Sorting
Sorting is what a card player does between deals. Nine cards land in your hand in some accident of an order — 5, 2, 9, 1, 7, 3, 8, 4, 6 — and before the bidding starts you fan them out and slide each one into its place. The hand starts messy and ends in a clean run from low to high. A computer sorts the same way you do, except it has no fingers and no peripheral vision, so it has to follow a written rule for every move. That rule is the algorithm. Different rules give wildly different speeds, and the gap between the slow rule and the fast rule is the whole story of this lesson.
The reason sorting matters at all goes back to Herman Hollerith and the 1890 US census. The 1880 count had taken 8 years to tally by hand, and the country was growing so fast that the 1890 numbers risked landing after the 1900 census started. Hollerith built a machine that read holes punched in cardboard cards and physically sorted them into bins. His company became IBM, and for the next 60 years "sorting" meant feeding cards into a hopper and watching them fall into trays. When the first stored-program computers arrived in the late 1940s, the cards went away but the problem did not. John Mauchly, who co-built ENIAC, wrote up insertion sort in a 1946 lecture as one of the first algorithms anyone ever published. A year earlier John von Neumann had sketched merge sort in a draft report on the EDVAC. Those two algorithms — one slow and obvious, one clever and fast — are still the two ideas every sort in the standard library descends from.
The hardcoded hand for this lesson is a fixed array of 9 integers. Hard-coding it matters because the snapshot test on the bottom of the page checks every byte of stdout, and one shuffled order would make the test lie about which sort is faster. Print a label and the cards with a tiny helper so every algorithm shows its work the same way.
const INPUT: [i32; 9] = [5, 2, 9, 1, 7, 3, 8, 4, 6];
fn show(label: &str, deck: &[i32]) {
print!("{label:<14}");
for card in deck {
print!(" {card}");
}
println!();
}Insertion sort is the algorithm your hand already runs without thinking. Look at the second card. If it is smaller than the first, slide it left until the card to its left is smaller than it. Then look at the third card. Slide it left past every bigger card until it sits in its right place. Then the fourth. Then the fifth. Each pass extends the sorted run by one card. After 8 passes on a 9-card hand the whole thing is sorted, and the cost grows with the square of the hand size — double the cards, quadruple the work. That is what people mean by O(n squared).
fn insertion_sort(deck: &mut [i32]) {
for picked in 1..deck.len() {
let card = deck[picked];
let mut slot = picked;
while slot > 0 && deck[slot - 1] > card {
deck[slot] = deck[slot - 1];
slot -= 1;
}
deck[slot] = card;
show(&format!("after pass {picked}:"), deck);
}
}Read the inner while loop carefully. It does not swap two cards at a time. It picks up the card at position picked, slides every bigger card one slot to the right, and drops the picked card into the hole that opens up. That is exactly what your hand does — you do not swap, you slide a card sideways and drop the new one in. The show call at the end of each outer pass prints the hand after that card has settled, so the reader watches the sorted run grow from the left.

Merge sort is the algorithm a casino dealer would use if she had 8 helpers. Cut the hand in half. Cut each half in half. Keep cutting until every pile is a single card, which is already sorted with itself. Then merge two single-card piles into a 2-card sorted pile, two 2-card piles into a 4-card sorted pile, and so on back up. Each merge walks both input piles once, so each level of merging costs work proportional to the whole hand — but the number of levels is only the logarithm of the hand size. Nine cards take 4 levels. A thousand cards take 10. A million cards take 20. That is what people mean by O(n log n).
fn merge_sort(deck: &mut [i32]) {
let len = deck.len();
if len <= 1 {
return;
}
let mid = len / 2;
let mut left = deck[..mid].to_vec();
let mut right = deck[mid..].to_vec();
merge_sort(&mut left);
merge_sort(&mut right);
merge_into(deck, &left, &right);
show(&format!("merged size {len}:"), deck);
}
fn merge_into(out: &mut [i32], left: &[i32], right: &[i32]) {
let mut li = 0;
let mut ri = 0;
let mut oi = 0;
while li < left.len() && ri < right.len() {
if left[li] <= right[ri] {
out[oi] = left[li];
li += 1;
} else {
out[oi] = right[ri];
ri += 1;
}
oi += 1;
}
while li < left.len() {
out[oi] = left[li];
li += 1;
oi += 1;
}
while ri < right.len() {
out[oi] = right[ri];
ri += 1;
oi += 1;
}
}The recursion is the trick. merge_sort calls itself on the left half and the right half before doing any merging, so by the time merge_into runs, both inputs are already sorted. The merge itself is a zipper — peek at the front of each pile, take the smaller one, repeat until one pile is empty, then dump the rest. Notice that merge_sort allocates a fresh Vec for each half on the way down. A production implementation would reuse one scratch buffer, but the goal here is to see the algorithm, not race the standard library.
The output below shows both sorts walking through the same starting hand. Read the insertion block top to bottom and you can watch a single card travel left on each pass — the 1 jumps from position 3 to position 0 on pass 3, the 3 jumps from position 5 to position 2 on pass 5. The merge block reads bottom up — the two-card piles get merged first, then the four-card pile, then the nine-card pile that holds the whole answer.
-- insertion sort: walking left to right --
start: 5 2 9 1 7 3 8 4 6
after pass 1: 2 5 9 1 7 3 8 4 6
after pass 2: 2 5 9 1 7 3 8 4 6
after pass 3: 1 2 5 9 7 3 8 4 6
after pass 4: 1 2 5 7 9 3 8 4 6
after pass 5: 1 2 3 5 7 9 8 4 6
after pass 6: 1 2 3 5 7 8 9 4 6
after pass 7: 1 2 3 4 5 7 8 9 6
after pass 8: 1 2 3 4 5 6 7 8 9
done: 1 2 3 4 5 6 7 8 9
-- merge sort: split, sort halves, merge --
start: 5 2 9 1 7 3 8 4 6
merged size 2: 2 5
merged size 2: 1 9
merged size 4: 1 2 5 9
merged size 2: 3 7
merged size 2: 4 6
merged size 3: 4 6 8
merged size 5: 3 4 6 7 8
merged size 9: 1 2 3 4 5 6 7 8 9
done: 1 2 3 4 5 6 7 8 9
-- stdlib for comparison --
start: 5 2 9 1 7 3 8 4 6
sort: 1 2 3 4 5 6 7 8 9
sort_unstable: 1 2 3 4 5 6 7 8 9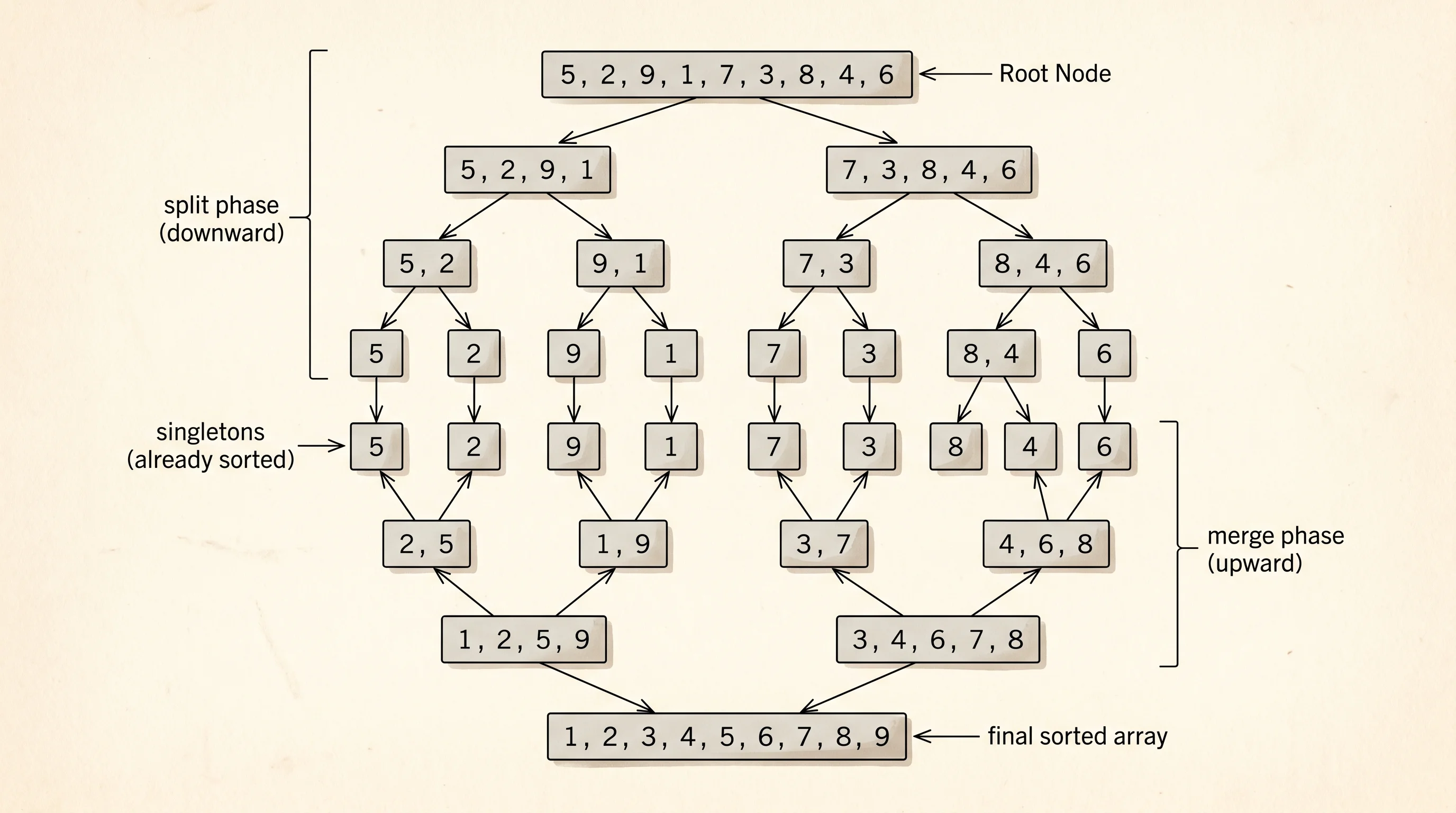
Count the lines in each block. Insertion took 8 passes. Merge took 8 merges, but each merge does less work than the slowest insertion pass. The gap looks small on 9 cards. On a million cards the insertion version does roughly a trillion compare-and-slide operations, while the merge version does roughly 20 million. That is the difference between a sort that finishes before lunch and one that finishes next week.
You will not actually write either of these in real Rust code. The standard library ships slice::sort, which is a Timsort variant that Tim Peters wrote for Python in 2002 — it spots already-sorted runs in your input and stitches them together with merges. It also ships slice::sort_unstable, which is a Pattern-Defeating Quicksort that the Rust team adopted in 2018 because it handled adversarial inputs better than the textbook quicksort. Both ship in stdlib. Both beat anything you would write by hand.
fn stdlib_sorts() {
let mut timsort = INPUT.to_vec();
timsort.sort();
show("sort:", &timsort);
let mut pdq = INPUT.to_vec();
pdq.sort_unstable();
show("sort_unstable:", &pdq);
}The bottom of the output shows both standard library sorts landing on the same answer as the hand-written ones, in one line each. You would only ever write a sort yourself for one of three reasons — a constrained embedded target that has no allocator, a teaching exercise like this one, or a specialized comparison rule that the trait system makes awkward to express. Otherwise the right move is .sort() and move on.
What this lesson cannot tell you is whether your sort is actually fast enough for the data you have. A sort that finishes in a microsecond on 9 items might take 3 seconds on 9 million items, and the only way to know which side of the line you are on is to time it. The next lesson is about measuring algorithms in microseconds across input sizes, which is the only honest way to pick between two sorts that both finish.