rows are just views into it.
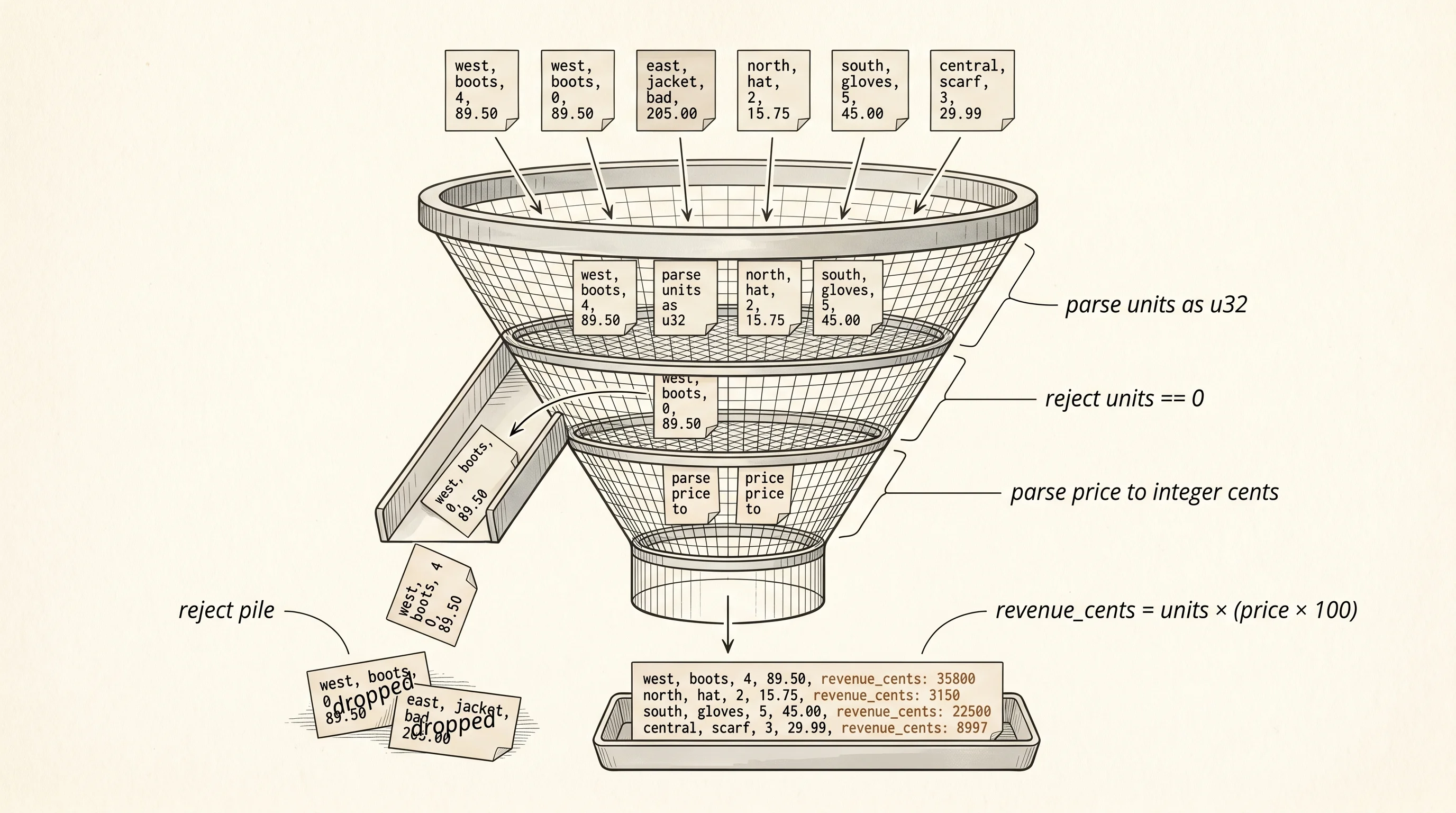
The second station is transform. Raw bytes arrive. Clean, typed, validated rows leave.
struct CleanRow {
region: String,
product: String,
units: u32,
price_cents: u32,
revenue_cents: u32,
}
fn transform(raw: Vec<RawRow<'_>>) -> Vec<CleanRow> {
let mut clean: Vec<CleanRow> = Vec::new();
println!("transform: cleaning {} raw rows", raw.len());
for row in raw {
let units: u32 = match row.units.parse() {
Ok(n) => n,
Err(_) => {
println!(" drop bad units {:?}", row.units);
continue;
}
};
if units == 0 {
println!(" drop zero-unit row ({}, {})", row.region, row.product);
continue;
}
let price_cents = match parse_dollars(row.price) {
Some(c) => c,
None => {
println!(" drop bad price {:?}", row.price);
continue;
}
};
clean.push(CleanRow {
region: row.region.to_string(),
product: row.product.to_string(),
units,
price_cents,
revenue_cents: units * price_cents,
});
}
println!("transform: kept {} clean rows", clean.len());
println!();
clean
}
fn parse_dollars(s: &str) -> Option<u32> {
let (dollars, cents) = s.split_once('.')?;
let d: u32 = dollars.parse().ok()?;
let c: u32 = cents.parse().ok()?;
if cents.len() != 2 {
return None;
}
Some(d * 100 + c)
}Transform is where the real work happens. units arrives as the string "4" and has to become the integer 4. price arrives as "89.50" and has to become an exact whole number of cents so the math never loses a penny to floating-point drift. A row with units set to "0" gets dropped — a zero-unit sale is data noise, not a real transaction, and the report would be misleading if it kept them. A row with garbage in any numeric field gets dropped too, with a log line that names what was wrong so an engineer reading the output can find the bad source row in the morning.
The CleanRow type carries owned String values for the region and product because the function is about to drop the borrow of SOURCE and the cleaned rows have to outlive the raw ones. It also carries a derived field — revenue_cents — that the load stage needs and that nobody else has computed yet. This is the rule of thumb for the transform layer. Anything the consumer is going to need that requires touching every row should be computed here, once, while every row is already in cache. Asking the load stage to compute revenue per row would mean walking the data twice for no reason.
parse_dollars is its own small function because the rule "two digits after the decimal point" is the kind of thing that hides bugs when it lives inline. Pulling it out makes the rule a single named place that the test suite can hammer if more shapes start arriving from upstream.
The third station is load. Clean rows in, persisted output out.
fn load(rows: &[CleanRow]) {
println!("load: final table");
println!(" region product units revenue");
println!(" ------ ------- ----- -------");
for r in rows {
println!(
" {:<6} {:<7} {:>5} {:>7}",
r.region,
r.product,
r.units,
fmt_cents(r.revenue_cents),
);
}
println!();
let mut totals: BTreeMap<String, u32> = BTreeMap::new();
for r in rows {
*totals.entry(r.region.clone()).or_insert(0) += r.revenue_cents;
}
println!("load: revenue by region");
for (region, cents) in &totals {
println!(" {:<6} {:>9}", region, fmt_cents(*cents));
}
let grand: u32 = totals.values().sum();
println!(" ------ ---------");
println!(" total {:>9}", fmt_cents(grand));
}
fn fmt_cents(c: u32) -> String {
format!("${}.{:02}", c / 100, c % 100)
}Load prints to the screen here, but in production it would be a sqlx insert into a Postgres table, a Parquet file written to disk, or a stream of rows pushed onto a Kafka topic. The shape of the function does not change. It takes a slice of CleanRow, walks it once to render the detail table, walks it a second time to fold the rows into a BTreeMap of revenue-by-region, and prints a grand total at the bottom. The BTreeMap is the right choice over HashMap because the output needs a stable, sorted region order — a report whose row order shuffles between runs is a report that breaks every dashboard built on top of it.
Run the binary and watch every station report what it did.
extract: header = region,product,units,price
extract: pulled 10 raw rows
transform: cleaning 10 raw rows
drop zero-unit row (west, boots)
transform: kept 9 clean rows
load: final table
region product units revenue
------ ------- ----- -------
west boots 4 $358.00
east boots 2 $179.00
west jacket 1 $210.00
south boots 7 $574.00
east jacket 3 $615.00
west scarf 9 $162.00
south jacket 2 $398.00
east scarf 12 $210.00
south scarf 5 $90.00
load: revenue by region
east $1004.00
south $1062.00
west $730.00
------ ---------
total $2796.00Read top to bottom. Extract pulls 10 raw rows out of the blob and announces the header it skipped. Transform reports how many raw rows it received, drops the one zero-unit row with a named reason, and announces how many cleaned rows it kept. Load prints the final 9-row table aligned in columns, then folds the table into per-region totals — east at $1004.00, south at $1062.00, west at $730.00 — and ends with the grand total of $2796.00. Three stations, three sections of output, each one a witness that the station ran and left clean work behind for the next.
One question the output answers — why did the row count drop from 10 to 9 instead of from 10 to 8? The blob has 10 data rows, the malformed-line check would drop any row with the wrong column count, and the unit-zero check drops the last row where west, boots, 0. None of the other rows have garbage units or garbage prices, so 10 minus 1 dropped row gives 9 clean rows. If a second row got dropped silently the report would still print and look right, but the totals would be wrong and nobody downstream would know. The log lines from inside transform are the only way to catch that class of bug, which is why the lesson prints them instead of swallowing them.
The thing this pipeline cannot do on its own is run continuously. The batch runs once, end to end, and exits. A real production pipeline has to handle new data showing up every minute, retries when the source is down, deduplication so the same row does not get loaded twice, and a way to resume from the middle when the box crashes — which is what scheduled workers and durable queues exist to solve.