Stride and Resolution
A 100-rung ladder takes 100 grabs to climb. Skip every other rung and you reach the top in 50. The view at the top is the same. The view halfway up is fuzzier — you covered the same wall in half the steps, so you noticed half as much about it. Stride is the ladder rule for a convolution. Stride 1 plants the kernel on every position. Stride 2 plants it on every other position. Stride 3 keeps one position in three. The output gets smaller. The compute gets cheaper. The price you pay is precision about where in the picture each match landed.
The visual cortex of a brain runs the same trick, top to bottom. The first layer of cells in V1 covers every patch of the retina. By the time the signal reaches V4 and IT, deep in the back of the head, each cell is reading a quarter of the visual field at once. The brain throws away spatial precision on purpose, because the front of the head needs to know "is there a face" much more than "in which exact pixel." A stack of strided convolutions is the same staircase wired in software. Yann LeCun's LeNet in 1989 already used stride 2 inside its convolution layers to step the resolution down. For 25 years, though, every architect put a separate pooling layer next to every convolution to do the downsampling. In 2015, Jost Springenberg, Alexey Dosovitskiy, Thomas Brox, and Martin Riedmiller at the University of Freiburg wrote a paper called Striving for Simplicity. They tore the pooling layers out of a state-of-the-art network, replaced each one with a single stride-2 convolution, and matched the accuracy. One operation did two jobs — extract features and shrink the map. Kaiming He's ResNet group at Microsoft Research adopted the same move that year and shipped it inside every "downsampling block" of every ResNet variant since.
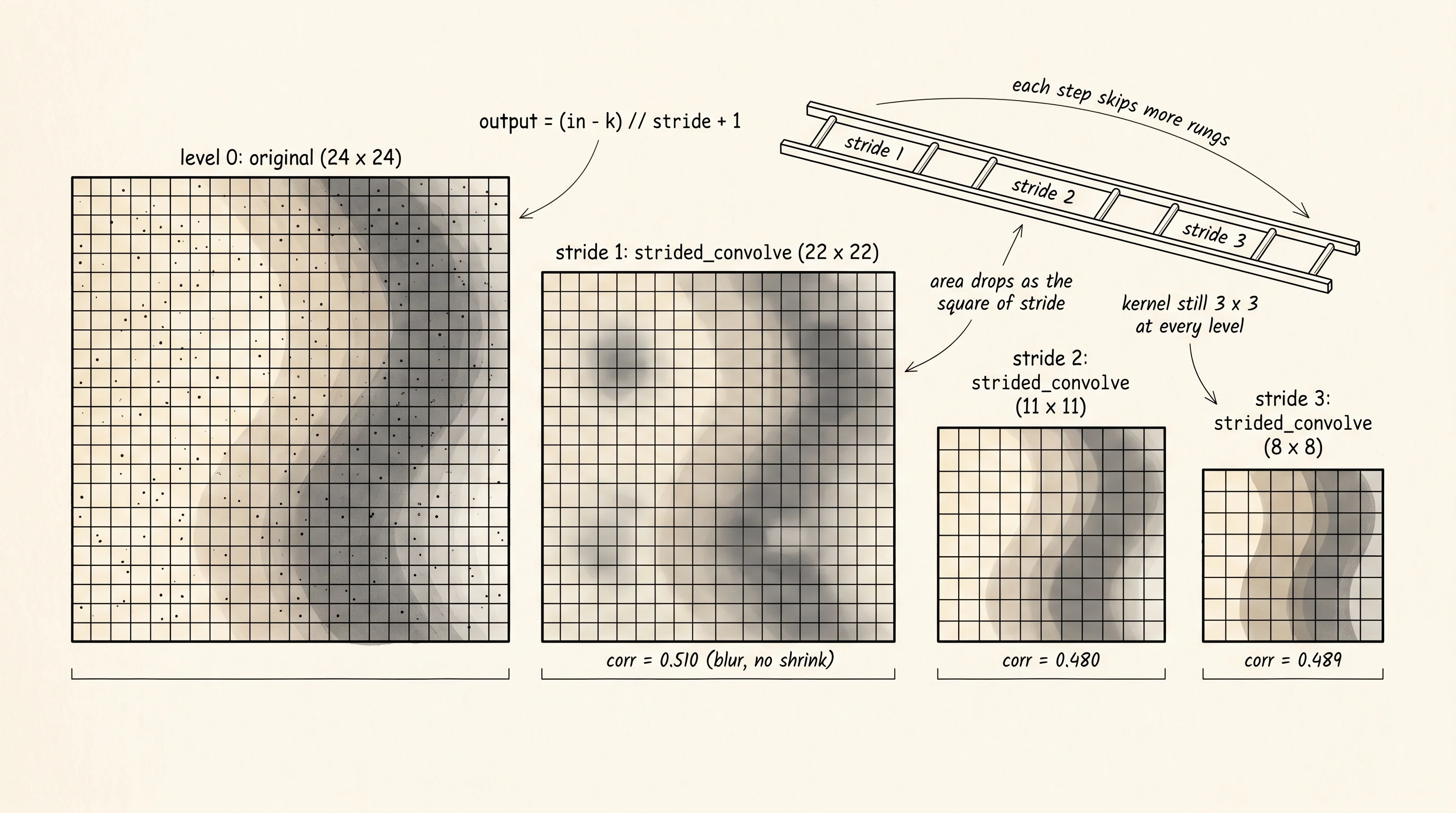
The arithmetic is one formula and you will use it for the rest of the section. An input of size in, a kernel of size k, padding p, and stride s produces an output of size (in + 2*p - k) // s + 1. Plug numbers in. A 24x24 image with a 3x3 kernel, no padding, stride 1 gives 22. Same image, stride 2 gives 11. Stride 3 gives 8. The output area drops as the square of the stride. Stride 2 cuts compute by 4. Stride 3 cuts it by 9. That is why every modern vision network leans on stride to shrink its maps.
def output_dimension(input_size, kernel_size, padding, stride):
return (input_size + 2 * padding - kernel_size) // stride + 1
print(output_dimension(24, 3, 0, 1))
print(output_dimension(24, 3, 0, 2))
print(output_dimension(24, 3, 0, 3))22
11
8The convolution loop barely changes from the previous lesson. Every output cell still sums the kernel weights times the matching input pixels. The only edit: the input row and column the kernel reads from is out_row * stride + k_row, not out_row + k_row. Multiply by stride and the kernel jumps farther between cells.
def strided_convolve(image, kernel, stride):
kernel_h = len(kernel)
kernel_w = len(kernel[0])
in_h = len(image)
in_w = len(image[0])
out_h = output_dimension(in_h, kernel_h, 0, stride)
out_w = output_dimension(in_w, kernel_w, 0, stride)
output = [[0.0 for _ in range(out_w)] for _ in range(out_h)]
for out_row in range(out_h):
for out_col in range(out_w):
total = 0.0
for k_row in range(kernel_h):
for k_col in range(kernel_w):
in_row = out_row * stride + k_row
in_col = out_col * stride + k_col
total += kernel[k_row][k_col] * image[in_row][in_col]
output[out_row][out_col] = total
return outputA strided convolution is one of two ways to shrink an image. The other is to keep every Nth pixel and throw the rest away. Naive subsampling is one line.
def naive_subsample(image, factor):
return [
[image[r][c] for c in range(0, len(image[0]), factor)]
for r in range(0, len(image), factor)
]The two methods produce maps of nearly identical size at the same factor. They behave very differently on a real picture. The project file at projects/20-multi-resolution-pyramid/main.py builds a 24x24 test image — two slow sinusoids for a smooth background, plus salt-and-pepper noise sprinkled on top — then downsamples it three ways at stride 1, stride 2, and stride 3. The kernel is a 3x3 box-blur where every weight is 1/9, which is the simplest possible learned-style kernel: every output cell is the average of the nine pixels under it. The blur softens the high-frequency texture before stride drops the resolution. Naive subsampling has no such softening. It stares straight at every Nth pixel and writes it down.
To compare the two methods fairly, both downsampled images are nearest-neighbor upsampled back to 24x24 and the Pearson correlation is computed against the original. Run the project.
python projects/20-multi-resolution-pyramid/main.pyThe opening lines confirm the formula and print the original image as ASCII shading.
output_dimension formula check:
in=24, k=3, pad=0, stride=1 -> 22
in=24, k=3, pad=0, stride=2 -> 11
in=24, k=3, pad=0, stride=3 -> 8The summary table is the print moment.
============================================================
stride method dims corr vs orig
------------------------------------------------------------
1 strided_convolve 22x22 0.510
naive_subsample 24x24 1.000
2 strided_convolve 11x11 0.480
naive_subsample 12x12 0.358
3 strided_convolve 8x8 0.489
naive_subsample 8x8 0.298
============================================================Read the table from the bottom up. At stride 3, naive subsampling holds only 0.298 correlation with the original. The strided convolution holds 0.489 — about 1.6 times more signal kept for the same output size. At stride 2 the gap is similar: 0.358 against 0.480. The strided convolve wins at every shrinking step. At stride 1 the picture flips: naive subsampling is the original (correlation 1.000), and the strided convolve drops to 0.510 because the box-blur smooths the picture even when nothing is being skipped. Stride 1 strided convolve is not a downsampler at all — it is a blur. The win shows up only when stride is greater than 1 and there is real high-frequency content that aliases under naive subsampling.
A small question. Why does the strided convolution win against naive subsampling exactly when the stride is greater than 1? The picture has noise that flickers from pixel to pixel. Naive subsampling at stride 2 picks one of those noisy pixels every other position and writes it down, so half the noise gets through and looks like signal. The strided convolution averages a 3x3 patch into one number first, which cancels the flicker before stride lands on its grid. Aliasing is the formal name for noise pretending to be signal once you sample too sparsely. The blur is what kills it. The same trick is why a digital camera puts a low-pass filter in front of the sensor before the sensor samples the light at its fixed pixel grid.
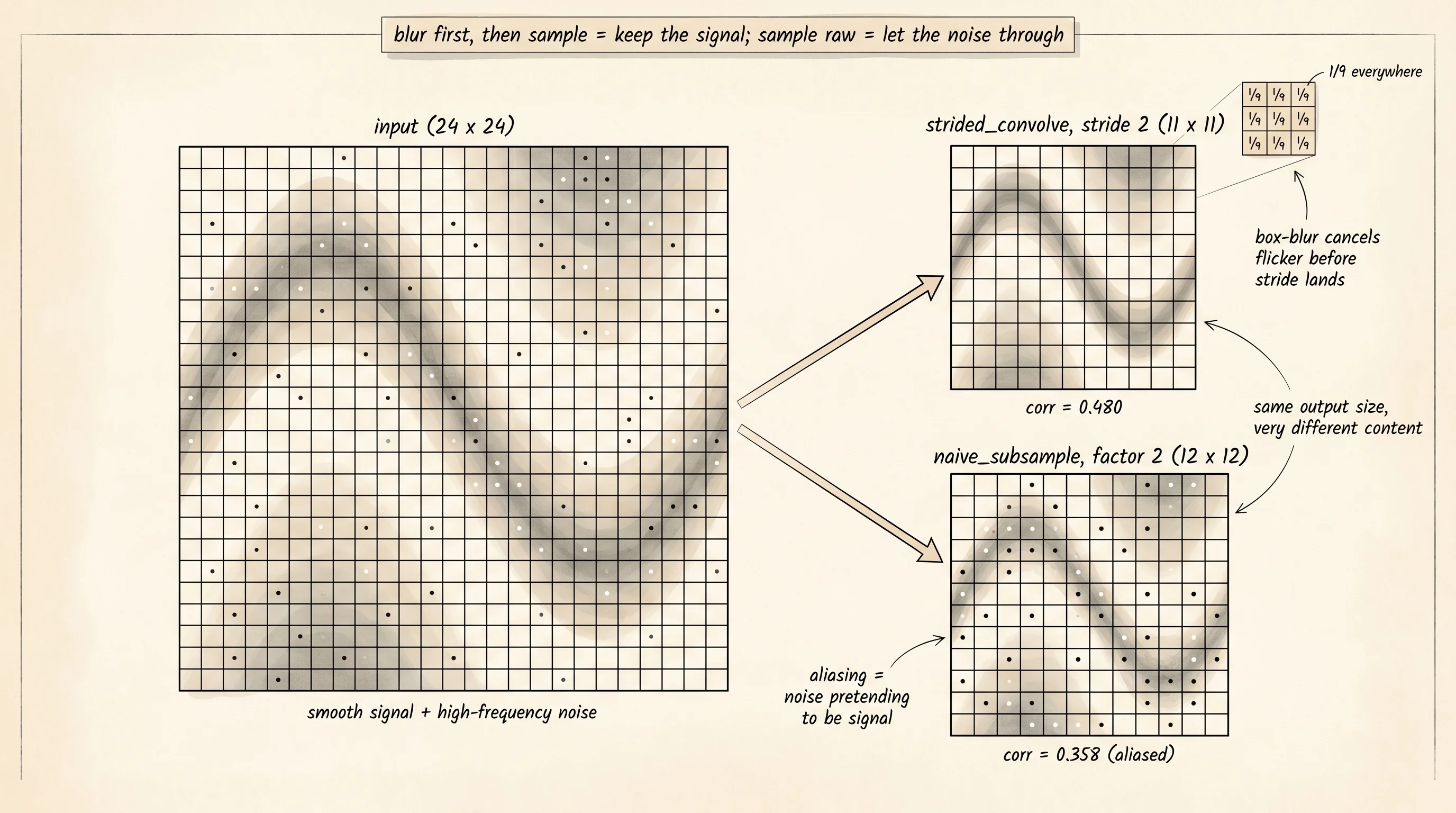
The box-blur kernel here is hand-picked: nine equal weights. Make those nine weights trainable instead and you get exactly the stride-2 convolution that lives inside a ResNet downsampling block. The forward pass is the same loop. The backward pass is the same loop with the upstream gradient swapped in for the kernel weight, the way the previous lesson built it. Gradient descent picks the nine numbers that keep the most useful signal at half the resolution for whatever task you train it on. That is what Striving for Simplicity meant by replacing pooling with strided convolution: trade a fixed averaging operation for a learned one and let the network decide what to throw away.
The pyramid printed at the end of the project run shows the same image at four resolutions stacked from full down to 8x8. Each level is half the previous level's compute on every layer above it. A network that reads a 224x224 photo and ends with a 7x7 feature map went down 5 strides of 2 to get there — 224 to 112 to 56 to 28 to 14 to 7 — and at each step every following layer ran on a quarter of the area. This is the staircase that lets a 50-layer ResNet finish in milliseconds on a single GPU.
Stride downsamples while learning what to keep. The next lesson does the opposite: it downsamples without any weights at all, by asking each window for the strongest signal it saw and throwing the position away.