Byte Pair Encoding
A court stenographer in 1900 had to keep up with two lawyers shouting over each other and a judge banging a gavel. Writing the word "the" out in longhand 4000 times a day was suicide. The trick stenographers learned was a private alphabet: the most common words got their own short squiggle, the medium-rare words got a 2-stroke shorthand, and a word the stenographer had never heard before still worked because she could fall back to spelling it letter by letter. The brain you are about to write is that stenographer. It looks at a pile of text, finds the pieces it sees most often, and gives them their own symbols, while still keeping the raw letters around for words it has never met.
The first person to do this on a computer was Philip Gage in 1994. Gage was working on data compression and noticed that real files have a small set of very common byte pairs and a long tail of rare ones. He published a 2-page article in C Users Journal titled "A New Algorithm for Data Compression" that described the byte pair encoding loop: count every adjacent pair of bytes, replace the most common pair with a new byte that did not appear in the file, repeat. The idea sat unused outside of compression for 20 years. In 2016 a team at Edinburgh — Rico Sennrich, Barry Haddow, and Alexandra Birch — were trying to translate German into English with a neural network. German loves long compound words. The network kept seeing words it had never trained on (Donaudampfschifffahrtsgesellschaft) and breaking. They reached back into the compression literature, pulled out Gage's BPE, and applied it to text instead of bytes. Suddenly the network could handle any German word by splitting it into subword pieces it had seen. Two years later Taku Kudo and John Richardson at Google packaged the production version as SentencePiece. By 2024 LLaMA 3 was using a vocabulary of 128 thousand BPE tokens to cover every language and every programming language at once. Same algorithm. Bigger pile of text.
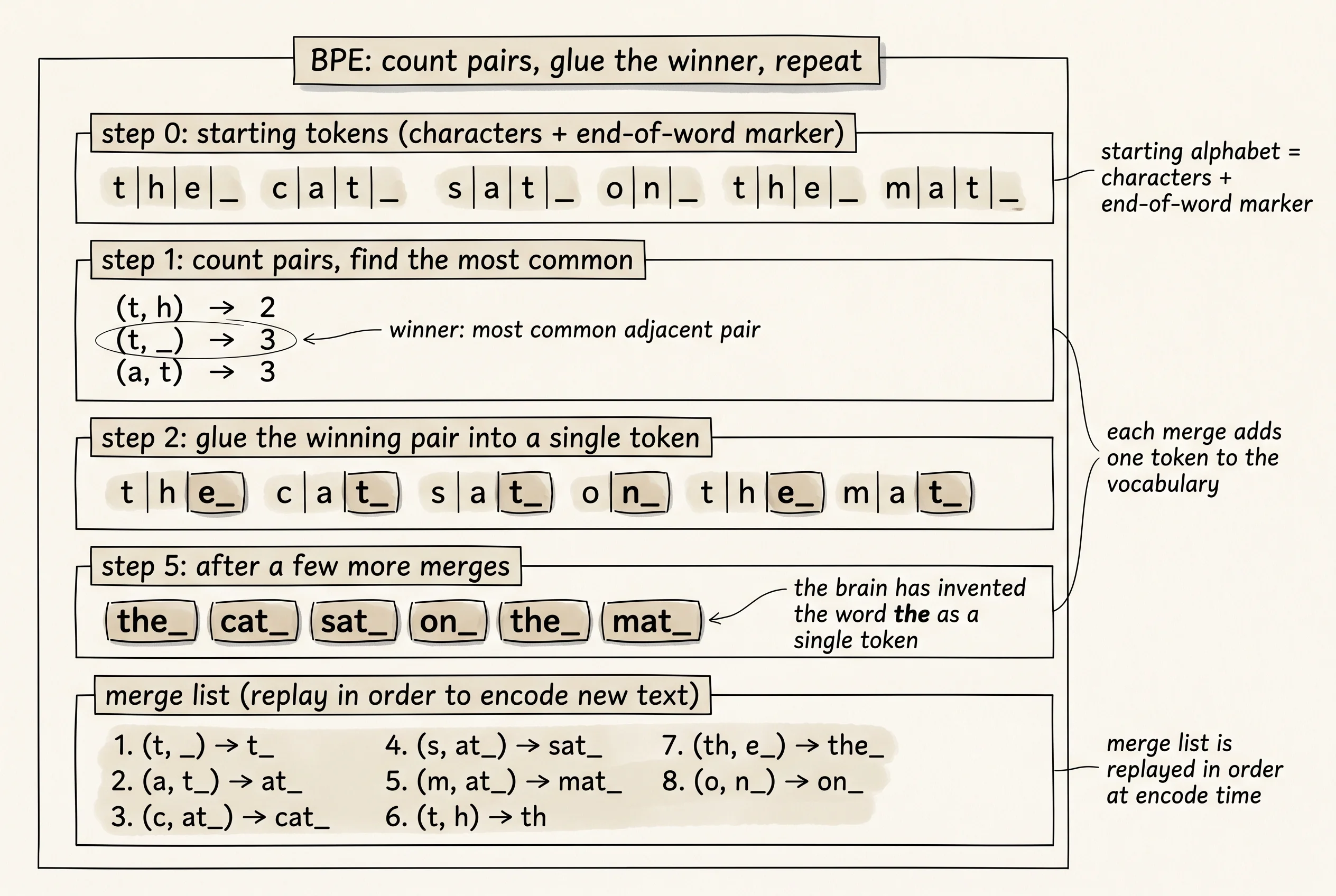
The previous lesson built a transformer that operates on tokens. The lesson before that built a network that looks up an embedding for each token. Neither lesson said where the tokens come from. If you tokenize by character, every sentence becomes hundreds of tiny tokens and the model spends most of its attention budget on letters instead of meaning. If you tokenize by word, the vocabulary explodes — English alone has hundreds of thousands of words, and any word the model has never seen during training is a hole the model cannot fill. BPE sits between the two. The brain learns its own alphabet, starting from raw characters, and grows the alphabet upward by gluing the most common adjacent pairs into single tokens. Common words like the end up as 1 token. Rare words like Donaudampfschifffahrtsgesellschaft end up as a handful of subword tokens. The vocabulary stays small, the sequences stay short, and no input ever fails to encode.
Open projects/41-bpe-tokenizer/main.py. The training corpus is a few paragraphs about a cat, a dog, and a cottage by a river. The first job is to count how often each word appears, because every word is going to be processed many times during training and the count tells the algorithm how much that word matters.
from collections import Counter
def split_corpus_into_word_counts(text: str) -> Counter[str]:
return Counter(text.split())Each word starts life as a tuple of single characters with an end-of-word marker glued on the end. The marker is the trick that keeps the tokenizer honest. Without it, a t at the end of cat and a t in the middle of cattle would glue with the same neighbors and the encoder would lose track of word boundaries.
END_OF_WORD = "</w>"
def word_to_initial_tokens(word: str) -> tuple[str, ...]:
return tuple(list(word) + [END_OF_WORD])The word the becomes ('t', 'h', 'e', '</w>'). The word cat becomes ('c', 'a', 't', '</w>'). The starting vocabulary is just the alphabet plus the marker — about 27 tokens for plain English text.
The merge loop is the heart of BPE. Tally every adjacent pair across every word in the table, weighted by how many times that word appears. Find the most common pair. Replace it everywhere with a single glued token. Add a new entry to the merge list. Repeat until the vocabulary hits a target size.
def count_adjacent_pairs(word_table):
pair_counts = Counter()
for tokens, word_count in word_table.items():
for index in range(len(tokens) - 1):
pair = (tokens[index], tokens[index + 1])
pair_counts[pair] += word_count
return pair_counts
def merge_pair_in_word(tokens, pair):
merged = []
index = 0
pair_left, pair_right = pair
glued = pair_left + pair_right
while index < len(tokens):
end = index == len(tokens) - 1
if not end and tokens[index] == pair_left and tokens[index + 1] == pair_right:
merged.append(glued)
index += 2
else:
merged.append(tokens[index])
index += 1
return tuple(merged)Run the script and watch the first 50 merges scroll by. The order they happen in is the order English text wants to glue itself together.
merge 1: ('e', '</w>') -> 'e_' (seen 79 times)
merge 2: ('t', 'h') -> 'th' (seen 70 times)
merge 3: ('th', 'e_') -> 'the_' (seen 64 times)
merge 4: ('a', 't') -> 'at' (seen 26 times)
merge 5: ('o', 'n') -> 'on' (seen 22 times)
merge 7: ('i', 'n') -> 'in' (seen 20 times)
merge 16: ('i', 'on_') -> 'ion_' (seen 12 times)
merge 19: ('in', 'g_') -> 'ing_' (seen 10 times)
merge 20: ('c', 'at_') -> 'cat_' (seen 9 times)
merge 25: ('do', 'g_') -> 'dog_' (seen 8 times)
merge 32: ('t', 'ion_') -> 'tion_'(seen 6 times)The brain glues e</w> first because half the words in English end in an e. It glues th next because no two letters in English love each other more. By merge 3 it has invented the word the as a single token, and that one token covers 64 of the 222 words in the training corpus. By merge 19 it has built ing_ — the suffix that turns half the verbs in English into their present participle. By merge 32 it has built tion_ — the suffix that turns verbs into nouns. The brain is teaching itself morphology by counting. Nobody told it that English has prefixes and suffixes. The only thing in the loop is the rule "glue the most common adjacent pair." That rule plus a few hundred iterations is enough to rediscover the structure of the language.
A small question. Why does the end-of-word marker appear in so many of the early merges (e_, the_, ing_, tion_, cat_, dog_)? The brain is not just learning syllables. It is learning where words tend to end. The suffix ing only matters if it sits at the end of a word. Without the marker, ing in singer and ing in singing would be the same token and the brain would glue both into the same thing. With the marker, ing</w> is its own token and ing in the middle of a word stays separate. The marker is how BPE respects word boundaries while still being free to merge across them when it makes sense.
Encoding a new piece of text means replaying the merge list in the order it was learned. Apply merge 1 to every word, then merge 2, then merge 3, and so on. The result is the shortest token sequence the merges can produce.
def encode_word(word, merges):
tokens = word_to_initial_tokens(word)
for pair in merges:
tokens = merge_pair_in_word(tokens, pair)
return list(tokens)The same sentence tokenized 3 ways shows what BPE is actually buying.
text: 'the celebration of the harvest'
characters (30 tokens): ['t','h','e',' ','c','e','l','e','b','r','a','t','i','o','n',' ', ...]
words ( 5 tokens): ['the','celebration','of','the','harvest']
bpe (15 tokens): ['the_','c','el','e','b','r','ation_','of_','the_','ha','r','v','e','st','_']Character tokens never fail but use 30 slots. Word tokens use 5 but the word harvest never appeared in training, so a real word tokenizer would die on it. BPE uses 15 slots and handles every word by reaching for subword pieces it knows. The word the gets its own token both times because the brain learned it. The word celebration gets split into c, el, e, b, r, ation_ because the brain learned the suffix ation_ from words like celebration and tradition, but did not see enough celeb clusters to glue them. The word harvest is brand new and the brain spells it out almost letter by letter, only gluing the st it learned from words like stone and station. No input fails. No vocabulary explodes.

Across the whole training corpus the compression numbers tell the same story.
characters: 1161 tokens (1.00 chars per token)
words: 222 tokens (5.23 chars per token)
bpe: 380 tokens (3.06 chars per token)Character-level is the longest possible sequence. Word-level is the shortest possible sequence but every unseen word breaks. BPE is roughly 3 times shorter than character-level and only twice as long as word-level, while keeping the safety net of being able to spell anything. Every modern frontier model — GPT-4, Claude, Gemini, LLaMA — sits in this same trade-off. They train on trillions of characters and end up with vocabularies of 50 thousand to 200 thousand BPE tokens. The compression ratio they hit on real text is closer to 4 characters per token, because their corpora are huge and the merges they learn are sharper.
Decoding is the easy half. Replace each token id with its token string, glue the strings inside a word together, and break on the end-of-word marker.
def decode(token_ids, id_to_token):
pieces = []
current = []
for token_id in token_ids:
token = id_to_token[token_id]
if token.endswith(END_OF_WORD):
current.append(token[: -len(END_OF_WORD)])
pieces.append("".join(current))
current = []
else:
current.append(token)
return " ".join(pieces)The round trip works for every input the brain trained on, and works for every input it did not, because the worst case is single-character tokens and those are always in the vocabulary.
in : 'the celebration of the harvest'
ids: [0, 35, 91, 3, 71, 11, 26, 1, 0, 73, 11, 38, 3, 39, 6]
out: 'the celebration of the harvest' [ok]The 15 ids on the middle line are what the transformer from the previous lesson actually sees. The embedding lookup turns each id into a vector, the attention layers shuffle the vectors against each other, the output layer predicts the next token id, and the BPE decoder turns that id back into characters a human can read. The brain you have built across the last 30 lessons reads and writes in this private alphabet that it learned from the raw pixels of text.
The tokenizer is the input layer. The transformer is the engine. Pretraining, supervised fine-tuning, and preference alignment are what turn a token predictor into something that holds a conversation, which is the next lesson.