APIs That Talk to Databases
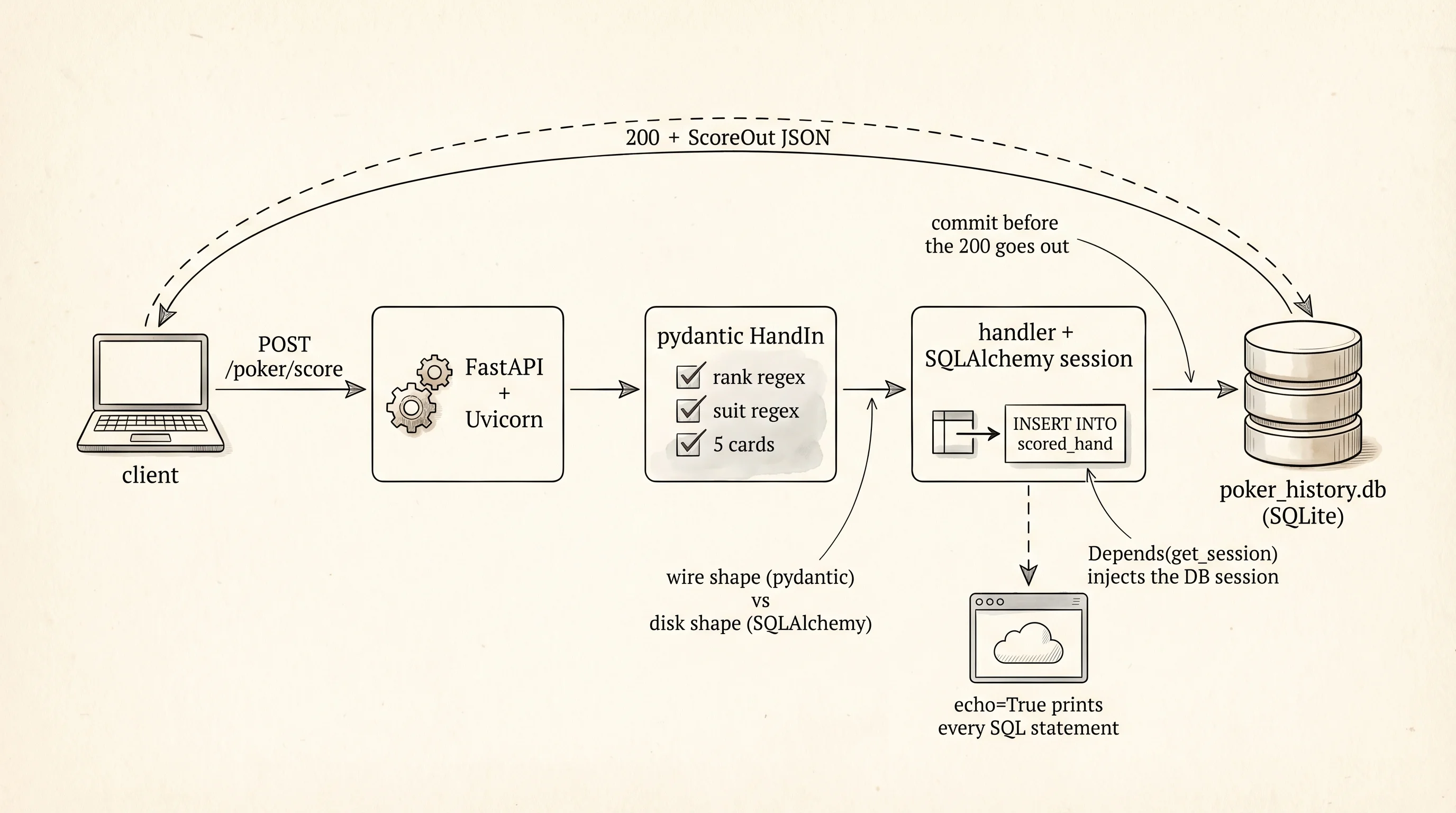
The pass-through window still sits between the kitchen and the dining room. What was missing on the apis-build-and-consume page was the pantry. The cook could score a hand you handed her on a ticket, but the minute the kitchen closed for the night every scored hand vanished. A real kitchen keeps a log: what came in, what went out, who ordered what. This lesson bolts a pantry onto the poker API. Every time a ticket comes through POST /poker/score, the cook writes a row to a pantry shelf in SQLite. A new endpoint GET /history reads those rows back so any caller can replay the night's service.
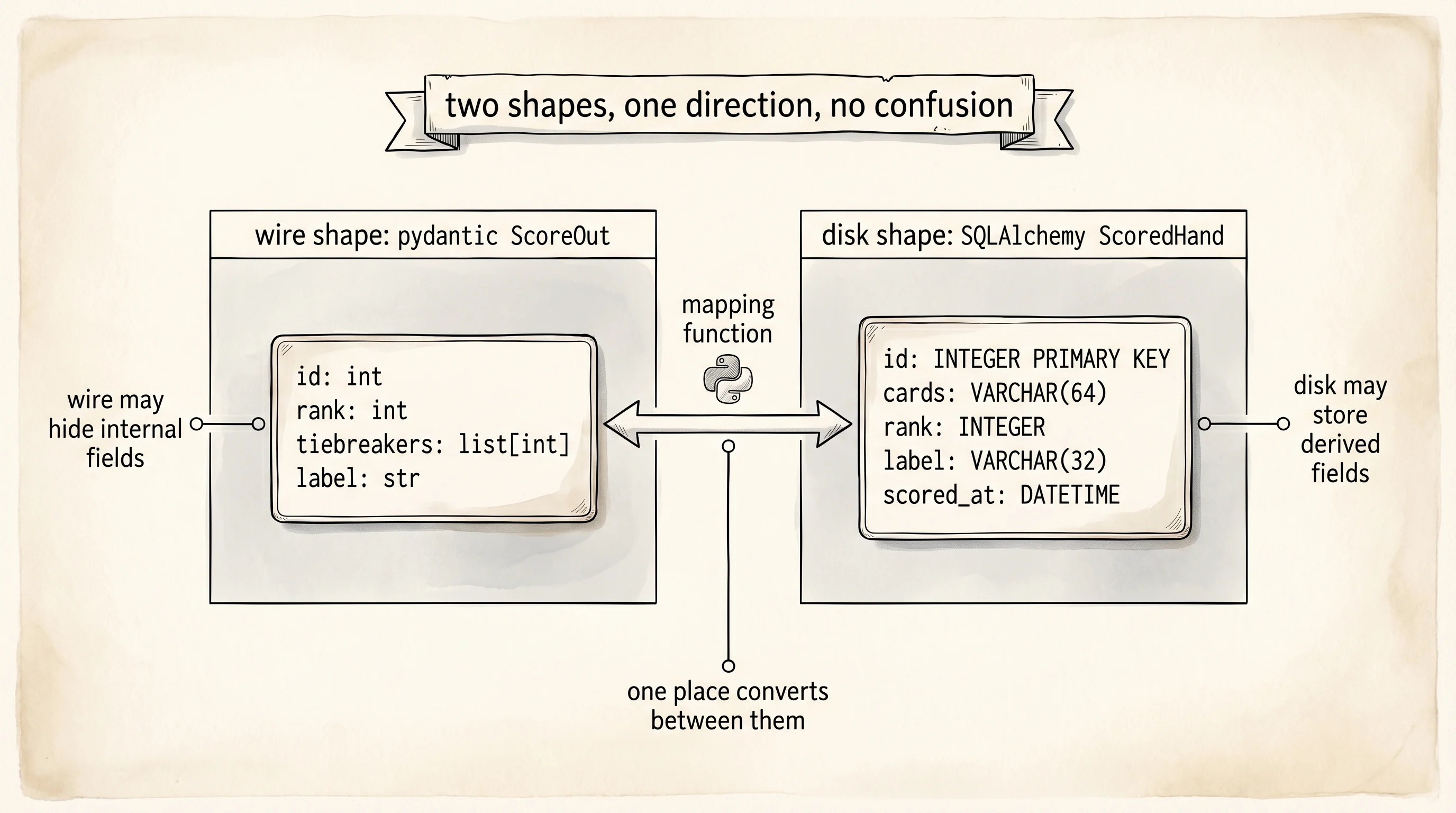
The modern backend shape came out of a decade of reshuffling. The LAMP stack — Linux, Apache, MySQL, PHP — ran most of the 2000s web. Ruby on Rails in 2004 made ActiveRecord the default ORM pattern: one class, both API shape and DB shape, everything in one place. That shortcut bit the industry every time a wire format had to drift from a storage format. In 2017 Samuel Colvin released pydantic, and by 2019 the Python community had settled on a split: pydantic classes describe the wire (what HTTP receives and returns), SQLAlchemy classes describe the disk (what the database holds), and a small mapping function moves data between them. Two shapes, one direction, no confusion about whose field it is when the API adds a field the database does not want.
Copy the poker-api folder from the earlier lesson or start fresh inside it. The venv should still have fastapi, uvicorn, httpx, and the poker package installed in editable mode. Add SQLAlchemy.
cd ~/learning-python/poker-api
source .venv/bin/activate
pip install "sqlalchemy>=2.0"cd $HOME\learning-python\poker-api
.venv\Scripts\Activate.ps1
pip install "sqlalchemy>=2.0"Pull the database layer into its own file db.py so it does not blur with the HTTP handlers.
from datetime import datetime
from sqlalchemy import create_engine, Integer, String, DateTime
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, sessionmaker
engine = create_engine("sqlite:///poker_history.db", echo=True)
SessionLocal = sessionmaker(engine, expire_on_commit=False)
class Base(DeclarativeBase):
pass
class ScoredHand(Base):
__tablename__ = "scored_hand"
id: Mapped[int] = mapped_column(primary_key=True)
cards: Mapped[str] = mapped_column(String(64))
rank: Mapped[int] = mapped_column(Integer)
label: Mapped[str] = mapped_column(String(32))
scored_at: Mapped[datetime] = mapped_column(DateTime, default=datetime.utcnow)
def init_db() -> None:
Base.metadata.create_all(engine)Three things to call out. echo=True keeps every SQL statement flowing to the terminal, same echo switch you met on the databases-sql page — the whole point of this lesson is seeing SQL fire on every HTTP call. cards is stored as a single string like "A♠,K♠,Q♠,J♠,10♠" because SQLite has no array column and this lesson is about the wiring, not about a perfectly normalized schema. scored_at fills in on insert using default=datetime.utcnow, which SQLAlchemy translates into the current timestamp on every save.
Replace main.py with the extended version. The POST /poker/score handler is the same scorer from apis-build-and-consume, now wrapped in a database write. The GET /history handler paginates backward through the stored hands.
from fastapi import FastAPI, HTTPException, Depends, Query as QueryParam
from pydantic import BaseModel, Field
from sqlalchemy import select, func
from sqlalchemy.orm import Session
from datetime import datetime
from poker.cards import Card
from poker.score import score_hand
from db import SessionLocal, ScoredHand, init_db
app = FastAPI(title="Poker Score API")
@app.on_event("startup")
def startup() -> None:
init_db()
def get_session() -> Session:
with SessionLocal() as session:
yield session
class CardIn(BaseModel):
rank: str = Field(pattern=r"^(2|3|4|5|6|7|8|9|10|J|Q|K|A)$")
suit: str = Field(pattern=r"^[shdc]$")
class HandIn(BaseModel):
cards: list[CardIn] = Field(min_length=5, max_length=5)
class ScoreOut(BaseModel):
id: int
rank: int
tiebreakers: list[int]
label: str
class HistoryItem(BaseModel):
id: int
cards: str
rank: int
label: str
scored_at: datetime
class HistoryPage(BaseModel):
total: int
limit: int
offset: int
items: list[HistoryItem]
RANK_LABELS = {
1: "high card", 2: "one pair", 3: "two pair", 4: "three of a kind",
5: "straight", 6: "flush", 7: "full house", 8: "four of a kind",
9: "straight flush", 10: "royal flush",
}
@app.post("/poker/score", response_model=ScoreOut)
def score(hand: HandIn, session: Session = Depends(get_session)) -> ScoreOut:
cards = [Card(rank=c.rank, suit=c.suit) for c in hand.cards]
if len({(c.rank, c.suit) for c in cards}) != 5:
raise HTTPException(status_code=400, detail="duplicate cards in hand")
result = score_hand(cards)
row = ScoredHand(
cards=",".join(repr(c) for c in cards),
rank=result[0],
label=RANK_LABELS[result[0]],
)
session.add(row)
session.commit()
session.refresh(row)
return ScoreOut(
id=row.id,
rank=result[0],
tiebreakers=list(result[1:]),
label=RANK_LABELS[result[0]],
)
@app.get("/history", response_model=HistoryPage)
def history(
limit: int = QueryParam(default=10, ge=1, le=100),
offset: int = QueryParam(default=0, ge=0),
session: Session = Depends(get_session),
) -> HistoryPage:
total = session.scalar(select(func.count()).select_from(ScoredHand)) or 0
rows = session.scalars(
select(ScoredHand).order_by(ScoredHand.id.desc()).limit(limit).offset(offset)
).all()
return HistoryPage(
total=total,
limit=limit,
offset=offset,
items=[
HistoryItem(
id=row.id, cards=row.cards, rank=row.rank,
label=row.label, scored_at=row.scored_at,
)
for row in rows
],
)Notice the Depends(get_session) on both handlers. FastAPI calls get_session() once per request, yields a Session into the handler, and closes the session when the request returns. That pattern is called dependency injection — the handler does not know how the session got there, only that it has one while it runs. If this project ever swaps SQLite for Postgres you change one line in db.py and no handler has to move.
Run the server.
uvicorn main:app --reload --host 127.0.0.1 --port 8000uvicorn main:app --reload --host 127.0.0.1 --port 8000The startup path fires init_db() once. SQLAlchemy echoes the table-creation SQL so you see the schema being built.
CREATE TABLE scored_hand (
id INTEGER NOT NULL,
cards VARCHAR(64) NOT NULL,
rank INTEGER NOT NULL,
label VARCHAR(32) NOT NULL,
scored_at DATETIME NOT NULL,
PRIMARY KEY (id)
)Leave the server running. Open a second terminal in the same folder with the venv active. Write drive.py to fire 3 scoring calls and then page through the history.
import httpx
hands = [
[("A", "s"), ("K", "s"), ("Q", "s"), ("J", "s"), ("10", "s")],
[("K", "s"), ("K", "d"), ("7", "h"), ("7", "s"), ("J", "h")],
[("A", "d"), ("A", "c"), ("K", "d"), ("J", "h"), ("9", "d")],
]
with httpx.Client(base_url="http://127.0.0.1:8000") as client:
for cards in hands:
payload = {"cards": [{"rank": r, "suit": s} for r, s in cards]}
response = client.post("/poker/score", json=payload)
print("POST ->", response.status_code, response.json())
response = client.get("/history", params={"limit": 2, "offset": 0})
print("GET /history?limit=2&offset=0 ->", response.status_code)
for item in response.json()["items"]:
print(" ", item["id"], item["label"], item["cards"])
response = client.get("/history", params={"limit": 2, "offset": 2})
print("GET /history?limit=2&offset=2 ->", response.status_code)
for item in response.json()["items"]:
print(" ", item["id"], item["label"], item["cards"])Run python drive.py in the second terminal. On the server terminal the echoed SQL fires for every call: an INSERT per score, a COUNT plus SELECT per history page.
INSERT INTO scored_hand (cards, rank, label, scored_at) VALUES (?, ?, ?, ?)
COMMIT
INSERT INTO scored_hand (cards, rank, label, scored_at) VALUES (?, ?, ?, ?)
COMMIT
INSERT INTO scored_hand (cards, rank, label, scored_at) VALUES (?, ?, ?, ?)
COMMIT
SELECT count(*) AS count_1 FROM scored_hand
SELECT scored_hand.id, scored_hand.cards, scored_hand.rank, scored_hand.label, scored_hand.scored_at
FROM scored_hand ORDER BY scored_hand.id DESC
LIMIT ? OFFSET ?Back in the driver terminal.
POST -> 200 {'id': 1, 'rank': 10, 'tiebreakers': [], 'label': 'royal flush'}
POST -> 200 {'id': 2, 'rank': 3, 'tiebreakers': [13, 13, 7, 7, 11], 'label': 'two pair'}
POST -> 200 {'id': 3, 'rank': 2, 'tiebreakers': [14, 14, 13, 11, 9], 'label': 'one pair'}
GET /history?limit=2&offset=0 -> 200
3 one pair Ad,Ac,Kd,Jh,9d
2 two pair Ks,Kd,7h,7s,Jh
GET /history?limit=2&offset=2 -> 200
1 royal flush As,Ks,Qs,Js,10sPagination works. The first page returns the 2 most recent hands, the second page returns the oldest 1. The order by id desc and limit/offset combo is the canonical pattern for paginated history feeds across every backend on earth. The total field in the response tells the caller how many pages exist without fetching them all. On a bigger production system you would replace offset pagination with cursor pagination (where id < last_seen_id) because offset gets expensive at page 50,000 — but for a personal project, offset is fine.
A question worth answering from the output: what is in the file poker_history.db on disk right now? Open a new terminal and drop into SQLite directly to confirm the pantry is real.
sqlite3 poker_history.db "SELECT id, rank, label, cards FROM scored_hand;"sqlite3 poker_history.db "SELECT id, rank, label, cards FROM scored_hand;"1|10|royal flush|As,Ks,Qs,Js,10s
2|3|two pair|Ks,Kd,7h,7s,Jh
3|2|one pair|Ad,Ac,Kd,Jh,9dEvery hand your kitchen served tonight is on the pantry shelf. Stop the server, restart it, call GET /history again — the rows come back. Durability from the ACID contract is the whole point of the pantry. The server can crash, the laptop can reboot, and the history survives because SQLite flushed each commit to disk before the response went out.
Your stack runs on your laptop. Your laptop turns off at night. The next section opens the cloud, where the server is someone else's laptop that never turns off.