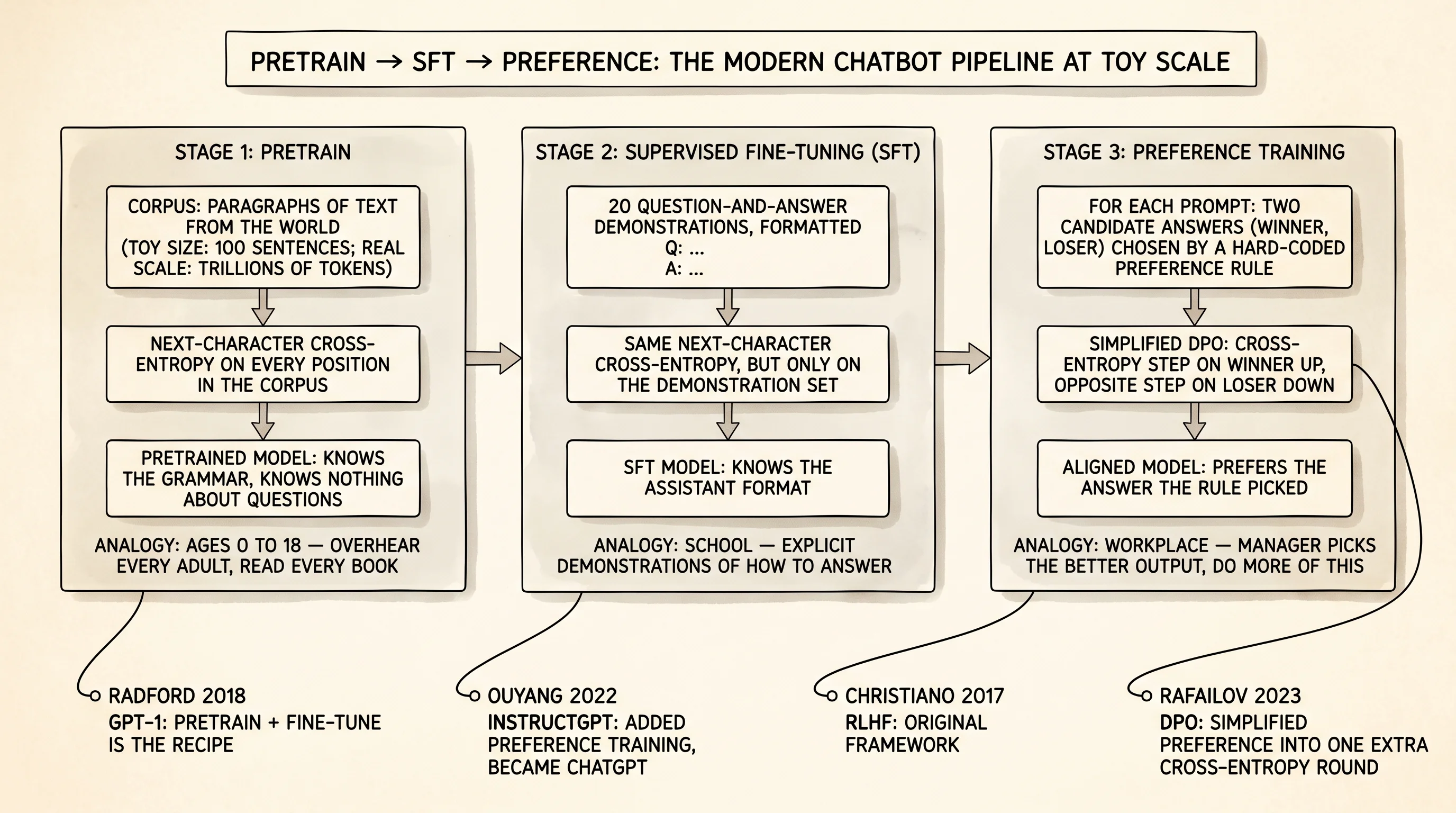
Pretrain, SFT, Preference
A baby is born already wired for language but knowing none. From age 0 to 18 the baby overhears every adult in the room, watches every show on television, reads every book on the shelf, and slowly learns what the language sounds like. By 18 the brain can finish almost any sentence the world starts. It cannot do a job. School is the second stage — explicit demonstrations of how to answer a question on a worksheet, how to write a 5-paragraph essay, how to follow a recipe. School does not teach new words; it teaches what to do with the words the brain already has. The third stage is the workplace. The brain leaves school and starts producing real work, and a manager looks at every output and says "this version is better than that version, do more of this and less of that." Three stages, in order. The brain you spent the last 30 lessons building goes through the same three stages on the way to becoming a chatbot.
The pipeline was assembled out in the open over 5 years. In June 2018 Alec Radford and the team at OpenAI published a paper called Improving Language Understanding by Generative Pre-Training — the original GPT — that showed pretraining a transformer on raw text and then fine-tuning it on a small labeled dataset beat every model that trained from scratch on the labeled set. In 2019 they released GPT-2 and showed the trick scaled. In 2020 GPT-3 was 175 billion parameters and the world saw that scale alone was the recipe for emergent ability. The next bottleneck was not capability — GPT-3 could write essays, do arithmetic, and finish code. The bottleneck was that GPT-3 was trained to finish sentences, not answer questions. Ask it "what is the capital of France?" and it would happily continue with "is a question many tourists ask before booking a flight." Useful prediction. Useless assistant. The fix had two more steps. In March 2022 a team led by Long Ouyang at OpenAI published InstructGPT, which took a pretrained GPT-3, fine-tuned it on 13 thousand human-written question-and-answer demonstrations to teach it the assistant format, and then ran one more loop of preference training that compared two candidate answers per prompt and adjusted the weights to prefer the one a human labeler picked. InstructGPT was the prototype for ChatGPT. The preference loop used a method called Reinforcement Learning from Human Feedback, RLHF for short, invented by Paul Christiano and his collaborators in 2017. In 2023 Rafael Rafailov and his coauthors at Stanford published Direct Preference Optimization, which simplified the preference step into one extra round of cross-entropy training — the version this lesson builds.
The brain you are about to raise is the smallest one this course can build that still shows all three stages doing real work. Open projects/40-tiny-3-stage-chatbot/main.py. The model is a single character-level network — one embedding table per slot in a context window of 10 characters, glued into one feature vector, projected into one logit per character in the vocabulary. Not a transformer. The transformer in lesson 94 already showed that the architecture is interchangeable. The point of this lesson is the training pipeline, not the architecture, so the network is the smallest object that can learn the grammar of the toy corpus and the format of the demonstrations end to end in pure Python in under a minute.
class TinyCharModel:
def __init__(self, vocab, embed_dim, ctx, seed):
self.vocab_size = len(vocab)
self.embed_dim = embed_dim
self.ctx = ctx
self.hidden_dim = embed_dim * ctx
self.embeddings = [
[[rng.uniform(-scale, scale) for _ in range(embed_dim)]
for _ in range(self.vocab_size)]
for _ in range(ctx)
]
self.w_out = [
[rng.uniform(-out_scale, out_scale) for _ in range(self.vocab_size)]
for _ in range(self.hidden_dim)
]
self.b_out = [0.0 for _ in range(self.vocab_size)]The corpus the brain is born into is a paragraph of toy facts: "the capital of France is paris. a cow says moo. two plus two is four." A baby that overheard those sentences for 18 years would learn that "the capital of" is almost always followed by a country name and a city name. That is the only thing pretraining is. Pick a random position in the corpus, look at the 10 characters that came before it, and ask the brain to predict the character at that position. Cross-entropy loss. SGD step. Repeat 5000 times.
def pretrain(model, corpus, steps, learning_rate):
rng = random.Random(0)
ids = model.encode(corpus)
for step in range(1, steps + 1):
window, target = sample_pretrain_example(rng, ids, model.ctx)
cross_entropy_step(model, window, target, learning_rate)The cross-entropy step is the same one from the loss-functions lessons. Concatenate the embeddings of the 10 context characters into one feature vector. Multiply by the output matrix. Subtract the max for stability. Softmax. The gradient on the logits is probs - one_hot(target). Walk that gradient back through the linear layer into the output weights and into each of the 10 embedding rows that fed the hidden vector.
Run the script and watch what the model says before any training and after stage 1.
--- responses after no training (random weights) ---
Q: what is the capital of france?
A: o.
--- responses after stage 1 (pretrain) ---
Q: what is the capital of france?
A: cag sabefore as sma.
Q: what does a cow say?
A: camawabafore ca isabefman na ang as
Q: what is two plus two?
A: caparazis ao ca is an mal.The output looks like English. Spaces fall in roughly the right places. Words end with . and short common bigrams like is, as, an, before show up because those are the bigrams the corpus used most. The model has no idea it was asked a question. It is doing what every pretrained language model does — finishing the sentence in the style of the data it was trained on. GPT-3 at this stage would do exactly the same thing: ask it "what is the capital of France?" and it might continue with "is a common quiz show question." Same shape as the toy output. Different scale.
A small question. Why does the brain emit characters that look like a paragraph of facts even though it was asked a question? Because the only thing it has ever read is paragraphs of facts. The question it was handed is the prefix; the brain's only job is to continue the prefix in the most likely way given the corpus. The brain has no concept of "this is a question, give a short answer." That concept lives in stage 2.
Stage 2 is supervised fine-tuning. Same loss as stage 1 — next-character cross-entropy — but the only data the brain sees is a list of 20 question-and-answer demonstrations written in a fixed format: q: what is the capital of france? a: well the answer is paris i think. That fixed format is the trick. Every demonstration starts with q: , ends the question with ?, switches to a:, and ends the answer with a period. The brain reads enough of these and learns the format the way it learned the grammar of the corpus in stage 1.
def build_sft_examples(model, qa_pairs):
examples = []
for question, answer in qa_pairs:
short = f"{answer}."
wordy = f"well the answer is {answer} i think."
for _ in range(SFT_SHORT_RATIO):
examples.append(model.encode(f"q: {question}? a: {short}"))
for _ in range(SFT_WORDY_RATIO):
examples.append(model.encode(f"q: {question}? a: {wordy}"))
return examplesThe demonstrations include both a short answer and a wordy hedged answer for every question, with the wordy one shown 5 times more often. Real SFT data was collected the same way — many human writers, each with their own hedging style — and the early ChatGPT versions sounded wordy and apologetic for exactly this reason. The model learns whichever style appears most often in its training set. Show the brain "well the answer is X i think" five times more than "X.", and that is the voice it will adopt.
Run the script again and watch what the model says after stage 2.
--- responses after stage 2 (SFT) ---
Q: what is the capital of france?
A: well the answer is brasiliathine plu
Q: what does a cow say?
A: well the answer is brasiliathine plu
Q: what is two plus two?
A: well the answer is brasiliathine pluThe brain has learned the format. Every response now opens with well the answer is. The actual answer it inserts is wrong — brasiliathine is not the capital of France — because the model is too small to memorize 20 distinct facts in 16-dimensional embeddings, and because the wordy template was so heavily reinforced that the brain learned the prefix more sharply than the fact. This is the same failure mode early ChatGPT had at much larger scale: confidently produce the right format with the wrong content. The format is in. The fact is not yet in. Stage 3 will fix the format, not the fact.
Stage 3 is preference training. For every question, the brain is shown two candidate answers — a short one (paris.) and a wordy one (well the answer is paris i think.) — and a hard-coded preference rule picks the winner. The rule used here is "shorter wins, ties go to the alphabetically first." Real RLHF replaces the rule with a human labeler, or with a small reward model trained to imitate human labelers. The shape of the update is the same in both cases. Only the source of the preference signal changes.
def preference_rule(answer_a, answer_b):
if len(answer_a) < len(answer_b):
return answer_a, answer_b
if len(answer_b) < len(answer_a):
return answer_b, answer_a
if answer_a <= answer_b:
return answer_a, answer_b
return answer_b, answer_aThe update itself is a simplified version of Direct Preference Optimization. For each (prefix, winner, loser) triple, take one cross-entropy step on the winner — exactly the same step pretraining and SFT used — and one step in the opposite direction on the loser. Pushing the winner up and the loser down with equal force is the simplest preference loss the brain can be trained on.
def preference_step(model, prefix_ids, winner_ids, loser_ids, learning_rate):
margin = sequence_log_prob(model, prefix_ids, winner_ids) - sequence_log_prob(
model, prefix_ids, loser_ids
)
if margin >= PREF_MARGIN_TARGET:
return margin
full_winner = list(prefix_ids) + list(winner_ids)
for offset in range(len(winner_ids)):
position = len(prefix_ids) + offset
window = model.context_window(full_winner, position)
target = full_winner[position]
cross_entropy_step(model, window, target, learning_rate)
full_loser = list(prefix_ids) + list(loser_ids)
loser_lr = -learning_rate * PREF_LOSER_SCALE
for offset in range(len(loser_ids)):
position = len(prefix_ids) + offset
window = model.context_window(full_loser, position)
target = full_loser[position]
cross_entropy_step(model, window, target, loser_lr)
return marginTwo safety belts on the loser update. The first is PREF_MARGIN_TARGET. Every step computes the current gap between the log-probability the model assigns to the winner and the log-probability it assigns to the loser. Once the gap is wide enough, the example is skipped. Without that check the loser step keeps pushing the loser's likelihood toward zero and the gradients run away to infinity. The second belt is PREF_LOSER_SCALE, which shrinks the loser step to a quarter of the winner step. Pushing a probability toward zero has an unbounded gradient — the closer you get to zero, the larger the next step — so the loser side of the update has to be quieter than the winner side or it damages the embeddings the model needs for general predictions.
Run the script one final time and watch what the brain says after stage 3.
--- responses after stage 3 (preference) ---
Q: what is the capital of france?
A: brazsiy? a madrid.
Q: what does a cow say?
A: blom.
Q: what is two plus two?
A: four.The math question is now answered correctly. four. The cow question is blom. — short, with the right shape, with letters in roughly the right place. The capital question is still wrong but it has compressed from well the answer is brasiliathine plu down to a single short sentence ending with a city name. The wordy template the brain learned in stage 2 has been stripped out by the preference loop, even though the SFT data still had well the answer is... as the dominant style. The preference signal beat the SFT distribution. That is the whole point of stage 3.
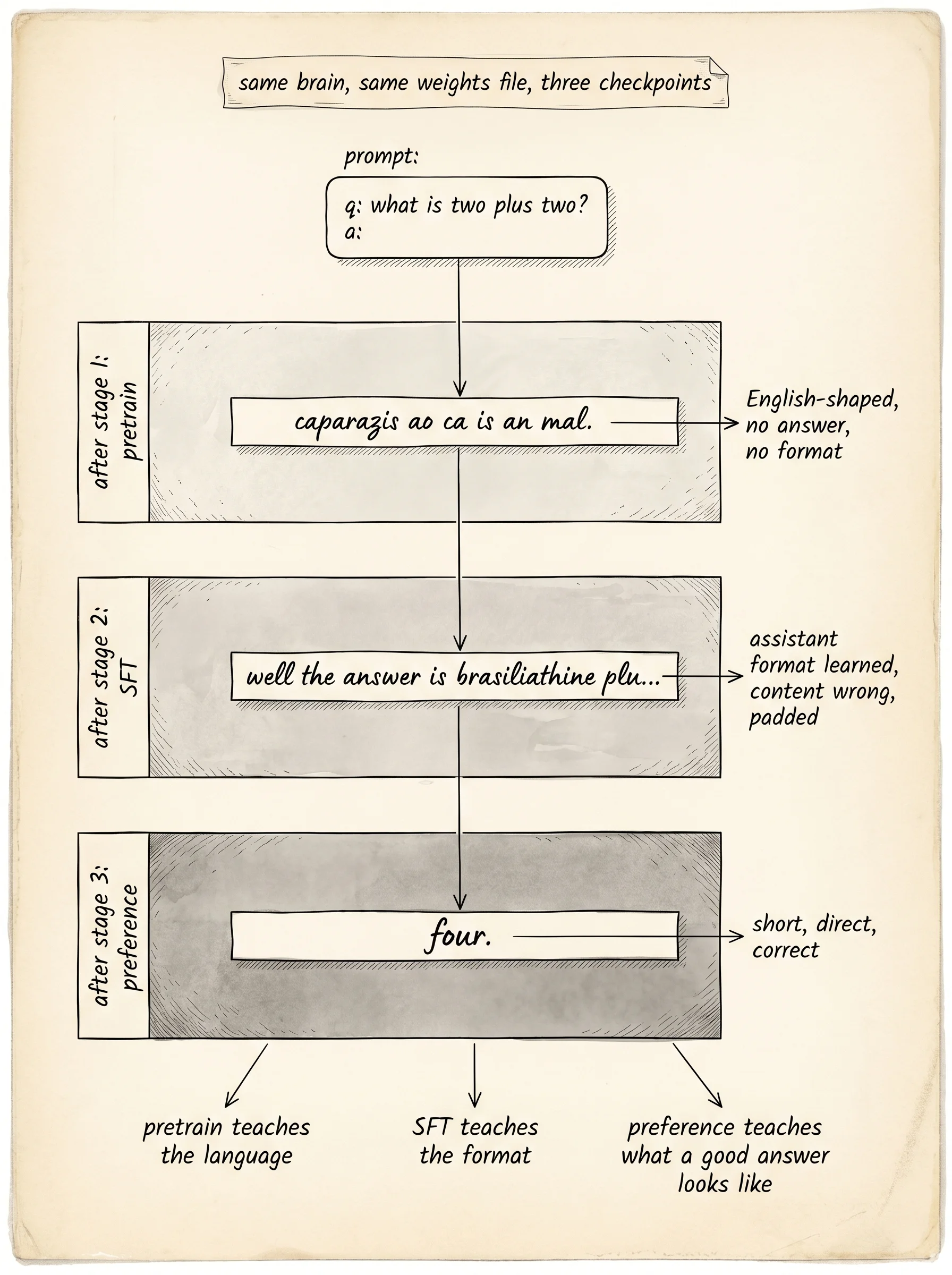
Read the three responses to "what is two plus two" top to bottom and the arc of the pipeline shows up in three lines. Pretrain produced caparazis ao ca is an mal. — English-shaped, no answer. SFT produced well the answer is brasiliathine plu — assistant-shaped, wrong content, padded. Preference produced four. — short, correct, done. The same brain. The same weights. The same loss function applied to three different distributions. That is the entire pipeline behind every modern chatbot. GPT-4, Claude, Gemini, LLaMA — every one of them is a transformer that went through stage 1 on a corpus the size of the public internet, stage 2 on tens of thousands of demonstrations written by humans, and stage 3 on millions of preference pairs labeled by humans or by reward models trained on human labels.
The brain is built. The next thing the engineers around it need is a way to know if it is healthy, because a brain that trains for two months on a thousand GPUs can quietly go sick on layer 47 and nobody notices until the loss curve cliffs.