Softmax and Temperature
The same softmax that lived inside cross-entropy as a scoring trick has a second job that nobody mentions until the model is done training. It is the dimmer switch on the brain. Turn the dial one way and the network becomes a robot that picks the highest-scoring word every time and says the same flat sentence forever. Turn the dial the other way and the network becomes a poet, willing to grab the 12th-most-likely word and run with it. The dial is one number called temperature. Pick a low temperature and ChatGPT writes you boilerplate that any other prompt would have produced. Pick a high temperature and it writes you something you have never read before — usually because nobody would ever write it.
The functional form of softmax did not come from neural networks. It came from a Vienna physicist in the 1870s. Ludwig Boltzmann was trying to explain why a sealed box of gas eventually settles into a predictable temperature even though every molecule inside is bouncing around at a different speed. He wrote down a formula that gave the probability of a molecule sitting at each possible energy level: take e to the power of negative energy over a temperature constant, divide by the sum of those exponentials over every energy the molecule could have. The exponential made low-energy states overwhelmingly more popular than high-energy ones, and the temperature controlled how much that gap mattered. At low temperature almost every molecule sits at the lowest energy level. At high temperature the energies spread out and the molecule could be anywhere. This is exactly the formula that softmax runs every time it converts logits into probabilities. The temperature in a language model is the temperature in a gas — a single knob that decides whether the system collapses to one outcome or fans out across many.
The formula sat in physics textbooks for 120 years before a man named John Bridle moved it into machine learning. Bridle worked at the British Royal Signals and Radar Establishment in the late 1980s on speech recognition. The networks of his day spit out raw scores for each phoneme and trained those scores to be high for the right answer and low for the wrong answer, but the scores were not probabilities — they did not add up to 1, they could be negative, and you could not compare two different networks because their score scales drifted. In 1990 he published a paper called Probabilistic Interpretation of Feedforward Classification Network Outputs with a single recommendation: take the Boltzmann formula, drop the energy and substitute the network's logits, and read the result as a probability distribution over classes. He named the function softmax because it is a soft version of the function that picks the maximum — at low temperature it really is the max, at high temperature it spreads across every option. Every modern language model from GPT-2 to Claude reads its final softmax exactly the way Bridle wrote it 35 years ago.
The math is two lines. Take a list of logits — any real numbers, positive or negative, no constraints. Divide every logit by the temperature. Exponentiate each scaled logit. Divide by the sum so the answers add to 1. The dividing-by-temperature step is the only thing the language-model crowd added on top of Bridle's paper, and it is the entire mechanism behind what people call "creativity" in chat models.
import math
def softmax(logits, temperature=1.0):
scaled = [value / temperature for value in logits]
largest = max(scaled)
exps = [math.exp(value - largest) for value in scaled]
total = sum(exps)
return [value / total for value in exps]Read what dividing by the temperature does. Take a small example: logits [2.0, 1.0, 0.5]. At temperature 1.0 those are already the inputs to softmax and the gaps between them are kept at face value. At temperature 0.1 they become [20.0, 10.0, 5.0] — the gaps are 10 times wider. After exponentiating, the largest one absolutely dominates and the smallest is invisible. At temperature 10.0 they become [0.2, 0.1, 0.05] — the gaps are 10 times narrower. After exponentiating, all three are nearly equal. The logits never moved. Temperature only scales how much the gaps matter.
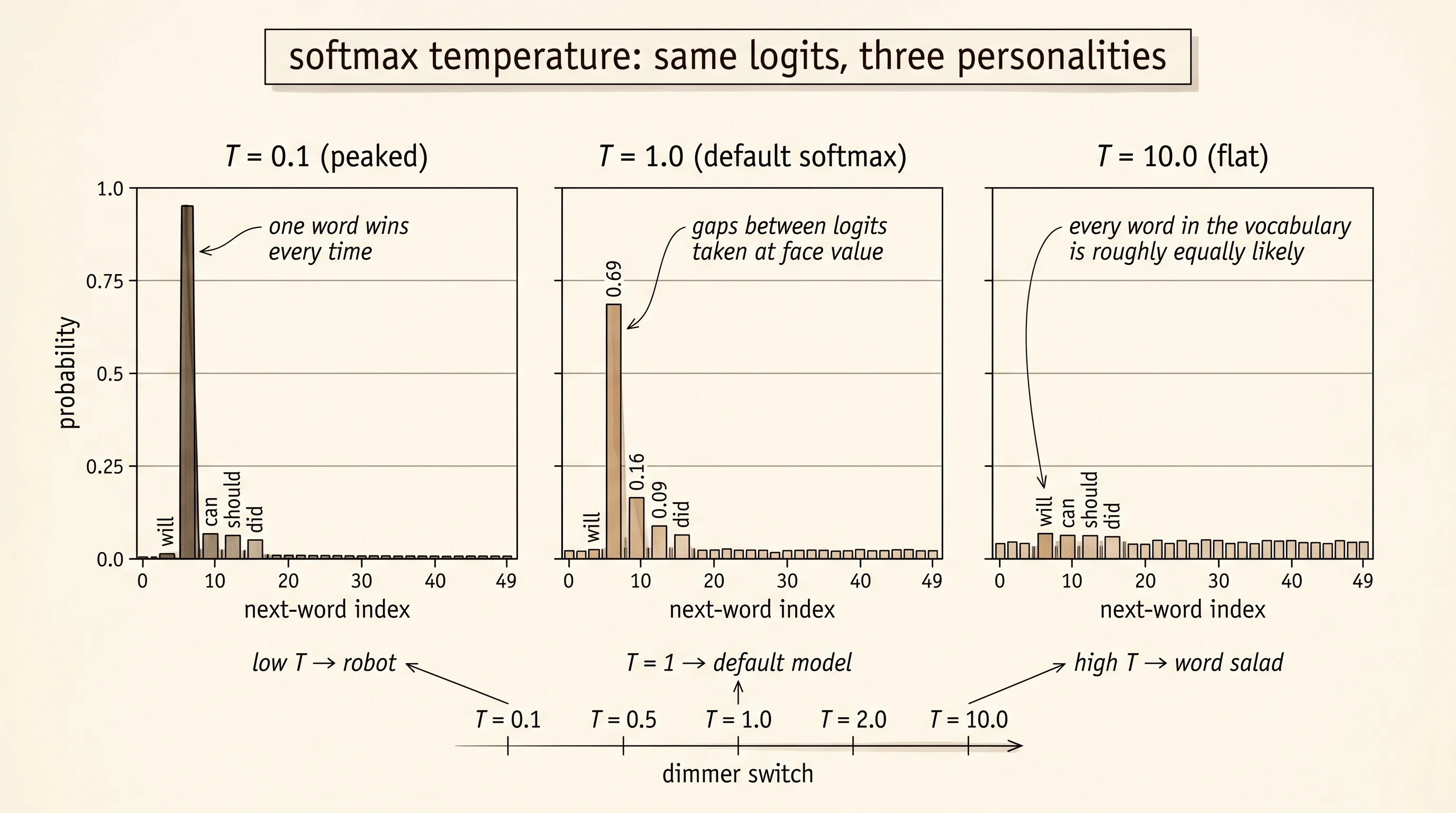
To watch the dimmer switch turn, give the network a fixed row of logits and run softmax at five different temperatures. Pretend the network has just been shown the word "I" and is deciding what comes next. The model has been wired so that "will" gets a logit of 6.5, "can" gets 5.0, "should" gets 4.5, "did" gets 4.0, and 45 other words sit way back at -3.0. That is not a real language model. It is a hand-built table you can fit on a single page and reason about in your head.
logits_after_i = [6.5, 5.0, 4.5, 4.0, *[-3.0] * 46]
for temperature in [0.1, 0.5, 1.0, 2.0, 10.0]:
probabilities = softmax(logits_after_i, temperature=temperature)
top_three = sorted(probabilities, reverse=True)[:3]
print(f"T={temperature}: {top_three}")The output traces the dimmer switch in motion.
T=0.1 [1.000, 0.000, 0.000]
T=0.5 [0.930, 0.046, 0.017]
T=1.0 [0.693, 0.155, 0.094]
T=2.0 [0.396, 0.187, 0.146]
T=10.0 [0.047, 0.041, 0.039]At temperature 0.1 the probability of "will" is essentially 1 and every other word is essentially 0. The network is a robot. At temperature 1.0 "will" still wins, but "can" gets 15.5% of the probability and "should" gets 9.4% — pick a sentence and you might see "I can run home" instead of "I will go home." At temperature 10.0 the four favored words all sit around 4% each. So do the 46 throwaway words. The network has lost its preferences entirely; the next word is essentially uniform random.
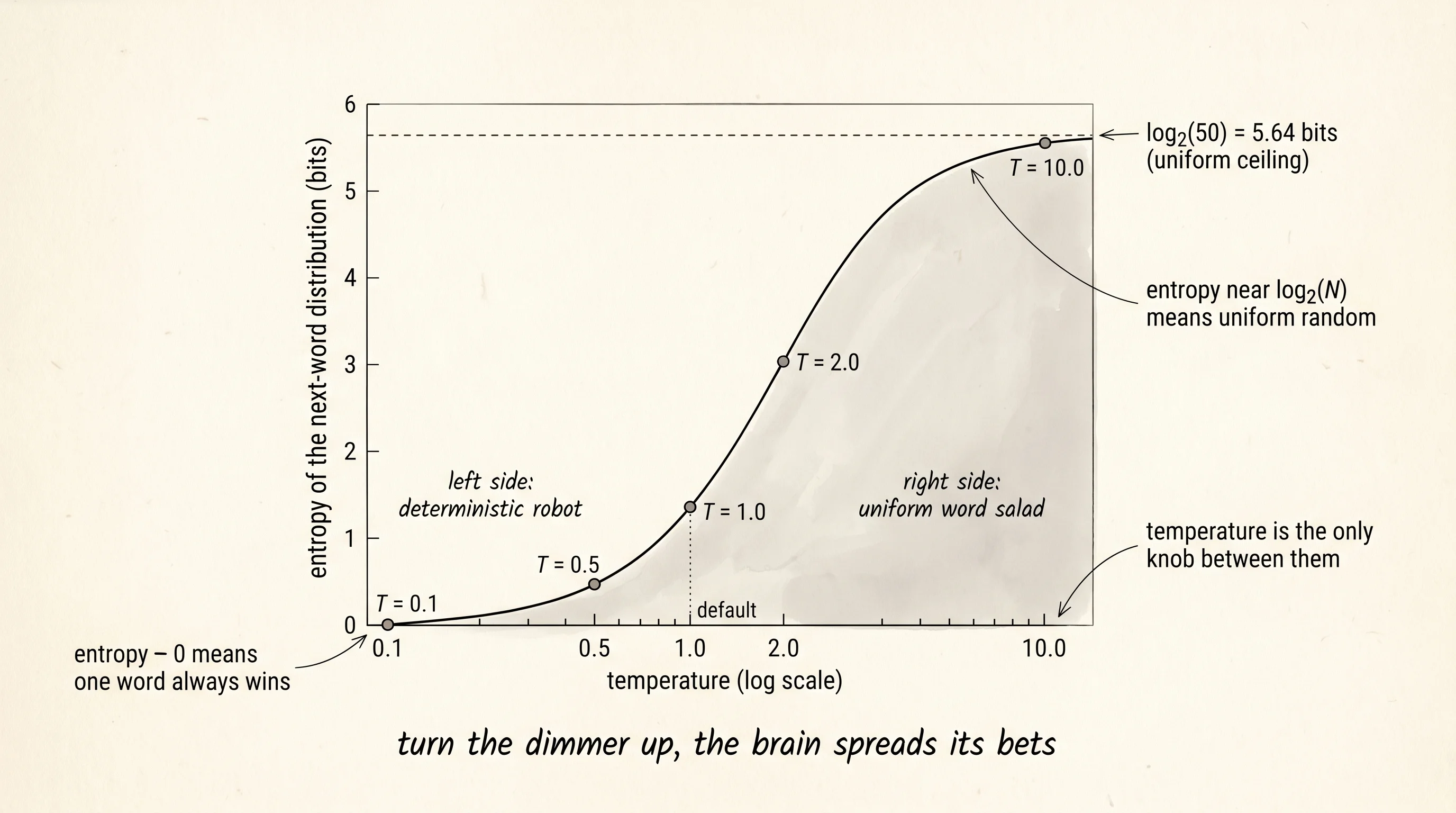
There is a single number that captures how spread out a distribution is, and it gives you a clean way to read the dimmer switch as a graph instead of a paragraph. Claude Shannon called it entropy. He measured the average surprise of a distribution in bits — how many yes-or-no questions you need to ask, on average, to guess which outcome happened. A distribution that always picks the same answer has 0 bits of entropy: you do not need to ask anything. A coin flip has 1 bit. A fair 8-sided die has 3 bits. A uniform distribution over the 50 words in this toy vocabulary has log₂(50) ≈ 5.64 bits.
def entropy(probs):
total = 0.0
for probability in probs:
if probability > 0.0:
total -= probability * math.log2(probability)
return totalRun the entropy calculation on the same five distributions and you get a clean ramp from 0 to the ceiling.
T=0.1 entropy = 0.000 bits (basically deterministic)
T=0.5 entropy = 0.448 bits
T=1.0 entropy = 1.373 bits
T=2.0 entropy = 3.034 bits
T=10.0 entropy = 5.590 bits (basically uniform across 50 words)Entropy starts at zero, climbs gradually, then saturates at log₂(50) as the distribution flattens. That ramp is the dimmer-switch curve. The temperature dial is on one axis. Surprise is on the other.
A distribution alone is not a sentence. To get a sentence the network has to actually pick a word — sample from the distribution. Sampling from a probability vector is one tiny function. Roll a uniform number between 0 and 1. Walk down the list adding probabilities to a running total. The first index where the running total passes your number is the sample. A word with 0.62 probability gets picked 62% of the time; a word with 0.001 probability gets picked once in a thousand rolls.
import random
def sample(probs):
threshold = random.random()
running = 0.0
for index, probability in enumerate(probs):
running += probability
if threshold < running:
return index
return len(probs) - 1Now stack the pieces. To generate a sentence, look up the row of logits for the current word, run softmax at your chosen temperature, sample the next word, append it, and repeat with the new word as the current word. This is autoregressive generation — each step uses the output of the previous step as its input. It is exactly how every chat model on the internet writes a reply, except real models have transition tables with 50,000 rows learned from the entire text of the open web instead of 50 rows you wrote by hand.
def generate_sequence(transition_table, start, length, temperature):
words = []
current = start
for _ in range(length):
logits = transition_table[current]
probs = softmax(logits, temperature=temperature)
next_index = sample(probs)
next_word = VOCABULARY[next_index]
if next_word == "<END>":
break
words.append(next_word)
current = next_word
return wordsThe transition table is the brain. Build one with about 50 words — verbs, nouns, articles, a few Minecraft terms, a few gym terms — and assign every row of logits by hand. The word "I" should strongly prefer modal verbs like "will" and "can." The word "will" should strongly prefer action verbs like "go" and "lift." The word "go" should strongly prefer "home" and the end-of-sentence marker. Keep the high logits at 4.0 to 6.5 and let everything else sit at -3.0. That gives the temperature room to work. At low temperature the model picks the obvious next word every time. At high temperature even the -3.0 words rise into the running.
Run the generator at the same five temperatures with the same starting state and read the five sentences side by side.
T=0.1 I will go home
T=0.5 I will run home
T=1.0 I will see the sword
T=2.0 you will play
T=10.0 see a fast I sword lift I ballSame brain. Same starting state. Same project file. Five different personalities. At T=0.1 the model picks the highest-logit word at every step — "I" leads to "will" which leads to "go" which leads to "home" which ends the sentence. Greedy and grammatical and identical every time. At T=1.0 the gaps between logits matter at face value, so the model picks "see" instead of "go" and walks into "the sword" — still a real sentence, just one of several real sentences it could have produced. At T=10.0 the distribution is nearly uniform across all 50 words, so the model grabs words at random — "see a fast I sword lift I ball" is grammatical noise. The same model that sounded like a robot at T=0.1 sounds like word salad at T=10.0. The only thing that changed was one division.
A small question. The model at T=1.0 produced "I will see the sword." The model at T=2.0 produced "you will play." Why is the T=2.0 sentence shorter? Because at higher temperature the end-of-sentence marker — which sat back at one of the lower logits — now has a real chance of being picked early. The same flattening that lets unusual content words win also lets the stop token win. Every token in the vocabulary, including the one that ends the generation, gets its probability bumped up. Long, weird sentences and short, abrupt sentences are both side effects of turning the dimmer up.
This is exactly the knob behind the "temperature" slider in every API for every chat model shipped today. ChatGPT, Claude, Gemini, every open-source model on Hugging Face — the same softmax-with-temperature loop. Companies stack tricks on top: top-k sampling chops the distribution to the k best words before sampling; top-p sampling chops it to the smallest set whose probabilities sum to p; repetition penalties down-weight words the model has already used. All of those are surgery performed on the probability vector after softmax. The vector itself comes from the same two lines you just wrote. The next big question is not how to choose the next word — you have that. It is how to set the logits in the first place so the choice is a good one.