RDS and Aurora
Picture a restaurant kitchen. You can hire a head chef, buy the stoves, schedule the prep cooks, and run payroll yourself — or you can rent a fully staffed kitchen that comes with everything except the recipes. RDS is the rented kitchen. Amazon owns the building, picks the brand of stove, swaps a broken oven at three in the morning, and hands you a hose to the dish you want to cook. You bring the menu — your schema, your queries, your data — and skip the part where you build the kitchen from scratch.
Amazon launched RDS in October 2009 starting with one stove brand — MySQL — because the early customers were rails shops on EC2 burning weekends keeping their database alive. Werner Vogels and the database team saw the same support ticket on repeat: a customer's primary fell over at 2am, the replica was behind, the backups had not been tested in months, and the whole company was down until someone with the right ssh key woke up. RDS bundled the boring, scary parts — patching, backups, point-in-time recovery, a one-click "promote this replica" button — and sold them as a checkbox. PostgreSQL arrived in 2013. Oracle, SQL Server, and MariaDB followed. None of those engines changed inside RDS — Amazon ran the same binaries the rest of the world ran. The product was the operations wrapped around them.
The shape of one deployment fits in a small struct. An instance has an engine, a size, a multi-AZ flag, and a list of read replicas.
#[derive(Copy, Clone, PartialEq, Eq)]
#[allow(dead_code)]
enum Engine {
Postgres,
MySql,
AuroraPostgres,
AuroraMySql,
}
struct DbInstance {
name: &'static str,
engine: Engine,
size: &'static str,
multi_az: bool,
read_replicas: Vec<String>,
}
impl DbInstance {
fn family(&self) -> &'static str {
match self.engine {
Engine::Postgres | Engine::MySql => "RDS",
Engine::AuroraPostgres | Engine::AuroraMySql => "Aurora",
}
}
fn engine_name(&self) -> &'static str {
match self.engine {
Engine::Postgres => "PostgreSQL",
Engine::MySql => "MySQL",
Engine::AuroraPostgres => "Aurora PostgreSQL",
Engine::AuroraMySql => "Aurora MySQL",
}
}
fn storage_copies(&self) -> u8 {
match self.family() {
"Aurora" => 6,
_ => 1,
}
}
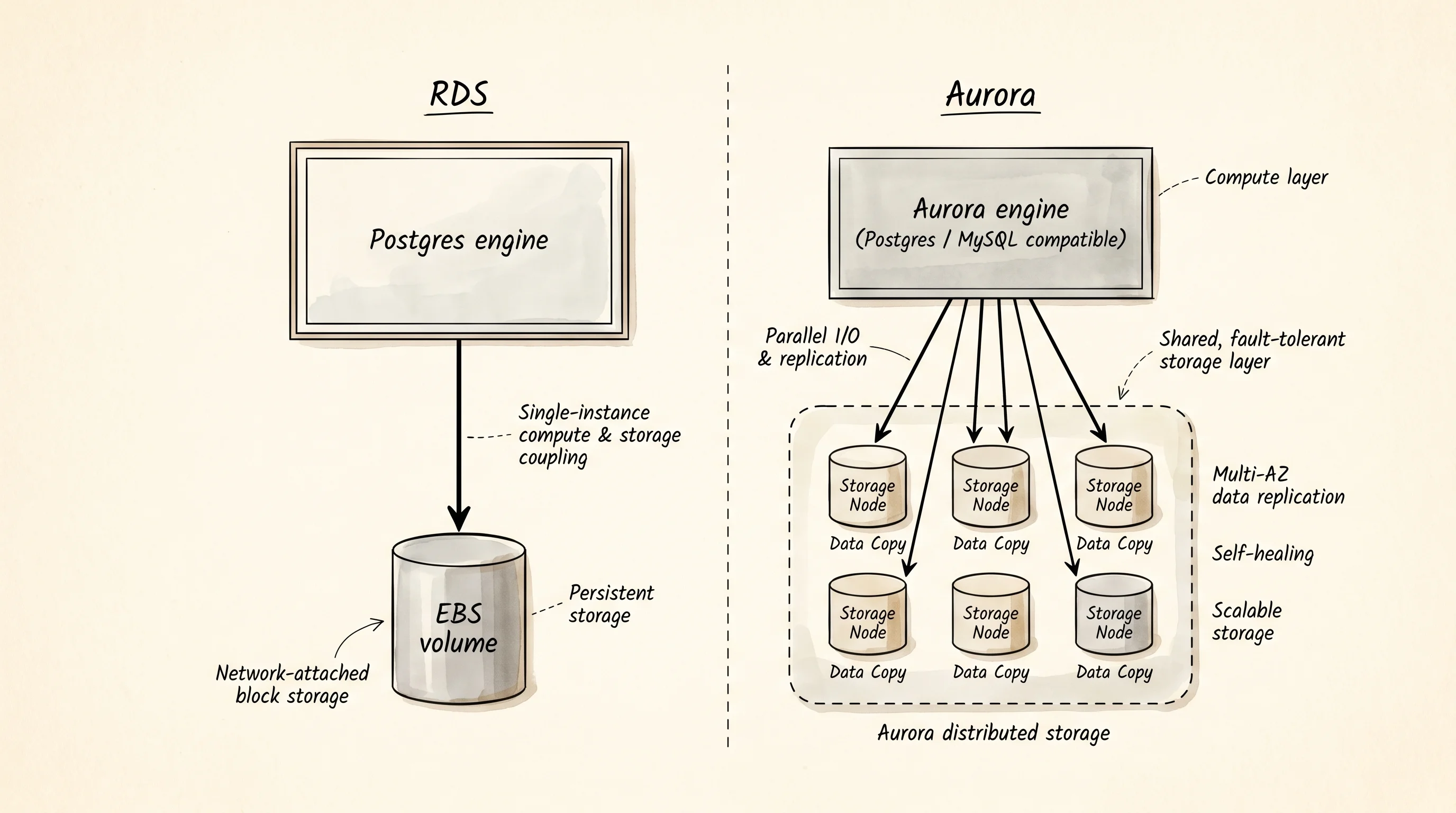
}Engine is an enum because a database is exactly one engine — never two — and the compiler will catch every spot that forgets a new case the day someone adds Oracle. The family method splits the engine into the two product lines AWS actually sells: RDS for the conventional engines and Aurora for the custom-built ones. The storage_copies method is the first hint that the two families are not the same thing under the hood. RDS keeps one copy of the storage (with EBS snapshots underneath for backup). Aurora keeps six. That number is not a typo.
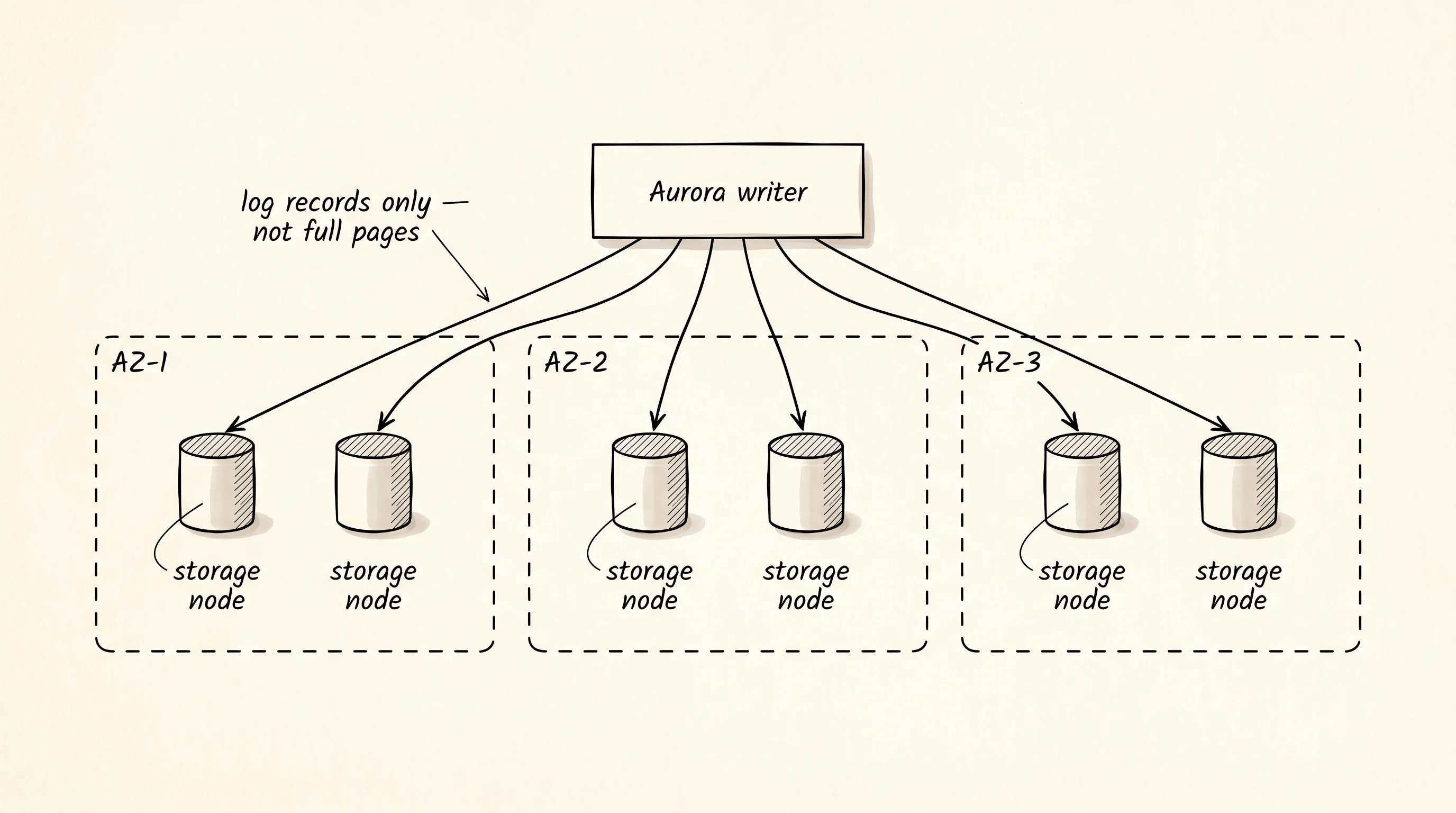
The reason Aurora exists at all is a story from 2014. Anurag Gupta and a small team inside AWS had spent a year watching how Postgres and MySQL actually ran on cloud hardware and decided the storage layer was the wrong shape for the new world. A conventional database writes its data, its write-ahead log, and the changed pages to disk — three round trips, all blocking, all assuming the disk is a local spinning platter that fails together. On AWS the disk is a network call to EBS and the platters are scattered across machines. So Aurora threw out the storage layer entirely. The query engine still speaks the Postgres or MySQL wire protocol — your application has no idea anything changed — but underneath it pushes only the log records over the network, and the storage tier (six copies across three availability zones) replays the log to rebuild the pages on demand. Writes go from three round trips to one. Failover, which used to mean replaying a write-ahead log on a cold standby, becomes a matter of pointing the writer endpoint at a node that already has the data.
Build the two deployments side by side and stamp them out as plain Rust values.
fn rds_postgres() -> DbInstance {
DbInstance {
name: "orders-db",
engine: Engine::Postgres,
size: "db.m6g.large",
multi_az: false,
read_replicas: Vec::new(),
}
}
fn aurora_mysql() -> DbInstance {
DbInstance {
name: "catalog-db",
engine: Engine::AuroraMySql,
size: "db.r6g.xlarge",
multi_az: true,
read_replicas: vec![
"catalog-db-reader-1".to_string(),
"catalog-db-reader-2".to_string(),
],
}
}The Postgres deployment is the simplest thing a team would stand up for an early app — single-AZ, no replicas, one stove in one building. The Aurora MySQL deployment is what a production catalog service looks like — multi-AZ for high availability, two read replicas to spread the SELECT traffic, sitting on top of Aurora's six-way distributed storage so any one AZ can disappear without losing data. Notice that read_replicas is a Vec<String> and not an array — the count is not known at compile time and grows with traffic.
fn print_topology(db: &DbInstance) {
println!("--- {} ---", db.name);
println!("family: {}", db.family());
println!("engine: {}", db.engine_name());
println!("size: {}", db.size);
println!("multi-az: {}", db.multi_az);
println!("storage: {}-way replicated", db.storage_copies());
if db.read_replicas.is_empty() {
println!("readers: none");
} else {
println!("readers: {}", db.read_replicas.len());
for (i, reader) in db.read_replicas.iter().enumerate() {
println!(" [{}] {}", i, reader);
}
}
println!();
}
fn show_types() {
println!("RDS = AWS hosts a normal database engine for you.");
println!("Aurora = AWS rewrote the storage layer under Postgres + MySQL.");
println!();
}
fn show_deployments() {
let pg = rds_postgres();
let aurora = aurora_mysql();
print_topology(&pg);
print_topology(&aurora);
}print_topology walks the fields and prints them. Reading it is the whole lesson in one page. Run the program and watch what the two deployments actually look like.
RDS = AWS hosts a normal database engine for you.
Aurora = AWS rewrote the storage layer under Postgres + MySQL.
--- orders-db ---
family: RDS
engine: PostgreSQL
size: db.m6g.large
multi-az: false
storage: 1-way replicated
readers: none
--- catalog-db ---
family: Aurora
engine: Aurora MySQL
size: db.r6g.xlarge
multi-az: true
storage: 6-way replicated
readers: 2
[0] catalog-db-reader-1
[1] catalog-db-reader-2
--- failover comparison ---
PostgreSQL (single-AZ) -> ~600s typical failover
PostgreSQL (multi-AZ) -> ~90s typical failover
Aurora MySQL (multi-AZ) -> ~30s typical failoverThe orders database is a single instance with one copy of its data — fine for a side project, scary for revenue. The catalog database is multi-AZ on Aurora with six copies of every block and two reader endpoints. Same shape of code, two very different reliability stories. The reason the read replicas matter is that an Aurora reader is not a separate copy of the data — every node shares the same distributed storage tier. Adding a reader is closer to spinning up another worker process that points at the same files than it is to bringing up a new database. That is why Aurora can scale reads to 15 replicas with almost no replication lag, while an RDS read replica is a full async copy that has to ship and replay binlog.
The other place the two families diverge is the failover time. RDS multi-AZ keeps a hot standby in another availability zone with synchronous block-level replication underneath. When the primary dies, RDS swings DNS over to the standby — typically a minute or two. Aurora swings the writer endpoint to a reader that already has every byte — typically under thirty seconds because there is no log to replay and no cold cache to warm.
fn failover_seconds(db: &DbInstance) -> u32 {
match db.family() {
"Aurora" => 30,
_ if db.multi_az => 90,
_ => 600,
}
}
fn show_failover() {
println!("--- failover comparison ---");
let pg = rds_postgres();
let aurora = aurora_mysql();
let multi_az_pg = DbInstance {
multi_az: true,
..rds_postgres()
};
for db in [&pg, &multi_az_pg, &aurora] {
println!(
"{:<24} -> ~{}s typical failover",
format!("{} ({})", db.engine_name(), if db.multi_az { "multi-AZ" } else { "single-AZ" }),
failover_seconds(db),
);
}
}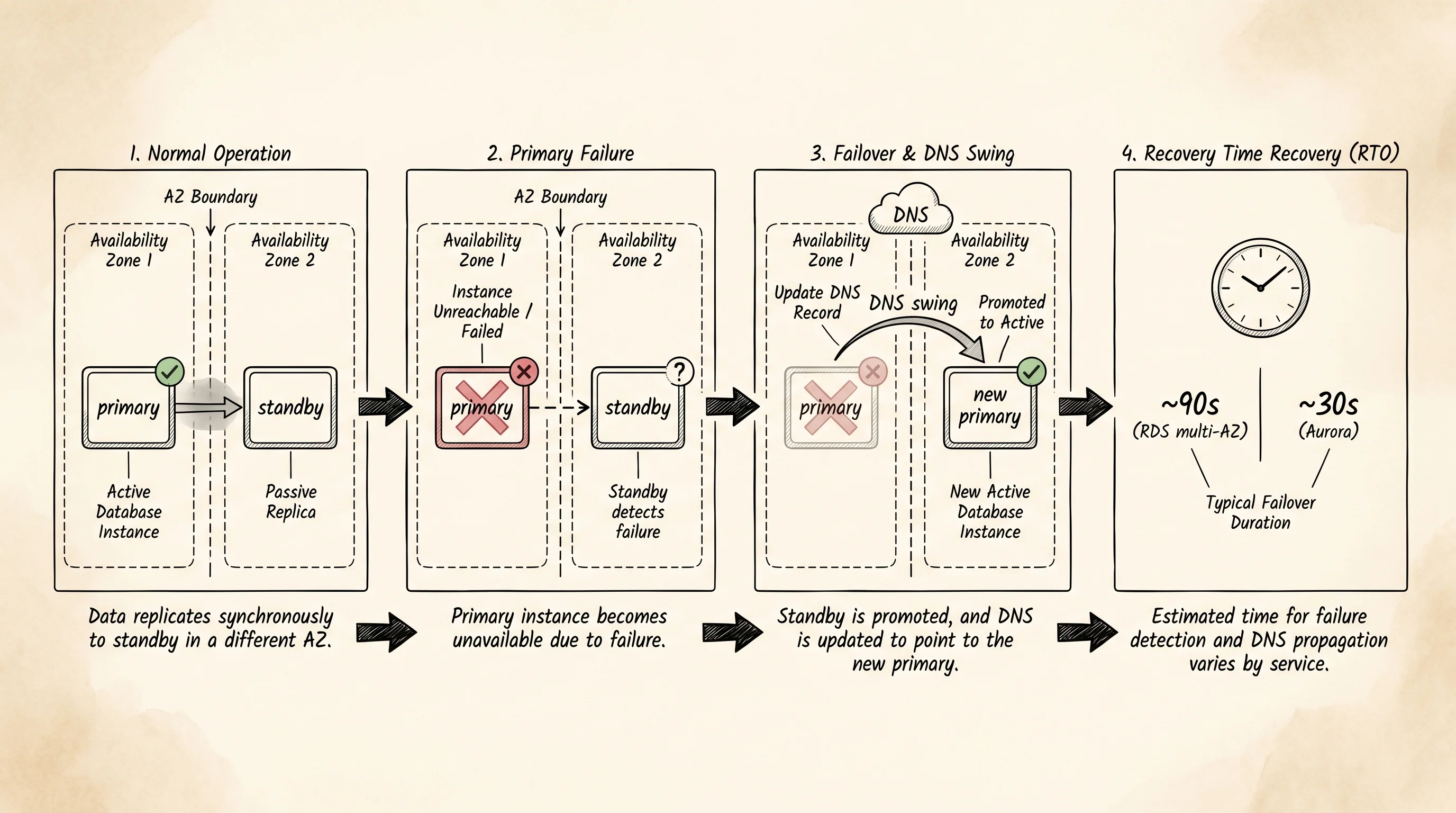
A single-AZ RDS instance has no automatic failover at all — if the box dies, the restore-from-backup procedure runs and the database is down for the length of the restore, which on a real workload is measured in tens of minutes. That row is in the output to make the cost of skipping multi-AZ honest. The reason teams still pick single-AZ for dev environments is the bill. Multi-AZ doubles the compute charge because there is a full standby instance running at all times. Aurora's six copies cost a flat 10 percent extra on storage instead, which is why the same team that runs single-AZ Postgres for staging will run multi-AZ Aurora MySQL for the catalog without thinking twice.
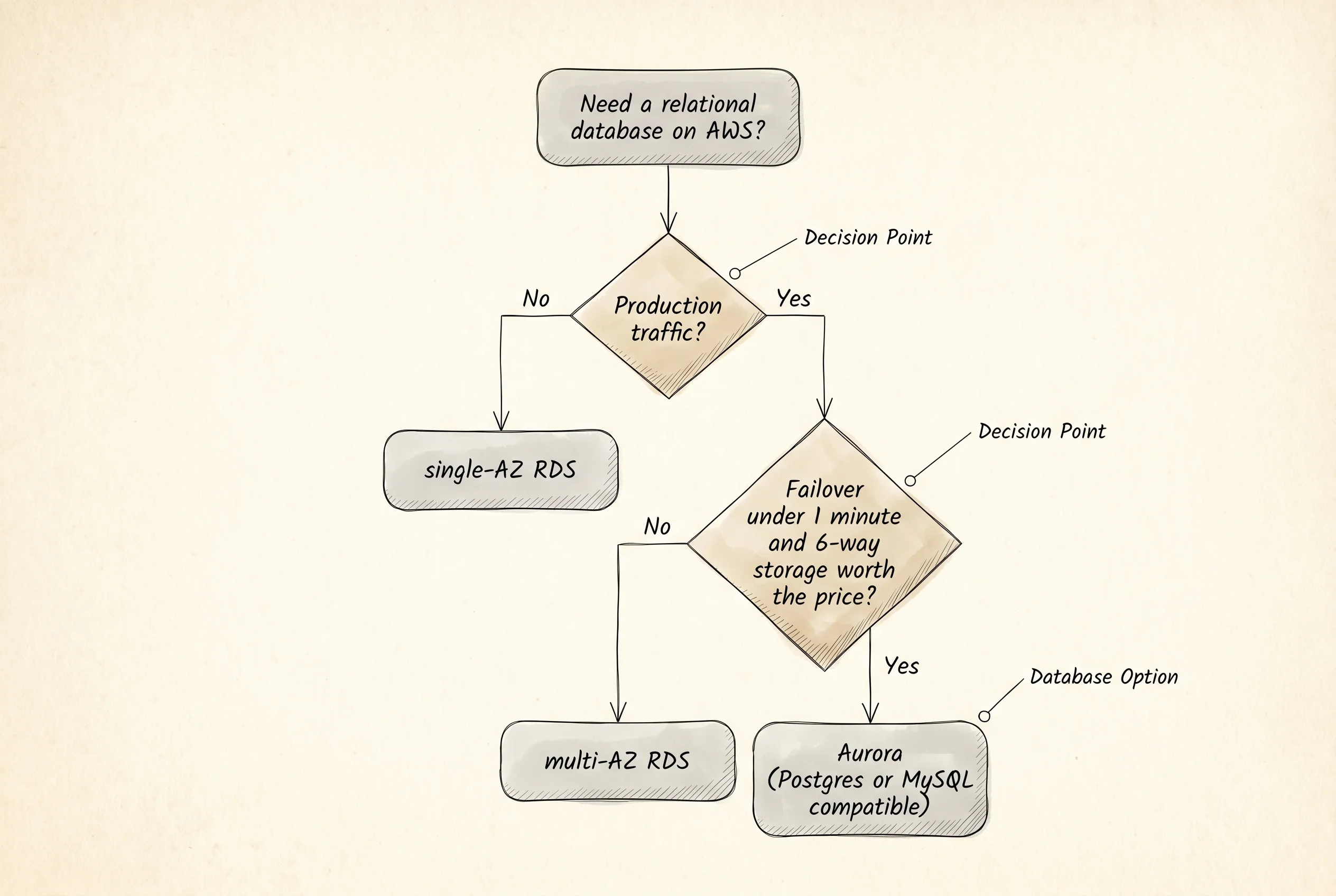
A question worth asking from the output — why does the Aurora MySQL row show 30 seconds when the multi-AZ Postgres row shows 90 seconds, even though both have a hot standby in another AZ? The answer is the storage layer. RDS multi-AZ has to flush the write-ahead log on the standby and warm the buffer cache before it can serve traffic. Aurora's standby is already reading from the same six-copy storage tier, so the moment the writer endpoint swings, the new writer is hot. Same wire protocol your app speaks. Completely different machine underneath.
The last piece worth naming is Aurora Serverless v2, which shipped in April 2022. It takes the same Aurora storage layer and puts an autoscaler in front of the compute, so the instance grows and shrinks in half-second steps based on actual load. The struct shape does not change — it is still an engine, a size, a multi_az flag — but size becomes a range like 0.5–32 ACU instead of a fixed db.r6g.xlarge. The cluster handles the rest.
What this design cannot do is escape the relational model. Every query still goes through SQL, every write still respects the schema, and adding a column to a table with 50 billion rows still rewrites those rows on disk somewhere. The next bottleneck is the workload that has billions of small key-value lookups and no need for joins at all — which is what DynamoDB exists to solve.