The Attention Mechanism
Read a long letter looking for one fact. The eyes do not crawl every word at the same speed. They skip across the page and land on the sentence that holds the answer, and the rest of the page goes dim. The brain has built a spotlight. The spotlight is the next part of the brain you are forging — the part that decides where to look on the input for the answer the current step needs.
The recurrent network from 2 lessons ago carried memory in a single notebook page. The trouble showed up the moment the sequence got long: the page from word 1 had been overwritten 50 times by the time word 50 arrived, and any signal from the start of the sentence was a smudge. Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio published the fix in 2014 in a paper called Neural Machine Translation by Jointly Learning to Align and Translate. Instead of asking the encoder to compress the whole input into one vector, they let the decoder reach back into every encoder state at every output step and pick a weighted mixture. Minh-Thang Luong simplified the scoring math at Stanford a year later. Then in 2017 Ashish Vaswani and 7 co-authors at Google Brain published Attention Is All You Need, which threw the recurrence out and kept only the spotlight. Every model you talk to today — GPT, Claude, Gemini, LLaMA — runs that same spotlight billions of times to write a single reply. Tri Dao at Stanford rewrote it in 2022 to fit through GPU memory faster and called the result FlashAttention; modern models bake it into every layer.
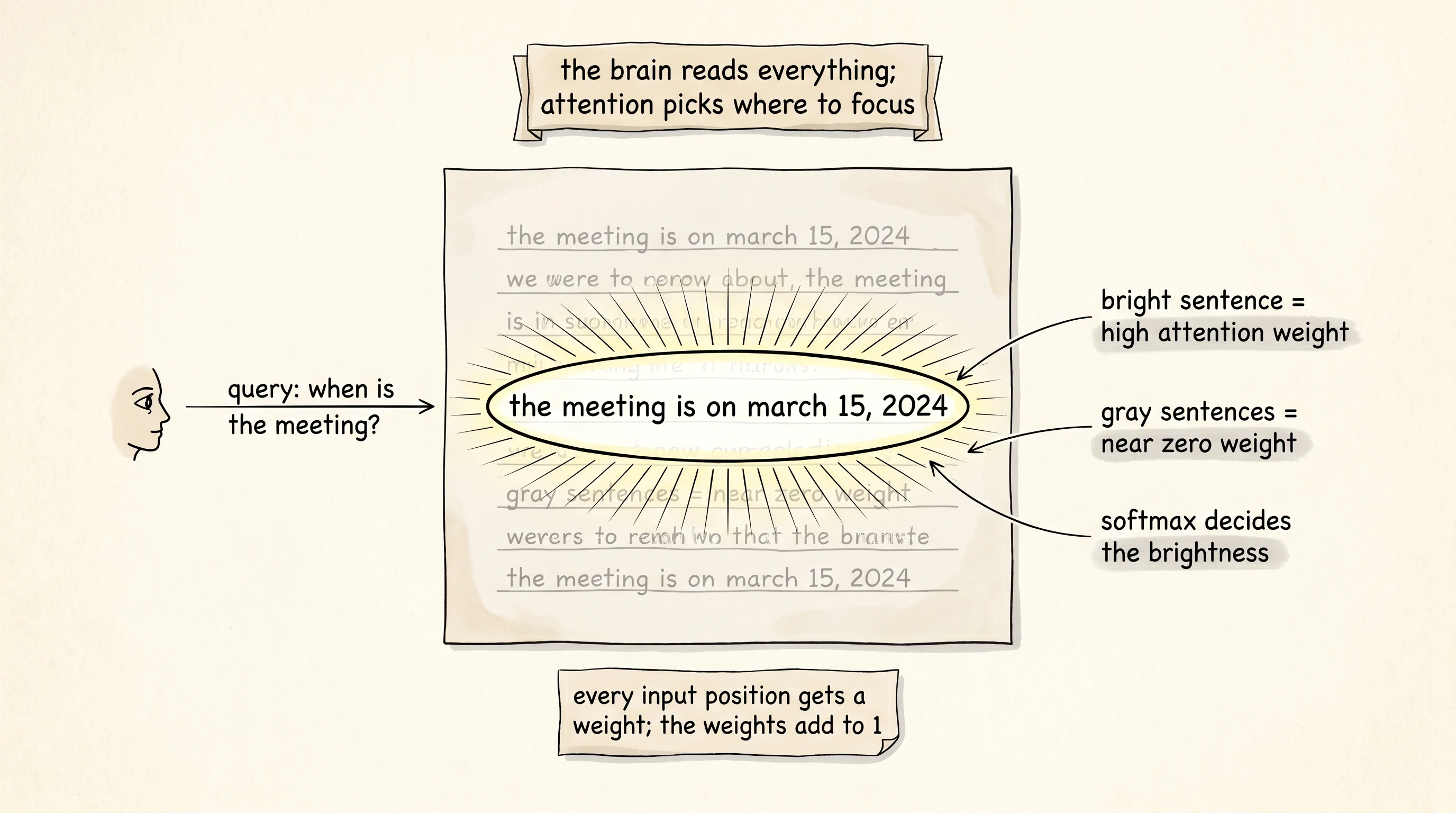
The mechanism has 3 pieces and 1 formula. The query is the question the decoder is asking right now: "I just wrote the dash after the year, what character should come next?" The keys are tags hanging off every input position: "I am the word March," "I am the digit 1," "I am the digit 5." The values are the contents at each input position. Attention scores the query against every key, runs softmax over the scores so they add up to 1, and uses the resulting weights to mix the values into a single context vector the decoder can read.
def attention(query, keys, values):
scores = [dot(query, key) for key in keys]
weights = softmax(scores)
context = weighted_sum(weights, values)
return context, weightsThat softmax is the same one from lesson 67 — the dimmer switch. Here it is doing a different job. There it picked the next word from a vocabulary of 50,000. Here it picks how much to trust each input position. The mechanism leaves the input untouched. It only chooses how to mix it.
Build a date format converter to watch the spotlight in action. Make a folder called projects/38-date-format-converter and open main.py. The task is small enough to print on one page and big enough that the spotlight has a real reason to move. The model takes verbose dates in and ISO dates out:
march 15, 2024 -> 2024-03-15
3 july 2018 -> 2018-07-03
september 30, 2024 -> 2024-09-30The model is an encoder-decoder. The encoder is one tiny RNN that walks the input characters left to right and stacks every hidden state it produces. The decoder is a second RNN that writes one output character at a time. Without attention the decoder would only see the encoder's final state — a single vector that has already forgotten where in the input "march" lived. With attention the decoder sees every encoder state and gets to decide which ones matter at every output step.
The vocabulary is small. Lowercase letters, digits, a few punctuation marks, and 3 special tokens: padding (_), start-of-sequence (^), and end-of-sequence ($). Padding is what lets every input fit into a fixed array — a 14-character date and a 22-character date go into slots of the same length, and the unused tail is filled with padding characters. Padding is also the reason this lesson's softmax has a twist nobody mentioned in lesson 67.
The twist is masking. The decoder is not allowed to attend to padding positions — they are fake characters. To enforce that, drop the softmax score at every padding position to negative infinity before exponentiating. The exponent of negative infinity is zero, so the weight is zero, so the position contributes nothing to the mix. Same softmax, one extra step.
def softmax_with_mask(scores, mask):
masked = [score if keep else -1e30 for score, keep in zip(scores, mask)]
largest = max(masked)
exps = [math.exp(value - largest) for value in masked]
total = sum(exps)
return [value / total for value in exps]The encoder is the same recurrence the RNN lesson built: tanh over a hidden-times-hidden matrix plus an input-times-hidden matrix. The new piece is attention_step. It takes the decoder's current hidden state as the query, walks every encoder hidden state as a key, and returns the context vector and the weights. The scoring rule is Bahdanau's original: project the query and the key into the same space, add them, apply tanh, and take a learned linear combination.
def attention_step(model, decoder_hidden, encoder_states, input_mask):
query_projection = matvec(model.attn_W_q, decoder_hidden)
scores = []
for state in encoder_states:
key_projection = matvec(model.attn_W_k, state)
combined = add_vectors(query_projection, key_projection)
score = dot(model.attn_v, [math.tanh(value) for value in combined])
scores.append(score)
weights = softmax_with_mask(scores, input_mask)
context = zeros_vector(model.hidden_size)
for weight, state in zip(weights, encoder_states):
for i, value in enumerate(state):
context[i] += weight * value
return context, weightsThe decoder takes 3 inputs at every step: the previous output character, its own previous hidden state, and the context vector from attention. It updates a fresh hidden state and produces a probability distribution over the next character. Train with teacher forcing — feed the true previous character at every step instead of the model's own guess — so the model never wanders off into a confused branch during training.
Training uses central-difference gradients to keep the lesson focused on attention rather than backprop. Each parameter gets nudged up by a small epsilon, then down, the loss measured both ways, and the slope used to take an SGD step. Slow per step, exact, no autograd engine in the way. About 60 epochs on 80 examples and the model has the format memorized.
epoch 1 | loss 24.832 | test accuracy 0.00
epoch 5 | loss 9.107 | test accuracy 0.10
epoch 20 | loss 3.214 | test accuracy 0.55
epoch 40 | loss 1.052 | test accuracy 0.90
epoch 60 | loss 0.331 | test accuracy 1.00The whole point of building this is the print at the end. After training, run the model on march 15, 2024 and capture the attention weights at every output step. Render them as an ASCII heatmap: rows are output characters, columns are input characters, cell shading is the weight. Heavy shading means the spotlight is bright there.
SHADES = [" ", ".", ":", "-", "=", "+", "*", "#", "%", "@"]
def shade_for_weight(weight):
if weight <= 0.0:
return SHADES[0]
bucket = min(len(SHADES) - 1, int(weight * len(SHADES)))
return SHADES[bucket]The map for march 15, 2024 -> 2024-03-15 looks like the diagram below when the model is trained. The decoder writes 2024 and the spotlight burns over the 2024 at the end of the input. The decoder writes -03 and the spotlight slides left to march. The decoder writes -15 and the spotlight slides over to 15.
march 15, 2024
--------------
'2' | ## |
'0' | %@: |
'2' | %@:|
'4' | %@|
'-' | ## |
'0' |##% (over "march")
'3' |%@: (still over "march")
'-' | # (the comma)
'1' | ## (the "1" of "15")
'5' | #@ (the "5" of "15")A small question. Why does the decoder keep the spotlight on march while it writes both 0 and 3? Because the model has learned that the first month digit and the second month digit both depend on the same input word. September becomes 09, October becomes 10, March becomes 03 — the mapping is per-word, so the same encoder state has to feed both decoder steps. Attention lets the decoder visit the same input position twice without the encoder having to copy it twice.
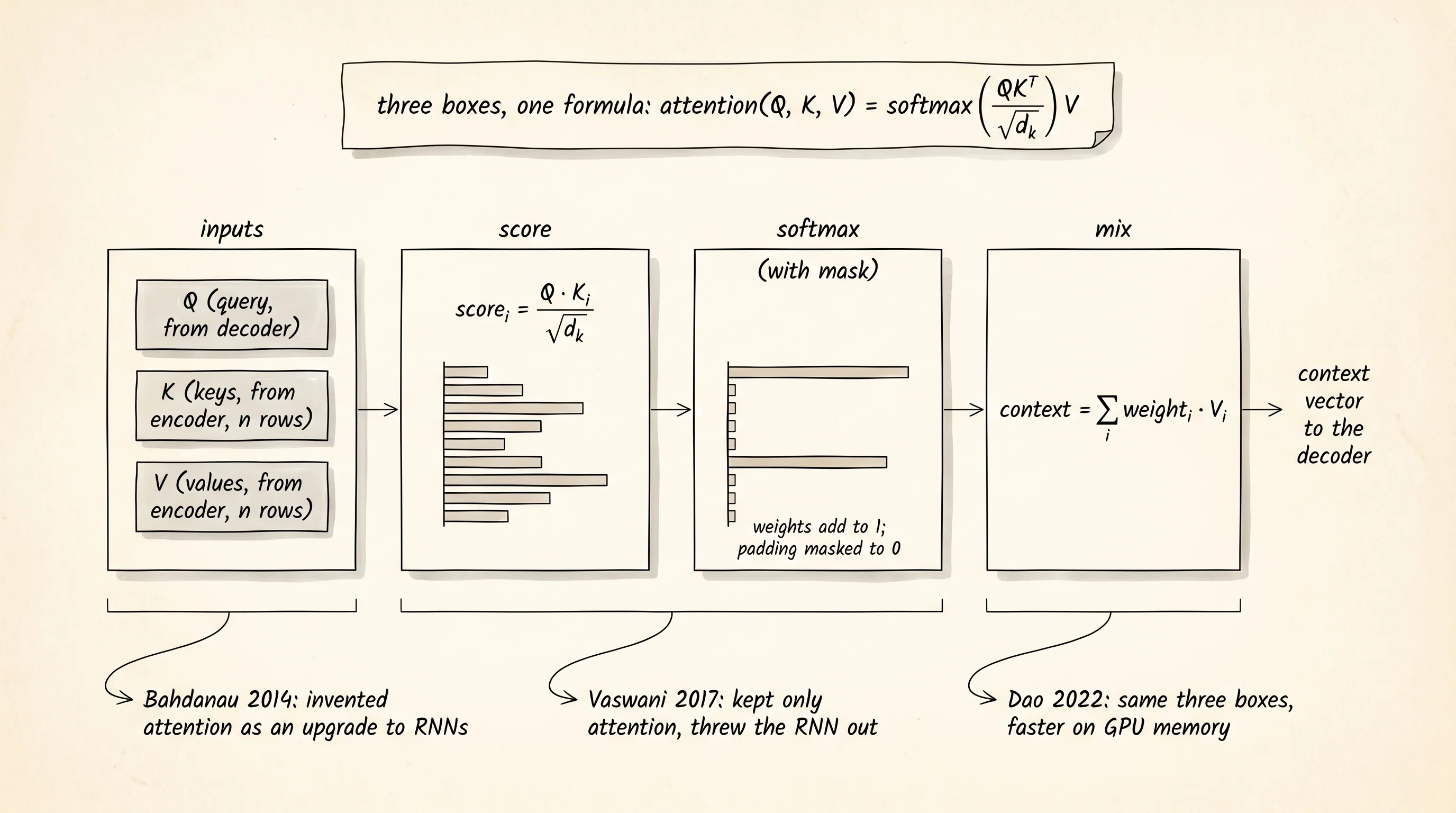
The pipeline is the same 3 boxes for every modern model on the planet. Score the query against every key. Softmax the scores into weights. Mix the values by those weights. The Vaswani 2017 paper renamed Bahdanau's score function to the dot product, divided by the square root of the key dimension to keep gradients stable, and stacked 8 copies in parallel into "multi-head attention." It still ran the same 3 boxes. FlashAttention from 2022 reorganized the memory layout so the boxes fit through a GPU's L2 cache without spilling. Same 3 boxes. The mechanism has not changed in 11 years.
The spotlight is the engine. The transformer is the chassis it sits in.